
Spark Transformation —— flatMap運算元
阿新 • • 發佈:2019-01-07
flatMap(func)
類似於map,但是每一個輸入元素,會被對映為0到多個輸出元素(因此,func函式的返回值是一個Seq,而不是單一元素)返回的有點類似於集合的概念,把list,或者array的元素都抽出來,組成一個集合。
第一步和map一樣,最後將所有的輸出分割槽合併成一個。程式碼測試
測試資料準備
在hdfs上放一個檔案1.txt

開啟spark-shell
spark-shell --master spark://master:7077(重要的事情說多遍,spark-shell和spark-submit核心的引數是差不多的)建立RDD
var 
測試flatMap
使用flatMap運算元
var flatMapResult = data.flatMap(line => line.split("\\s+"))
運算flatMap運算元結果
flatMapResult.collect()
使用注意事項
flatMap會將字串看成是一個字元陣列。
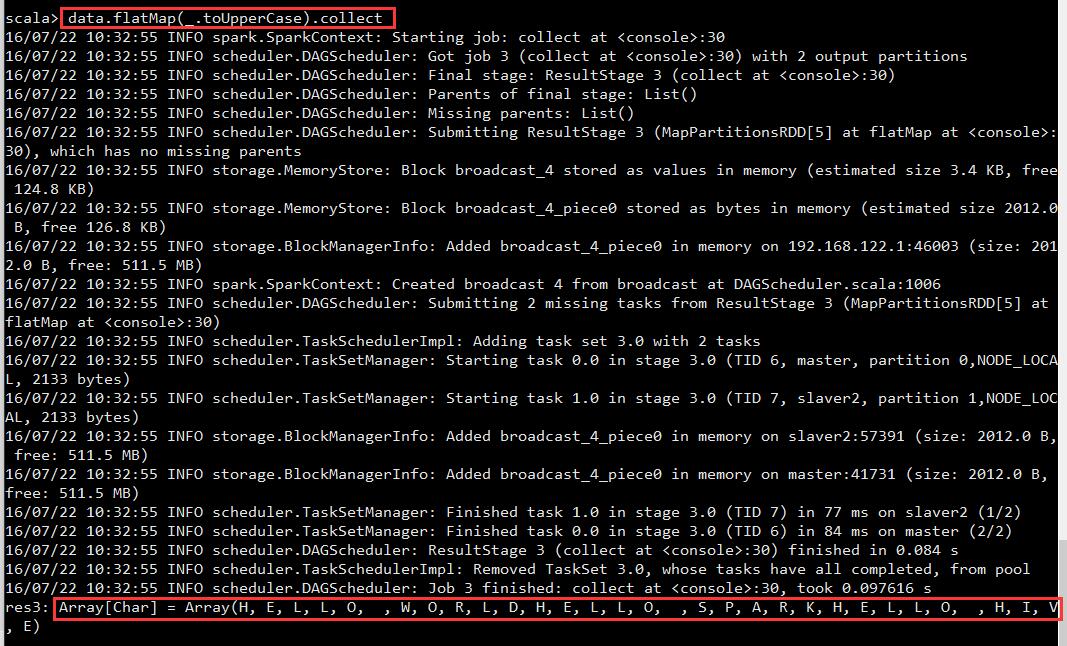
scala> data.map(_.toUpperCase).collect
res32: Array[String] = Array(HELLO WORLD, HELLO SPARK, HELLO HIVE, HI SPARK)
scala> data.flatMap(_.toUpperCase).collect
res33: 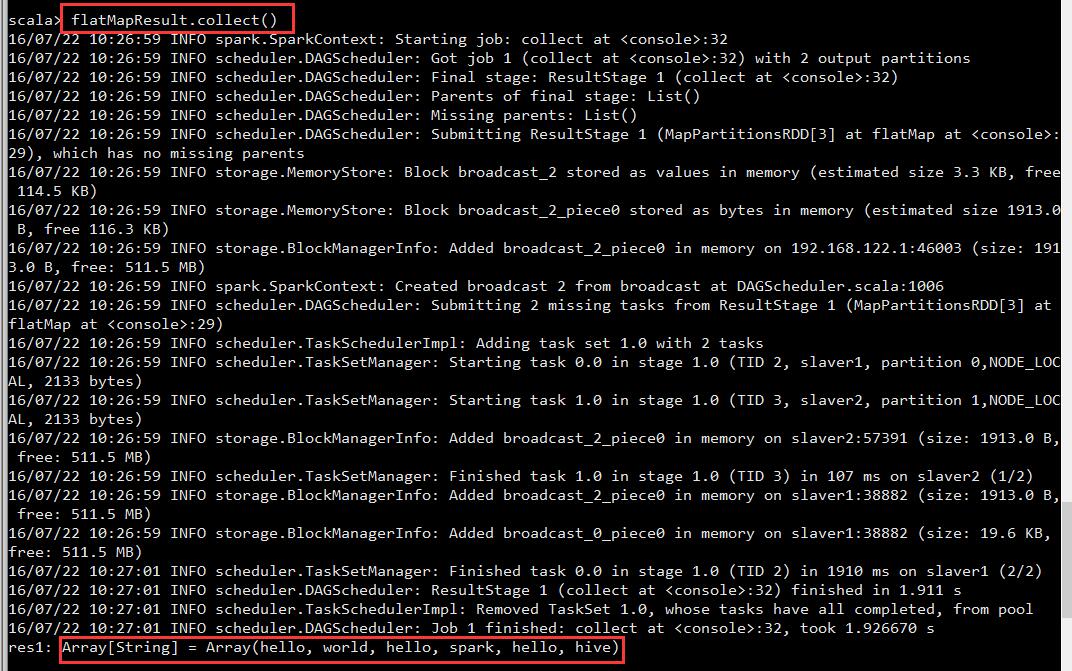
原理圖
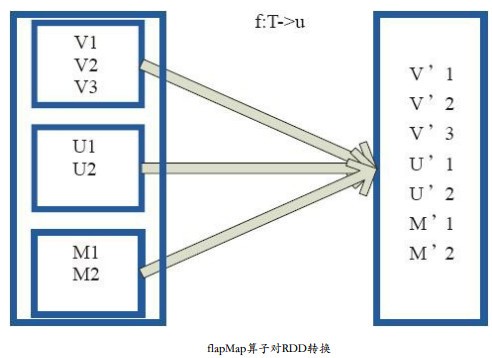
將原來RDD中的每個元素通過函式 f 轉換為新的元素,並將生成的RDD的每個集合中的元素合併為一個集合。 內部建立FlatMappedRDD(this,sc.clean(f))。
圖中,小方框表示RDD的一個分割槽,對分割槽進行flatMap函式操作,flatMap中傳入的函式為 f : T->U,T和U可以是任意的資料型別。將分割槽中的資料通過使用者自定義函式f轉換為新的資料。外部大方框可以認為是一個RDD分割槽,小方框代表一個集合。 V1、 V2、 V3在一個集合作為RDD的一個數據項,轉換為V’1、 V’2、 V’3後,將結合拆散,形成為RDD中的資料項。
原始碼
/**
* Return a new RDD by first applying a function to all elements of this
* RDD, and then flattening the results.
*/
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}