
Linux 安裝以及基本使用Hadoop 詳解
阿新 • • 發佈:2019-01-07
1> 解壓軟體到目錄
$ tar -zxf hadoop-2.5.0.tar.gz -C /opt/modules
2> 刪除 hadoop 中的 share/doc 目錄,該目錄中存放著Hadoop相關文件用的比較少,佔用空間有幾G且會影響 hadoop 編譯
$ cd share
$ rm -rf ./doc/
3> 設定 Java 安裝目錄
使用遠端編輯軟體 進入到 modules/hadoop-2.5.0/etc/hadoop
<1> 編輯 $HADOOP_HOME/etc/hadoop/hadoop-env.sh 檔案
將檔案中 export JAVA_HOME=${JAVA_HOME} 的 ${JAVA_HOME} 替換成Java目錄,使用指令 #
echo ${JAVA_HOME} 

<2> 編輯 $HADOOP_HOME/etc/hadoop/mapred-env.sh 檔案 設定 JAVA_HOME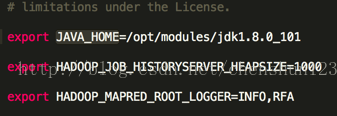
<3> 編輯 $HADOOP_HOME/etc/hadoop/yarn-env.sh 檔案 設定 JAVA_HOME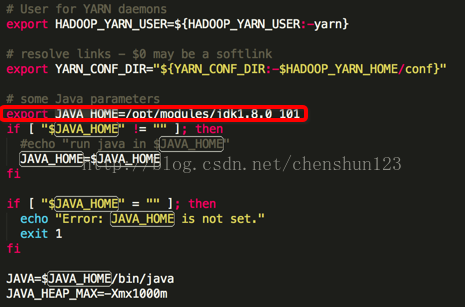
4> 配置 *-site.xml 自定義檔案 使用遠端編輯軟體 進入到 modules/hadoop-2.5.0/etc/hadoop <1> 編輯 $HADOOP_HOME/etc/hadoop/core-site.sh 檔案,指定namenode主節點所在的位置以及互動埠號,設定本機ip地址,使用 $ hostname 檢視 <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-senior01:8020</value> </property>
注 : 互動的埠號可以修改,由於 apache 一般使用 80 埠號因此此處設定預設埠號 80 開頭 fs.defaultFS 預設存放在本地

<2> 修改 hadoop.tmp.dir 的預設臨時路徑 在 hadoop 跟目錄下建立 data/tmp 目錄 $ mkdir -p data/tmp 編輯 $HADOOP_HOME/etc/hadoop/core-site.sh 檔案,增加如下資訊 <property> <name>hadoop.tmp.dir</name> <value>/opt/modules/hadoop-2.5.0/data/tmp</value> </property>
hadoop.tmp.dir 是預設臨時路徑,預設在快取目錄,會被清理掉因此需要修改路徑

<3> 指定 datanode 從節點所在的位置 編輯 slaves 檔案,使用 $hostname 檢視機器地址,並設定到檔案中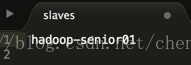
注:slaves 既代表 datanode 又代表 namenode <4> 指定副本個數 編輯 $HADOOP_HOME/etc/hadoop/hdfs-site.sh 檔案 <property> <name>dfs.replication</name> <value>1</value> </property>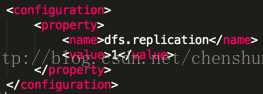
5> 對於NameNode進行格式化操作 $ bin/hdfs namenode -format 注:1> 在 hadoop 根目錄中使用 $ bin/hdfs 指令檢視所有指令 2> 只需要一次格式化,多次格式化會出錯 6> 啟動相關的服務程序 $ sbin/hadoop-daemon.sh start namenode $ sbin/hadoop-daemon.sh start datanode 注:使用 $jps 檢視執行的相關程序 對於HDFS檔案系統進行讀寫上傳下載測試: $ bin/hdfs dfs -mkdir -p tmp/conf // 建立目錄 $ bin/hdfs dfs -put etc/hadoop/core-site.xml /user/chenshun/tmp/conf // 上傳檔案 $ bin/hdfs dfs -cat /user/chenshun/tmp/conf/core-site.xml // 檢視檔案 $ bin/hdfs dfs -get /user/chenshun/tmp/conf/core-site.xml /home/chenshun/cs-site.xml // 下載檔案 注 : hdfs也存在使用者注目錄的概念 報錯要首先去看日誌檔案的報錯資訊 > hadoop-2.5.0/logs/檢視具體的日誌檔案 > 檢視以 .log 結尾的檔案 使用 more 指令檢視檔案 7> reduce獲取資料的方式 編輯 $HADOOP_HOME/etc/hadoop/yarn-site.xml 檔案,增加如下資訊 <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>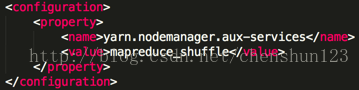
指定ResourceManager的位置,可配可不配 <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-senior01</value> </property>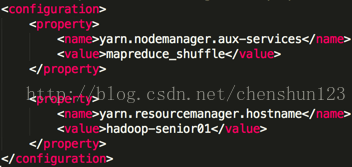
8> 指定 MapReduce 執行在 YARN 上 進入到 $HADOOP_HOME/etc/hadoop/ 將 mapred-site.xml.template 重新命名為 mapred-site.xml,編輯該檔案增加 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>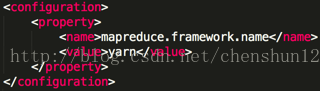
在主目錄下執行如下指令執行 yarn $ sbin/yarn-daemon.sh start resourcemanager $ sbin/yarn-daemon.sh start nodemanager
YARN:分散式資源管理框架 管理整個叢集的資源(記憶體、CPU核數) 分配排程叢集的資源 MapReduce程式打成jar包執行在YARN上 $ bin/hdfs dfs -mkdir -p /user/chenshun/mapreduce/wordcount/input // 建立輸入目錄 $ bin/hdfs dfs -put data/tmp/wc.input /user/chenshun/mapreduce/wordcount/input // 上傳檔案到目錄中 $ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/chenshun/mapreduce/wordcount/input /user/chenshun/mapreduce/wordcount/output // 打包執行(每次執行輸出路徑都不能相同) 察看結果 $ bin/hdfs dfs -cat /user/chenshun/mapreduce/wordcount/output/part* // 察看文字結果 $ bin/hdfs dfs -text /user/chenshun/mapreduce/wordcount/output/part* // 推薦使用,能轉換成文字在檢視 9> 日誌檔案 (1)啟動日誌檔案目錄 $HADOOP_HOME/logs (2)分析日誌檔案格式 log 和 out .log:通過 log4j 記錄的,記錄大部分應用程式的日誌資訊 .out:記錄標準輸出和標準錯誤日誌,少量記錄 (3)日誌檔案的命名規則:框架名稱-使用者名稱-程序名-主機名-日誌格式字尾 歷史伺服器 historyServer : 檢視已經完成的歷史作業記錄 編輯 $HADOOP_HOME/etc/hadoop/mapred-site.xml 檔案增加,注可配可不配 <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-senior01:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-senior01:19888</value> </property>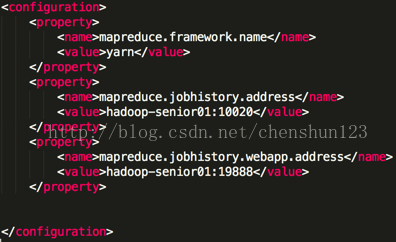
啟動歷史伺服器 $ sbin/mr-jobhistory-daemon.sh start historyserver 將 mapreduce 產生的日誌檔案上傳到 HDFS 檔案系統上,就可以從頁面上檢視日誌檔案 編輯 $HADOOP_HOME/etc/hadoop/yarn-site.xml 檔案增加 <1> 指定是否開啟日誌聚集功能,預設為 false <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <2> 設定日誌在HDFS上保留的時間期限 <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property>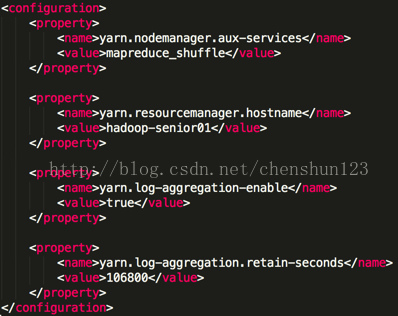
配置完成之後,需要重啟YARN的服務程序,然後重新跑一次任務就可以檢視過往的日誌資訊,historyserver同樣也要重啟 $ sbin/yarn-daemon.sh stop resourcemanager $ sbin/yarn-daemon.sh stop nodemanager $ sbin/mr-jobhistory-daemon.sh stop historyserver $ sbin/yarn-daemon.sh start resourcemanager $ sbin/yarn-daemon.sh start nodemanager $ sbin/mr-jobhistory-daemon.sh start historyserver $ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/chenshun/mapreduce/wordcount/input /user/chenshun/mapreduce/wordcount/output3 11> HDFS檔案許可權檢測 <1> 設定不啟用HDFS檔案系統的許可權檢查,預設為 true 編輯 $HADOOP_HOME/etc/hadoop/hdfs-site.xml 檔案增加 <property> <name>dfs.permissions.enabled</name> <value>false</value> </property>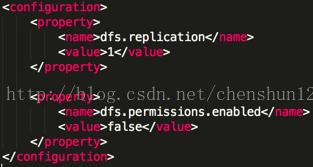
<2> 指定修改 Hadoop靜態使用者名稱,預設是 dr.who 編輯 $HADOOP_HOME/etc/hadoop/core-site.xml 檔案增加 <property> <name>hadoop.http.staticuser.user</name> <value>chenshun</value> </property>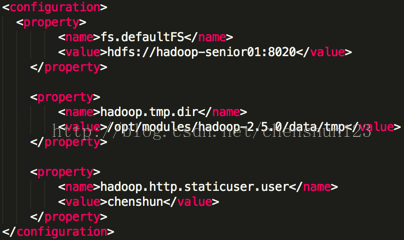
配置之後需要重啟HDFS相關的程序 $ sbin/hadoop-daemon.sh stop namenode $ sbin/hadoop-daemon.sh stop datanode $ sbin/mr-jobhistory-daemon.sh stop historyserver $ sbin/yarn-daemon.sh stop resourcemanager $ sbin/yarn-daemon.sh stop nodemanager $ sbin/hadoop-daemon.sh start namenode $ sbin/hadoop-daemon.sh start datanode $ sbin/mr-jobhistory-daemon.sh start historyserver $ sbin/yarn-daemon.sh start resourcemanager $ sbin/yarn-daemon.sh start nodemanager 常見錯誤 1> 格式化錯誤 2> 叢集 id 不一致 注:建議不要切換多使用者去操作,否則將會出現異常錯誤 經常出現的警告 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 在 $HADOOP_HOME/lib/native 目錄中,不能獲取編譯者在什麼系統上進行編譯的,所以會導致版本不一致,無法載入本地庫 解決方法,直接替換改庫到指定版本: $ cd /opt/softwares/ $ tar -zxf native-2.5.0.tar.gz -C /opt/modules/ $ cd /opt/modules/hadoop-2.5.0/lib $ mv native/ back_native $ cp -r /opt/modules/native/ /opt/modules/hadoop-2.5.0/lib 在 $HADOOP_HOME 中執行如下指令就不會出現警告 $ bin/hdfs dfs -ls / 12> Hadoop配置檔案 1、分為兩類:預設配置檔案、自定義配置檔案 2、第一步載入預設配置檔案 3、第二步載入自定義配置檔案 4、優先順序:自定義的檔案優先順序高於預設配置檔案 HDFS core-default -site hdfs-default -site 服務端server 客戶端client
<2> 編輯 $HADOOP_HOME/etc/hadoop/mapred-env.sh 檔案 設定 JAVA_HOME
<3> 編輯 $HADOOP_HOME/etc/hadoop/yarn-env.sh 檔案 設定 JAVA_HOME
4> 配置 *-site.xml 自定義檔案 使用遠端編輯軟體 進入到 modules/hadoop-2.5.0/etc/hadoop <1> 編輯 $HADOOP_HOME/etc/hadoop/core-site.sh 檔案,指定namenode主節點所在的位置以及互動埠號,設定本機ip地址,使用 $ hostname 檢視 <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-senior01:8020</value> </property>
注 : 互動的埠號可以修改,由於 apache 一般使用 80 埠號因此此處設定預設埠號 80 開頭 fs.defaultFS 預設存放在本地
<2> 修改 hadoop.tmp.dir 的預設臨時路徑 在 hadoop 跟目錄下建立 data/tmp 目錄 $ mkdir -p data/tmp 編輯 $HADOOP_HOME/etc/hadoop/core-site.sh 檔案,增加如下資訊 <property> <name>hadoop.tmp.dir</name> <value>/opt/modules/hadoop-2.5.0/data/tmp</value> </property>
hadoop.tmp.dir 是預設臨時路徑,預設在快取目錄,會被清理掉因此需要修改路徑
<3> 指定 datanode 從節點所在的位置 編輯 slaves 檔案,使用 $hostname 檢視機器地址,並設定到檔案中
注:slaves 既代表 datanode 又代表 namenode <4> 指定副本個數 編輯 $HADOOP_HOME/etc/hadoop/hdfs-site.sh 檔案 <property> <name>dfs.replication</name> <value>1</value> </property>
5> 對於NameNode進行格式化操作 $ bin/hdfs namenode -format 注:1> 在 hadoop 根目錄中使用 $ bin/hdfs 指令檢視所有指令 2> 只需要一次格式化,多次格式化會出錯 6> 啟動相關的服務程序 $ sbin/hadoop-daemon.sh start namenode $ sbin/hadoop-daemon.sh start datanode 注:使用 $jps 檢視執行的相關程序 對於HDFS檔案系統進行讀寫上傳下載測試: $ bin/hdfs dfs -mkdir -p tmp/conf // 建立目錄 $ bin/hdfs dfs -put etc/hadoop/core-site.xml /user/chenshun/tmp/conf // 上傳檔案 $ bin/hdfs dfs -cat /user/chenshun/tmp/conf/core-site.xml // 檢視檔案 $ bin/hdfs dfs -get /user/chenshun/tmp/conf/core-site.xml /home/chenshun/cs-site.xml // 下載檔案 注 : hdfs也存在使用者注目錄的概念 報錯要首先去看日誌檔案的報錯資訊 > hadoop-2.5.0/logs/檢視具體的日誌檔案 > 檢視以 .log 結尾的檔案 使用 more 指令檢視檔案 7> reduce獲取資料的方式 編輯 $HADOOP_HOME/etc/hadoop/yarn-site.xml 檔案,增加如下資訊 <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
指定ResourceManager的位置,可配可不配 <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-senior01</value> </property>
8> 指定 MapReduce 執行在 YARN 上 進入到 $HADOOP_HOME/etc/hadoop/ 將 mapred-site.xml.template 重新命名為 mapred-site.xml,編輯該檔案增加 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
在主目錄下執行如下指令執行 yarn $ sbin/yarn-daemon.sh start resourcemanager $ sbin/yarn-daemon.sh start nodemanager
YARN:分散式資源管理框架 管理整個叢集的資源(記憶體、CPU核數) 分配排程叢集的資源 MapReduce程式打成jar包執行在YARN上 $ bin/hdfs dfs -mkdir -p /user/chenshun/mapreduce/wordcount/input // 建立輸入目錄 $ bin/hdfs dfs -put data/tmp/wc.input /user/chenshun/mapreduce/wordcount/input // 上傳檔案到目錄中 $ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/chenshun/mapreduce/wordcount/input /user/chenshun/mapreduce/wordcount/output // 打包執行(每次執行輸出路徑都不能相同) 察看結果 $ bin/hdfs dfs -cat /user/chenshun/mapreduce/wordcount/output/part* // 察看文字結果 $ bin/hdfs dfs -text /user/chenshun/mapreduce/wordcount/output/part* // 推薦使用,能轉換成文字在檢視 9> 日誌檔案 (1)啟動日誌檔案目錄 $HADOOP_HOME/logs (2)分析日誌檔案格式 log 和 out .log:通過 log4j 記錄的,記錄大部分應用程式的日誌資訊 .out:記錄標準輸出和標準錯誤日誌,少量記錄 (3)日誌檔案的命名規則:框架名稱-使用者名稱-程序名-主機名-日誌格式字尾 歷史伺服器 historyServer : 檢視已經完成的歷史作業記錄 編輯 $HADOOP_HOME/etc/hadoop/mapred-site.xml 檔案增加,注可配可不配 <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-senior01:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-senior01:19888</value> </property>
啟動歷史伺服器 $ sbin/mr-jobhistory-daemon.sh start historyserver 將 mapreduce 產生的日誌檔案上傳到 HDFS 檔案系統上,就可以從頁面上檢視日誌檔案 編輯 $HADOOP_HOME/etc/hadoop/yarn-site.xml 檔案增加 <1> 指定是否開啟日誌聚集功能,預設為 false <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <2> 設定日誌在HDFS上保留的時間期限 <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property>
配置完成之後,需要重啟YARN的服務程序,然後重新跑一次任務就可以檢視過往的日誌資訊,historyserver同樣也要重啟 $ sbin/yarn-daemon.sh stop resourcemanager $ sbin/yarn-daemon.sh stop nodemanager $ sbin/mr-jobhistory-daemon.sh stop historyserver $ sbin/yarn-daemon.sh start resourcemanager $ sbin/yarn-daemon.sh start nodemanager $ sbin/mr-jobhistory-daemon.sh start historyserver $ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/chenshun/mapreduce/wordcount/input /user/chenshun/mapreduce/wordcount/output3 11> HDFS檔案許可權檢測 <1> 設定不啟用HDFS檔案系統的許可權檢查,預設為 true 編輯 $HADOOP_HOME/etc/hadoop/hdfs-site.xml 檔案增加 <property> <name>dfs.permissions.enabled</name> <value>false</value> </property>
<2> 指定修改 Hadoop靜態使用者名稱,預設是 dr.who 編輯 $HADOOP_HOME/etc/hadoop/core-site.xml 檔案增加 <property> <name>hadoop.http.staticuser.user</name> <value>chenshun</value> </property>
配置之後需要重啟HDFS相關的程序 $ sbin/hadoop-daemon.sh stop namenode $ sbin/hadoop-daemon.sh stop datanode $ sbin/mr-jobhistory-daemon.sh stop historyserver $ sbin/yarn-daemon.sh stop resourcemanager $ sbin/yarn-daemon.sh stop nodemanager $ sbin/hadoop-daemon.sh start namenode $ sbin/hadoop-daemon.sh start datanode $ sbin/mr-jobhistory-daemon.sh start historyserver $ sbin/yarn-daemon.sh start resourcemanager $ sbin/yarn-daemon.sh start nodemanager 常見錯誤 1> 格式化錯誤 2> 叢集 id 不一致 注:建議不要切換多使用者去操作,否則將會出現異常錯誤 經常出現的警告 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 在 $HADOOP_HOME/lib/native 目錄中,不能獲取編譯者在什麼系統上進行編譯的,所以會導致版本不一致,無法載入本地庫 解決方法,直接替換改庫到指定版本: $ cd /opt/softwares/ $ tar -zxf native-2.5.0.tar.gz -C /opt/modules/ $ cd /opt/modules/hadoop-2.5.0/lib $ mv native/ back_native $ cp -r /opt/modules/native/ /opt/modules/hadoop-2.5.0/lib 在 $HADOOP_HOME 中執行如下指令就不會出現警告 $ bin/hdfs dfs -ls / 12> Hadoop配置檔案 1、分為兩類:預設配置檔案、自定義配置檔案 2、第一步載入預設配置檔案 3、第二步載入自定義配置檔案 4、優先順序:自定義的檔案優先順序高於預設配置檔案 HDFS core-default -site hdfs-default -site 服務端server 客戶端client