分散式架構演變歷史
一。分散式架構的發展史
1946年情人節世界上第一臺電子數字計算機誕生在美國賓夕法尼亞大學,他的名字是ENIAC。這臺計算機佔地170平米,重達30噸,每秒可進行5000次加法運算。
第一臺計算機的誕生,標誌著一個新的it時代到來,一方面計算機的效能每年都在提升,從最早的8位CPU到現在的64位。從早期的MB到現在的GB級別記憶體,從慢速的機械式硬碟到現在的固態SSD硬碟。
馮諾依曼模型

ENIAC之後,計算機便進入IBM主導的時代,IBM大型機之父吉恩.阿姆達爾被認為是有史以來最偉大的計算機設計師之一。
20世紀80年代,在大型機霸主的時代,計算機架構同事向兩個方向發展
1,以CICS(微型處理執行的計算機語言指令)CPU為架構的價格便宜的面向個人的pc
2, 以RISC(精簡指令集計算機)CPU為架構的價格昂貴的面相企業的小型unix伺服器
二。分散式架構發展的里程碑
大型機的出現,憑藉著大型機超強的計算和I/O處理能力,穩定性,安全性等,在很長的一段時間內,大型機都是引領計算機行業及商業計算領域的發展。而集中式系統架構也成主流。隨著計算機的發展,這種架構越來越難以適應人們的需求。
比如:
1. 由於大型機的複雜型,導致培養一個熟練運維的大型機的人成本很高
2. 大型機很貴,一般只有 政府 金融 電信等行業才能用的起
3.單點問題, 一臺大型主機出現故障,那麼整個系統都處於崩潰狀態,這種不可能導致的損失是非常大的。
4. 科技進步,pc機效能越來越好,很多企業放棄使用大型機改用小型機及普通PC來搭建系統架構。
例如: 阿里巴巴在2009年的去“IOE”運動
IEO 是指 IBM小型機,Oracle 資料庫,EMC的高階儲存,2009年去“IOE”戰略透漏,到2013年5月17日最後的IBM小型機在支付寶下線。
為什麼要去IOE?
採用Oracle資料庫,並利用小型機和高階儲存裝置提供高效能的資料處理和儲存服務,隨著業務的發展,資料量不斷的增長,傳統的集中式架構方式在擴充套件效能方面遭遇瓶頸。
傳統的商業資料庫,多以集中式架構為主。這些傳統的資料庫最大的特點就是 集中,將所有的資料都儲存在一個數據庫中。依靠裝置的效能來提供高效能處理和計算。集中式資料庫在擴充套件上主要採用向上擴充套件的方式,通過增加CPU和記憶體,磁碟等方式提高處理能力,這種集中式的資料庫架構,使得資料庫成為了整個系統的瓶頸,已經越來越不適應海量資料對計算能力的巨大需求。
三。 分散式系統的意義
1.升級單機處理能力的價效比越來越低,單機的處理能力主要依靠CPU 記憶體,磁碟 通過更換硬體做垂直擴充套件的方式來提升新能,成本越來越高
2,單機處理能力存在瓶頸
3, 單機架構的穩定性和可用性兩個指標很難達到。
四。分散式架構系統的演變
一個成熟的系統並不是一開始就設計的非常完善,也不是一開始就具有高效能,高可用,安全性等特性,而是隨著使用者的增加和業務功能的擴充套件逐步完善。在這過程中 開發模式,技術架構都會發生重大變化,而針對不同業務特徵的系統會有各自的側重點,像淘寶這類網站要解決的事海量商品搜尋 下單支付等問題。像騰訊 要解決數億級別使用者的實施訊息傳輸等。每種業務都有自己不同的系統架構。
以Java Web 為例 搭建簡單的電商系統,從系統來看系統演變的歷史,要注意的是 接下來模型的演示。關注資料量 訪問量,網站結構的變化。
加入系統具備功能: 使用者,商品 交易
最初始階段,單體架構:
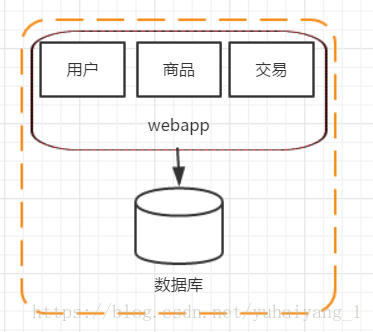
網站的初期,經常在單機上跑所有的程式,把所有的軟體和應用部署在同一臺機子上,這樣就完成了一個簡單系統的搭建。初期講究的事效率。
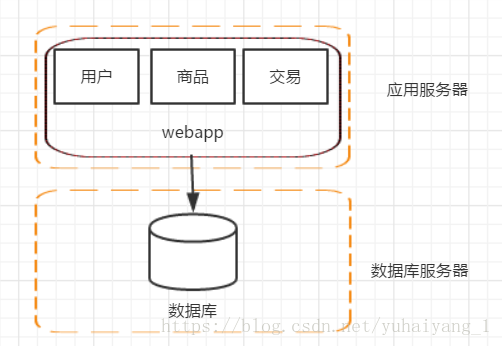
階段二。 應用伺服器和資料庫伺服器分離
隨著網站的上線,訪問量的增加,伺服器負載變高。在伺服器還沒有超載的時候,重新規劃,提上網站效能,加入程式碼層面已經沒辦法提升了,在不提高單臺機子效能下,增加機子是一個比較好的方式,投入產出比非常高,在這個階段把web伺服器和資料庫伺服器分開,這樣不僅提高單機負載,也能提高容災能力
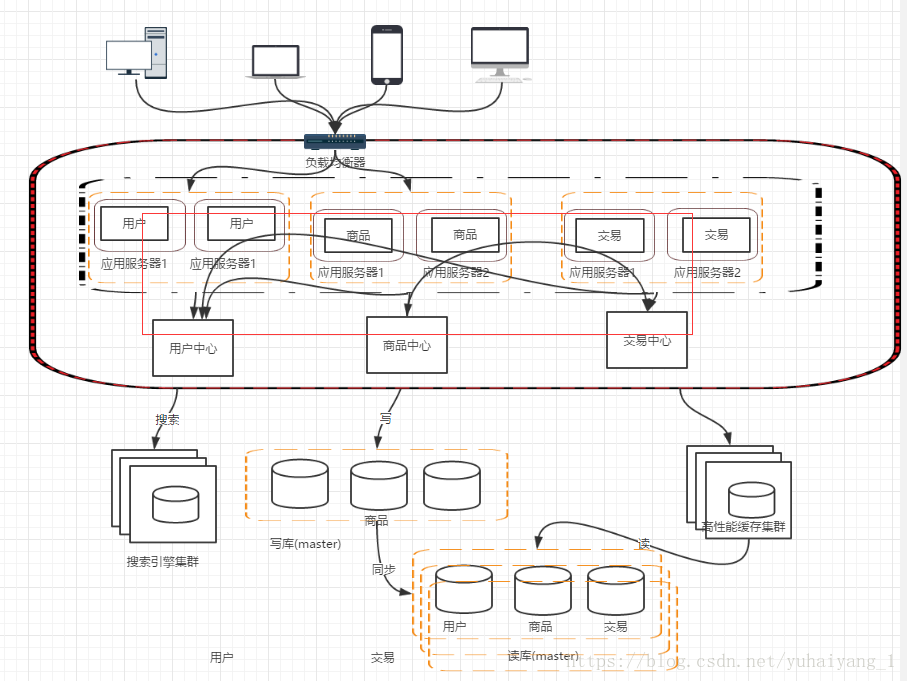
階段三 應用伺服器叢集,應用伺服器負載吃緊。
隨著時間推移,網站訪問量繼續增加,單臺伺服器已經無法滿足需求,假如資料庫伺服器沒有達到瓶頸,我們可以增加應用伺服器,通過應用伺服器叢集將使用者的請求分流到各個伺服器上,從而提高負載能力。此時伺服器間沒有直接互動,都是通過資料庫各自對外互動

系統架構演變到此階段,新的問題慢慢也會出現
1. 使用者請求誰來轉發,如何轉發?
2. 使用者每次方位到的伺服器不一樣,那麼session如何處理?

階段四,資料庫壓力變大, 資料庫實行讀寫分離
架構演變到這裡並不是終點。我們通過上面的方式把應用層的效能提升了,但是資料庫的負載過大,且單點安全問題,怎麼提高資料庫效能,且保證安全,有了前面的思路 我們照貓畫虎。 但是假如我們單純的把資料庫一分為二,然後對於資料庫請求,分別負載到兩臺機子上, 那麼新的問題又來了,資料庫資料不統一的問題,所以我們先採用讀寫分離的方式
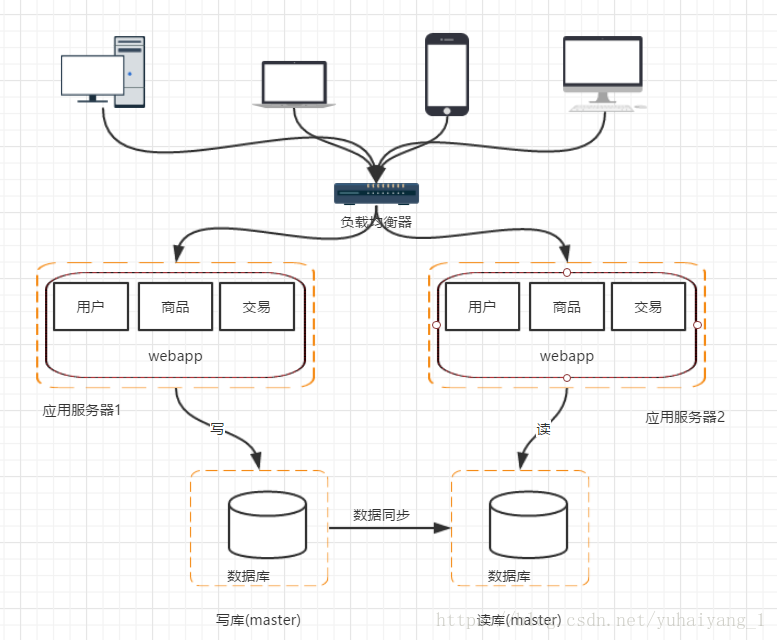
這個新的架構又要面臨新的問題和挑戰
1, 主從資料庫之間資料同步, 可以使用mysql自帶的 master-slave 方式實現主從
2, 因對資料來源的選擇,採用第三方資料庫中介軟體 例如 mycat
階段五 使用搜索引擎環節度資料庫的壓力
資料庫做讀庫的話,嘗試對模糊查詢效率並不好,像電商類的網站搜尋是非常核心的功能,幾遍做了讀寫分離這個問題也不能有效解決,那麼這個時候就需要引入搜尋引擎,使用搜索引擎能大大提高查詢效率,但同時也有問題,比如索引的維護
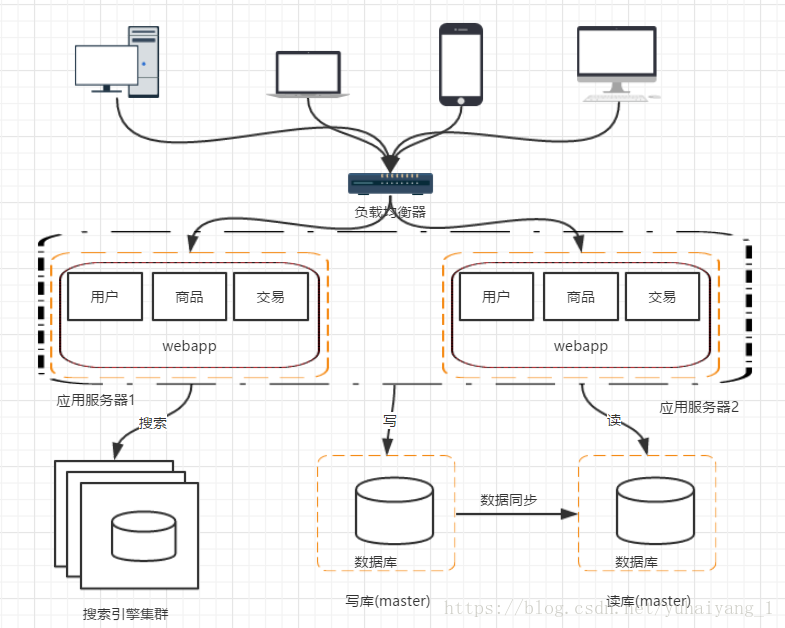
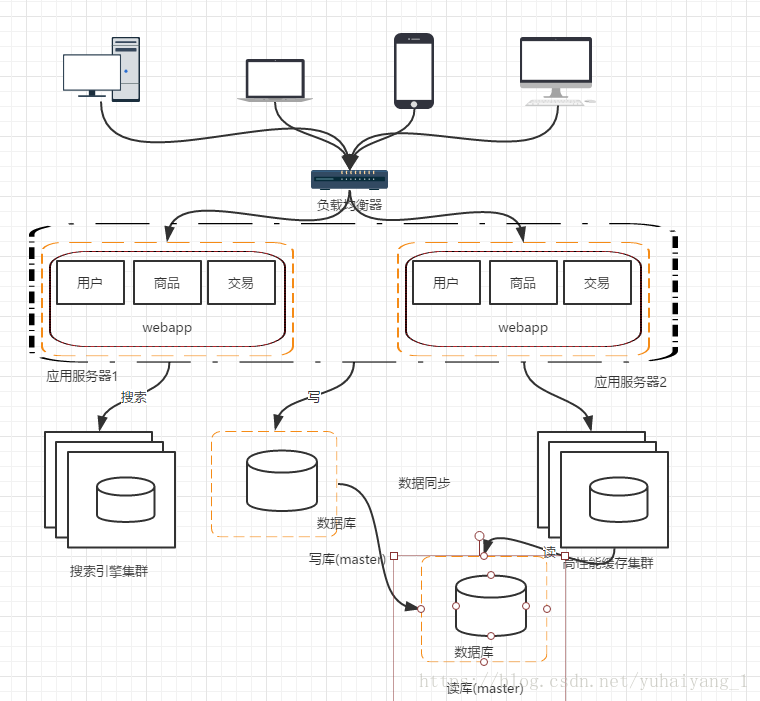
階段六 引入快取機制環節資料庫壓力(比如熱點資料 )
隨著訪問量的持續增加,逐漸出現許多使用者訪問同一部分資料的情況,對這些熱點資料沒必要每次都查詢資料庫,我們可以使用快取技術比如 memcache redis 來作為應用層快取,另外某些場景下 我們對使用者的某些ip的訪問頻率做限制,那麼放在記憶體中又不合適,放在資料庫總太麻煩,這時候可以使用NoSql的方式比如 mongDB來代替傳統資料庫

階段七, 資料庫的水平和垂直拆分
網站演進的過程中, 使用者 商品 交易的資料還在同一個資料庫中,儘管採取了 快取 讀寫分離的方式,但是資料庫的壓力持續增加,資料庫的瓶頸仍是一個很大的問題,因此我們考慮對資料垂直拆分和水平拆分
垂直拆分: 把資料庫中不同業務資料拆分到不同的資料庫中
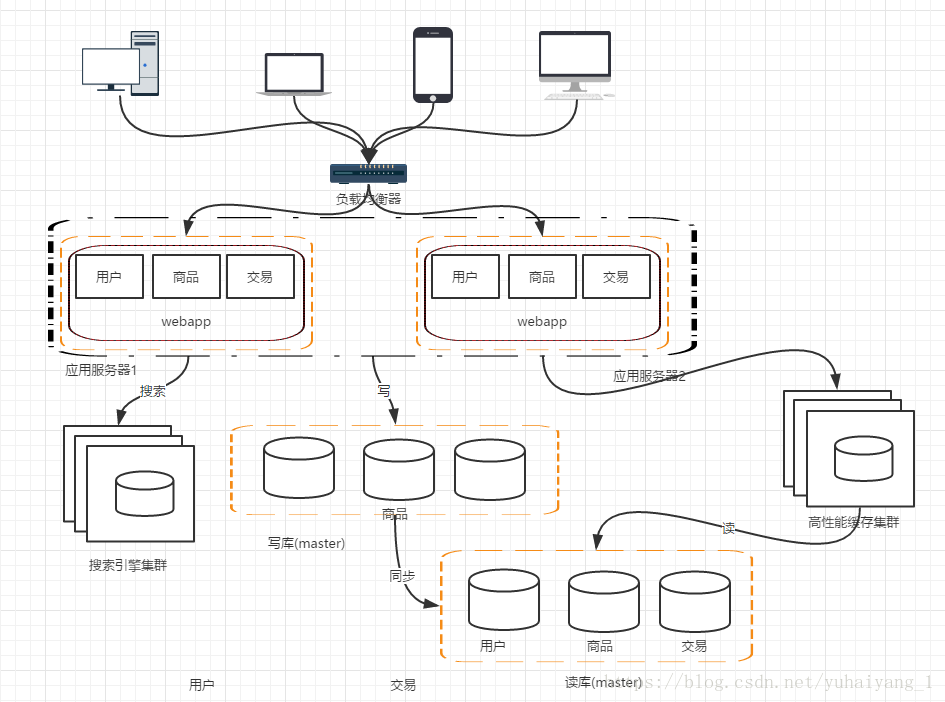
水平拆分: 把同一個表中的資料拆分到兩個甚至更多的資料庫中,水平拆分的原因 某些業務資料量已經達到單個數據庫瓶頸,這時還可以採取拆分表到多個數據庫中
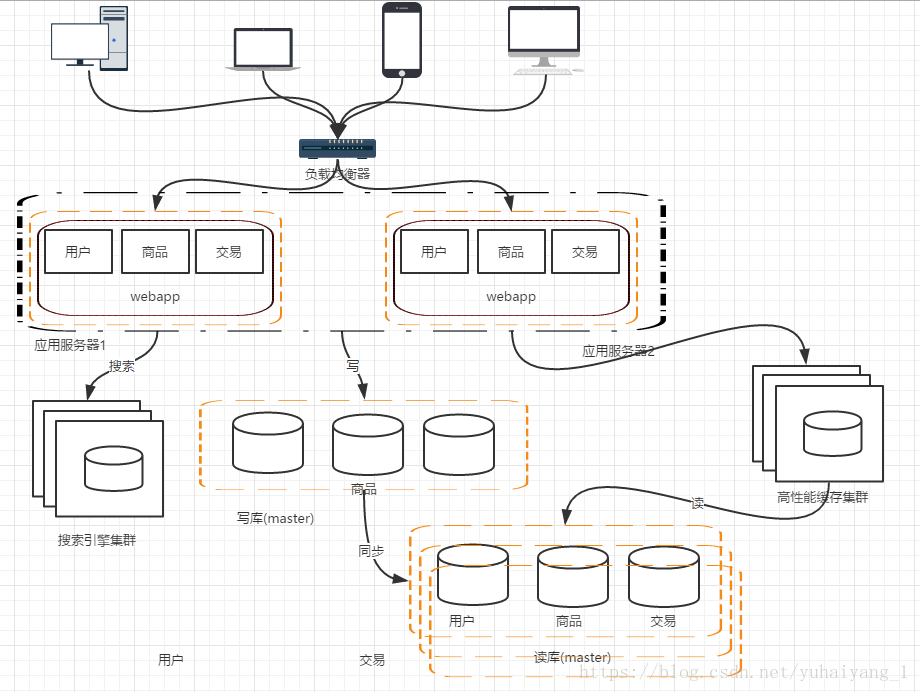
階段八 應用拆分
隨著業務的發展,越來多應用壓力大。工程規模 隨著業務的發展,越來多應用壓力大。。這個時候就可以考慮講 應用拆分,按照領域模型我們的使用者、商品交易拆分成多個子系統 我們的使用者、商品交易拆分成多個子系統

這樣拆分後,可能會有一些相同的程式碼,如 使用者操作,商品查詢等, 所以會導致每個系統都會有使用者查詢訪問相關操作,這些相同的操作一定要抽離出來,否者就是坑,所有通過走服務化方式解決

那麼服務拆分後,各個服務之間如何通訊,通過RPC技術 ,比如 webservice hessian http RMI 等等
前期通過這些技術很好的解決問題,但是網際網路的發展是持續不斷地,所以架構演變和優化還在繼續。。。