
使用Crontab定時執行Spark任務
今天的主要內容有:
1. Linux下使用定時器crontab
1、安裝
yum -y install vixie-cron
yum -y install crontabs2、啟停命令
service crond start //啟動服務
service crond stop //關閉服務
service crond restart //重啟服務
service crond reload //重新載入配置
service crond status //檢視crontab服務狀態3、檢視所有定時器任務
crontab -l
這個定時器任務是每分鐘用sh執行test.sh指令碼
4、新增定時器任務
crontab -e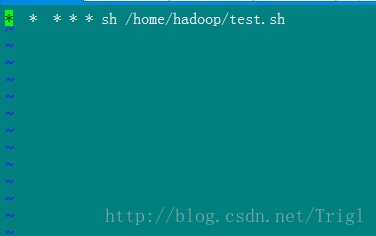
5、crontab的時間表達式
基本格式 :
* * * * * command
分 時 日 月 周 命令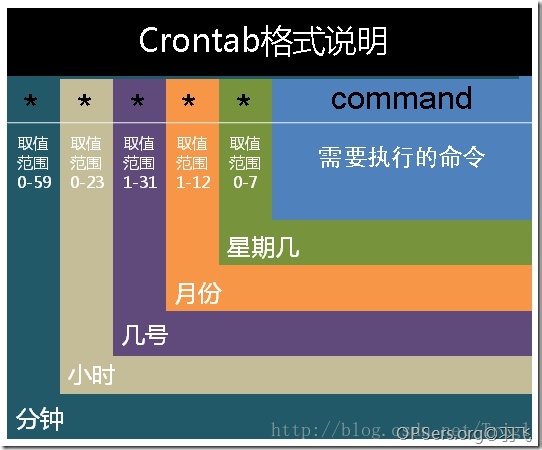
6、常用例項
// 每分鐘執行一次
* * * * *
// 每隔一小時執行一次
00 * * * *
* */1 * * * (/表示頻率)
// 每小時的15和45分各執行一次
15,45 * * * * (,表示並列)
// 在每天上午 8- 11時中間每小時 15 ,45分各執行一次
15,45 8-11 * * * command 2. Linux下編寫Perl指令碼
1、首先安裝Perl
yum -y install gcc gcc-c++ make automake autoconf libtool perl2、寫一個最簡單的Perl指令碼
vi test.pl內容如下:
#!/usr/bin/perl
use strict;
print "HellonWorld!\n" 第一個“#”表示是這一行是註釋
第二個“!”表示這一行不是普通註釋,而是直譯器路徑的宣告行
後面的“/usr/bin/perl”是perl直譯器的安裝路徑,也有可能是:“/usr/local/bin/perl”,如果那個不行,就換這個
use strict是嚴格檢查語法
3、給該指令碼新增可執行許可權
chmod 764 test.plLinux檔案的基本許可權有9個,分別是owner/group/other三種身份各有read/write/execute許可權,而各許可權的分數對照是r:4,w:2,x:1;
每種身份的許可權都是需要累加的,比如當權限是[-rwxrwx—],則表明:
owner:rwx=4+2+1=7
group:rwx=4+2+1=7
other:—=0+0+0=0
即該檔案的許可權數字就是770
4、然後執行該Perl檔案即可
./test.pl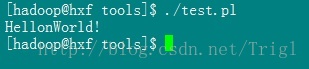
由於我們聲明瞭直譯器路徑,所以不需要使用perl test.pl,而是直接 ./ 就可以執行了
3. 在Java程式中呼叫Linux命令
主要用到兩個類Process和Runtime,程式碼示例如下:
Runtime rt = Runtime.getRuntime();
String[] cmd = { "/bin/sh", "-c", "cd ~" };
Process proc = rt.exec(cmd);
proc.waitFor();
proc.destroy();如果-c 選項存在,命令就從字串中讀取
4. 例項:每天0點30分執行Spark任務
1、首先編寫執行Spark任務的Perl指令碼:getappinfo.pl
#!/usr/bin/perl
use strict;
# 獲取上一天的日期
my ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime(time - 3600 * 24);
# $year是從1900開始計數的,所以$year需要加上1900;
$year += 1900;
# $mon是從0開始計數的,所以$mon需要加上1;
$mon += 1;
print "$year-$mon-$mday-$hour-$min-$sec, wday: $wday, yday: $yday, isdst: $isdst\n";
sub exec_spark
{
my $dst_date = sprintf("%d%02d%02d", $year, $mon, $mday);
my $spark_generateapp = "nohup /data/install/spark-2.0.0-bin-hadoop2.7/bin/spark-submit --master spark://hxf:7077 --executor-memory 30G --executor-cores 24 --conf spark.default.parallelism=300 --class com.analysis.main.GenAppInfo /home/hadoop/jar/analysis.jar $dst_date > /home/hadoop/logs/genAppInfo.log &";
print "$spark_generateapp\n";
return system($spark_generateapp);
}
if (!exec_spark())
{
print "done\n";
exit(0);
}2、新增定時器任務:每天的0點30分執行getappinfo.pl
crontab -e新增以下內容:
30 0 * * * /data/tools/getappinfo.pl3、指令碼中的Spark程式如下:
package com.analysis.main
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object TestCrontab {
// args -> 20170101
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("引數異常")
System.exit(1)
}
val year = args(0).substring(0, 4)
val month = args(0).substring(4, 6)
val day = args(0).substring(6, 8)
//設定序列化器為KryoSerializer,也可以在配置檔案中進行配置
System.setProperty("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 設定應用名稱,新建Spark環境
val sparkConf = new SparkConf().setAppName("GenerateAppInfo_" + args(0))
val spark = SparkSession
.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
println("Start " + "GenerateAppInfo_" + args(0))
import spark.sql
sql("use arrival")
val sqlStr = "select opttime, firstimei, secondimei, thirdimei, applist, year, month, day from base_arrival where year=" + year + " and month=" + month + " and day=" + day
sql(sqlStr).show()
// 跑GenAppInfoNew
val rt = Runtime.getRuntime()
val cmd = Array("/bin/sh", "-c", "/data/tools/getappinfo_new.pl")
try {
val proc = rt.exec(cmd)
proc.waitFor()
proc.destroy()
println("執行提取appinfo_new任務")
} catch {
case e: Exception => println("執行提取appinfo_new任務失敗:" + e.getMessage())
}
}
}這個程式首先從Hive中查詢資料並展示出來,然後再呼叫Linux的shell執行另一個Perl指令碼getappinfo_new.pl,我們可以在這個指令碼中寫入其他操作