
Kubernetes-基於EFK進行統一的日誌管理
1、統一日誌管理的整體方案
通過應用和系統日誌可以瞭解Kubernetes叢集內所發生的事情,對於除錯問題和監視叢集活動來說日誌非常有用。對於大部分的應用來說,都會具有某種日誌機制。因此,大多數容器引擎同樣被設計成支援某種日誌機制。對於容器化應用程式來說,最簡單和最易接受的日誌記錄方法是將日誌內容寫入到標準輸出和標準錯誤流。
但是,容器引擎或執行時提供的本地功能通常不足以支撐完整的日誌記錄解決方案。例如,如果一個容器崩潰、一個Pod被驅逐、或者一個Node死亡,應用相關者可能仍然需要訪問應用程式的日誌。因此,日誌應該具有獨立於Node、Pod或者容器的單獨儲存和生命週期,這個概念被稱為群集級日誌記錄。群集級日誌記錄需要一個獨立的後端來儲存、分析和查詢日誌。Kubernetes本身並沒有為日誌資料提供原生的儲存解決方案,但可以將許多現有的日誌記錄解決方案整合到Kubernetes叢集中。在Kubernetes中,有三個層次的日誌:
- 基礎日誌
- Node級別的日誌
- 群集級別的日誌架構
1.1 基礎日誌
kubernetes基礎日誌即將日誌資料輸出到標準輸出流,可以使用kubectl logs命令獲取容器日誌資訊。如果Pod中有多個容器,可以通過將容器名稱附加到命令來指定要訪問哪個容器的日誌。例如,在Kubernetes叢集中的devops名稱空間下有一個名稱為nexus3-f5b7fc55c-hq5v7的Pod,就可以通過如下的命令獲取日誌:
$ kubectl logs nexus3-f5b7fc55c-hq5v7 --namespace=devops
1.2 Node級別的日誌
容器化應用寫入到stdout和stderr的所有內容都是由容器引擎處理和重定向的。例如,docker容器引擎會將這兩個流重定向到日誌記錄驅動,在Kubernetes中該日誌驅動被配置為以json格式寫入檔案。docker json日誌記錄驅動將每一行視為單獨的訊息。當使用docker日誌記錄驅動時,並不支援多行訊息,因此需要在日誌代理級別或更高級別上處理多行訊息。
預設情況下,如果容器重新啟動,kubectl將會保留一個已終止的容器及其日誌。如果從Node中驅逐Pod,那麼Pod中所有相應的容器也會連同它們的日誌一起被驅逐。Node級別的日誌中的一個重要考慮是實現日誌旋轉,這樣日誌不會消耗Node上的所有可用儲存。Kubernetes目前不負責旋轉日誌,部署工具應該建立一個解決方案來解決這個問題。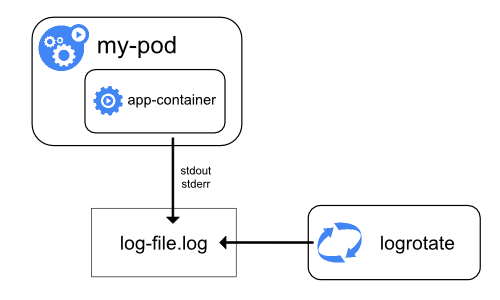
在Kubernetes中有兩種型別的系統元件:執行在容器中的元件和不在容器中執行的元件。例如:
- Kubernetes排程器和kube-proxy在容器中執行。
- kubelet和容器執行時,例如docker,不在容器中執行。
在帶有systemd的機器上,kubelet和容器執行時寫入journaId。如果systemd不存在,它們會在/var/log目錄中寫入.log檔案。在容器中的系統元件總是繞過預設的日誌記錄機制,寫入到/var/log目錄,它們使用golg日誌庫。可以找到日誌記錄中開發文件中那些元件記錄嚴重性的約定。
類似於容器日誌,在/var/log目錄中的系統元件日誌應該被旋轉。這些日誌被配置為每天由logrotate進行旋轉,或者當大小超過100mb時進行旋轉。
1.3 叢集級別的日誌架構
Kubernetes本身沒有為群集級別日誌記錄提供原生解決方案,但有幾種常見的方法可以採用:
- 使用執行在每個Node上的Node級別的日誌記錄代理;
- 在應用Pod中包含一個用於日誌記錄的sidecar。
- 將日誌直接從應用內推到後端。
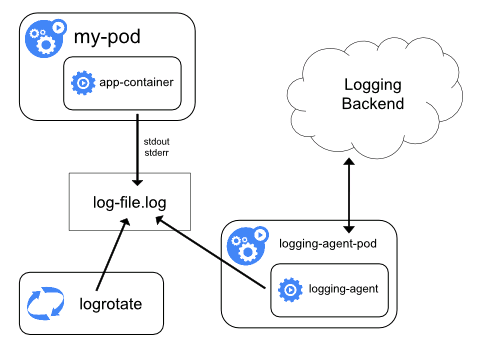
經過綜合考慮,本文采用通過在每個Node上包括Node級別的日誌記錄代理來實現群集級別日誌記錄。日誌記錄代理暴露日誌或將日誌推送到後端的專用工具。通常,logging-agent是一個容器,此容器能夠訪問該Node上的所有應用程式容器的日誌檔案。
因為日誌記錄必須在每個Node上執行,所以通常將它作為DaemonSet副本、或一個清單Pod或Node上的專用本機程序。然而,後兩種方法後續將會被放棄。使用Node級別日誌記錄代理是Kubernetes叢集最常見和最受歡迎的方法,因為它只為每個節點建立一個代理,並且不需要對節點上執行的應用程式進行任何更改。但是,Node級別日誌記錄僅適用於應用程式的標準輸出和標準錯誤。
Kubernetes本身並沒有指定日誌記錄代理,但是有兩個可選的日誌記錄代理與Kubernetes版本打包釋出:和谷歌雲平臺一起使用的Stackdriver和Elasticsearch,兩者都使用自定義配置的fluentd作為Node上的代理。在本文的方案中,Logging-agent 採用 Fluentd,而 Logging Backend 採用 Elasticsearch,前端展示採用Grafana。即通過 Fluentd 作為 Logging-agent 收集日誌,並推送給後端的Elasticsearch;Grafana從Elasticsearch中獲取日誌,並進行統一的展示。
2、安裝統一日誌管理的元件
在本文中採用使用Node日誌記錄代理的方面進行Kubernetes的統一日誌管理,相關的工具採用:
- 日誌記錄代理(logging-agent):日誌記錄代理用於從容器中獲取日誌資訊,使用Fluentd;
- 日誌記錄後臺(Logging-Backend):日誌記錄後臺用於處理日誌記錄代理推送過來的日誌,使用Elasticsearch;
- 日誌記錄展示:日誌記錄展示用於向用戶顯示統一的日誌資訊,使用Kibana。
在Kubernetes中通過了Elasticsearch 附加元件,此元件包括Elasticsearch、Fluentd和Kibana。Elasticsearch是一種負責儲存日誌並允許查詢的搜尋引擎。Fluentd從Kubernetes中獲取日誌訊息,併發送到Elasticsearch;而Kibana是一個圖形介面,用於檢視和查詢儲存在Elasticsearch中的日誌。在安裝部署之前,對於環境的要求如下:
2.1 安裝部署Elasticsearch
Elasticsearch是一個基於Apache Lucene(TM)的開源搜尋和資料分析引擎引擎,Elasticsearch使用Java進行開發,並使用Lucene作為其核心實現所有索引和搜尋的功能。它的目的是通過簡單的RESTful API來隱藏Lucene的複雜性,從而讓全文搜尋變得簡單。Elasticsearch不僅僅是Lucene和全文搜尋,它還提供如下的能力:
- 分散式的實時檔案儲存,每個欄位都被索引並可被搜尋;
- 分散式的實時分析搜尋引擎;
- 可以擴充套件到上百臺伺服器,處理PB級結構化或非結構化資料。
在Elasticsearch中,包含多個索引(Index),相應的每個索引可以包含多個型別(Type),這些不同的型別每個都可以儲存多個文件(Document),每個文件又有多個屬性。索引 (index) 類似於傳統關係資料庫中的一個數據庫,是一個儲存關係型文件的地方。Elasticsearch 使用的是標準的 RESTful API 和 JSON。此外,還構建和維護了很多其他語言的客戶端,例如 Java, Python, .NET, 和 PHP。
下面是Elasticsearch的YAML配置檔案,在此配置檔案中,定義了一個名稱為elasticsearch-logging的ServiceAccount,並授予其能夠對名稱空間、服務和端點讀取的訪問許可權;並以StatefulSet型別部署Elasticsearch。
# RBAC authn and authz
apiVersion: v1
kind: ServiceAccount
metadata:
name: elasticsearch-logging
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: elasticsearch-logging
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "services"
- "namespaces"
- "endpoints"
verbs:
- "get"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: kube-system
name: elasticsearch-logging
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: elasticsearch-logging
namespace: kube-system
apiGroup: ""
roleRef:
kind: ClusterRole
name: elasticsearch-logging
apiGroup: ""
---
# Elasticsearch deployment itself
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch-logging
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
version: v6.2.5
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
serviceName: elasticsearch-logging
replicas: 2
selector:
matchLabels:
k8s-app: elasticsearch-logging
version: v6.2.5
template:
metadata:
labels:
k8s-app: elasticsearch-logging
version: v6.2.5
kubernetes.io/cluster-service: "true"
spec:
serviceAccountName: elasticsearch-logging
containers:
- image: k8s.gcr.io/elasticsearch:v6.2.5
name: elasticsearch-logging
resources:
# need more cpu upon initialization, therefore burstable class
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- name: elasticsearch-logging
mountPath: /data
env:
- name: "NAMESPACE"
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumes:
- name: elasticsearch-logging
emptyDir: {}
# Elasticsearch requires vm.max_map_count to be at least 262144.
# If your OS already sets up this number to a higher value, feel free
# to remove this init container.
initContainers:
- image: alpine:3.6
command: ["/sbin/sysctl", "-w", "vm.max_map_count=262144"]
name: elasticsearch-logging-init
securityContext:
privileged: true
通過執行如下的命令部署Elasticsearch:
$ kubectl create -f {path}/es-statefulset.yaml
下面Elasticsearch的代理服務YAML配置檔案,代理服務暴露的埠為9200。
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-logging
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Elasticsearch"
spec:
ports:
- port: 9200
protocol: TCP
targetPort: db
selector:
k8s-app: elasticsearch-logging
通過執行如下的命令部署Elasticsearch的代理服務:
$ kubectl create -f {path}/es-service.yaml
2.2 安裝部署Fluentd

Fluentd是一個開源資料收集器,通過它能對資料進行統一收集和消費,能夠更好地使用和理解資料。Fluentd將資料結構化為JSON,從而能夠統一處理日誌資料,包括:收集、過濾、快取和輸出。Fluentd是一個基於外掛體系的架構,包括輸入外掛、輸出外掛、過濾外掛、解析外掛、格式化外掛、快取外掛和儲存外掛,通過外掛可以擴充套件和更好的使用Fluentd。

Fluentd的整體處理過程如下,通過Input外掛獲取資料,並通過Engine進行資料的過濾、解析、格式化和快取,最後通過Output外掛將資料輸出給特定的終端。

在本文中, Fluentd 作為 Logging-agent 進行日誌收集,並將收集到的日子推送給後端的Elasticsearch。對於Kubernetes來說,DaemonSet確保所有(或一些)Node會執行一個Pod副本。因此,Fluentd被部署為DaemonSet,它將在每個節點上生成一個pod,以讀取由kubelet,容器執行時和容器生成的日誌,並將它們傳送到Elasticsearch。為了使Fluentd能夠工作,每個Node都必須標記beta.kubernetes.io/fluentd-ds-ready=true。
下面是Fluentd的ConfigMap配置檔案,此檔案定義了Fluentd所獲取的日誌資料來源,以及將這些日誌資料輸出到Elasticsearch中。
kind: ConfigMap apiVersion: v1 metadata: name: fluentd-es-config-v0.1.4 namespace: kube-system labels: addonmanager.kubernetes.io/mode: Reconcile data: system.conf: |- <system> root_dir /tmp/fluentd-buffers/ </system> containers.input.conf: |- <source> @id fluentd-containers.log @type tail path /var/log/containers/*.log pos_file /var/log/es-containers.log.pos time_format %Y-%m-%dT%H:%M:%S.%NZ tag raw.kubernetes.* read_from_head true <parse> @type multi_format <pattern> format json time_key time time_format %Y-%m-%dT%H:%M:%S.%NZ </pattern> <pattern> format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/ time_format %Y-%m-%dT%H:%M:%S.%N%:z </pattern> </parse> </source> # Detect exceptions in the log output and forward them as one log entry. <match raw.kubernetes.**> @id raw.kubernetes @type detect_exceptions remove_tag_prefix raw message log stream stream multiline_flush_interval 5 max_bytes 500000 max_lines 1000 </match> output.conf: |- # Enriches records with Kubernetes metadata <filter kubernetes.**> @type kubernetes_metadata </filter> <match **> @id elasticsearch @type elasticsearch @log_level info include_tag_key true host elasticsearch-logging port 9200 logstash_format true <buffer> @type file path /var/log/fluentd-buffers/kubernetes.system.buffer flush_mode interval retry_type exponential_backoff flush_thread_count 2 flush_interval 5s retry_forever retry_max_interval 30 chunk_limit_size 2M queue_limit_length 8 overflow_action block </buffer> </match>
通過執行如下的命令建立Fluentd的ConfigMap:
$ kubectl create -f {path}/fluentd-es-configmap.yaml
Fluentd本身的YAML配置檔案如下所示:
apiVersion: v1 kind: ServiceAccount metadata: name: fluentd-es namespace: kube-system labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "namespaces" - "pods" verbs: - "get" - "watch" - "list" --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: fluentd-es namespace: kube-system apiGroup: "" roleRef: kind: ClusterRole name: fluentd-es apiGroup: "" --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-es-v2.2.0 namespace: kube-system labels: k8s-app: fluentd-es version: v2.2.0 kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: selector: matchLabels: k8s-app: fluentd-es version: v2.2.0 template: metadata: labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" version: v2.2.0 # This annotation ensures that fluentd does not get evicted if the node # supports critical pod annotation based priority scheme. # Note that this does not guarantee admission on the nodes (#40573). annotations: scheduler.alpha.kubernetes.io/critical-pod: '' seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: priorityClassName: system-node-critical serviceAccountName: fluentd-es containers: - name: fluentd-es image: k8s.gcr.io/fluentd-elasticsearch:v2.2.0 env: - name: FLUENTD_ARGS value: --no-supervisor -q resources: limits: memory: 500Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: config-volume mountPath: /etc/fluent/config.d nodeSelector: beta.kubernetes.io/fluentd-ds-ready: "true" terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: config-volume configMap: name: fluentd-es-config-v0.1.4
通過執行如下的命令部署Fluentd:
$ kubectl create -f {path}/fluentd-es-ds.yaml
2.3 安裝部署Kibana
Kibana是一個開源的分析與視覺化平臺,被設計用於和Elasticsearch一起使用的。通過kibana可以搜尋、檢視和互動存放在Elasticsearch中的資料,利用各種不同的圖表、表格和地圖等,Kibana能夠對資料進行分析與視覺化。Kibana部署的YAML如下所示,通過環境變數ELASTICSEARCH_URL,指定所獲取日誌資料的Elasticsearch服務,此處為:http://elasticsearch-logging:9200,elasticsearch.cattle-logging是elasticsearch在Kubernetes中代理服務的名稱。在Fluented配置檔案中,有下面的一些關鍵指令:
- source指令確定輸入源。
- match指令確定輸出目標。
- filter指令確定事件處理管道。
- system指令設定系統範圍的配置。
- label指令將輸出和過濾器分組以進行內部路由
- @include指令包含其他檔案。
apiVersion: apps/v1 kind: Deployment metadata: name: kibana-logging namespace: kube-system labels: k8s-app: kibana-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: replicas: 1 selector: matchLabels: k8s-app: kibana-logging template: metadata: labels: k8s-app: kibana-logging annotations: seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: containers: - name: kibana-logging image: docker.elastic.co/kibana/kibana-oss:6.2.4 resources: # need more cpu upon initialization, therefore burstable class limits: cpu: 1000m requests: cpu: 100m env: - name: ELASTICSEARCH_URL value: http://elasticsearch-logging:9200 ports: - containerPort: 5601 name: ui protocol: TCP
通過執行如下的命令部署Kibana的代理服務:
$ kubectl create -f {path}/kibana-deployment.yaml
下面Kibana的代理服務YAML配置檔案,代理服務的型別為NodePort。
apiVersion: v1 kind: Service metadata: name: kibana-logging namespace: kube-system labels: k8s-app: kibana-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "Kibana" spec: type: NodePort ports: - port: 5601 protocol: TCP targetPort: ui selector: k8s-app: kibana-logging
通過執行如下的命令部署Kibana的代理服務:
$ kubectl create -f {path}/kibana-service.yaml
3、日誌資料展示
通過如下命令獲取Kibana的對外暴露的埠:
$ kubectl get svc --namespace=kube-system
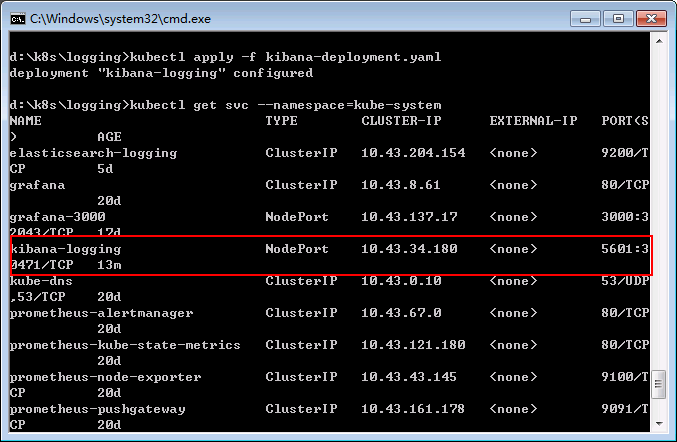
從輸出的資訊可以知道,kibana對外暴露的埠為30471,因此在Kubernetes叢集外可以通過:http://{NodeIP}:30471 訪問kibana。
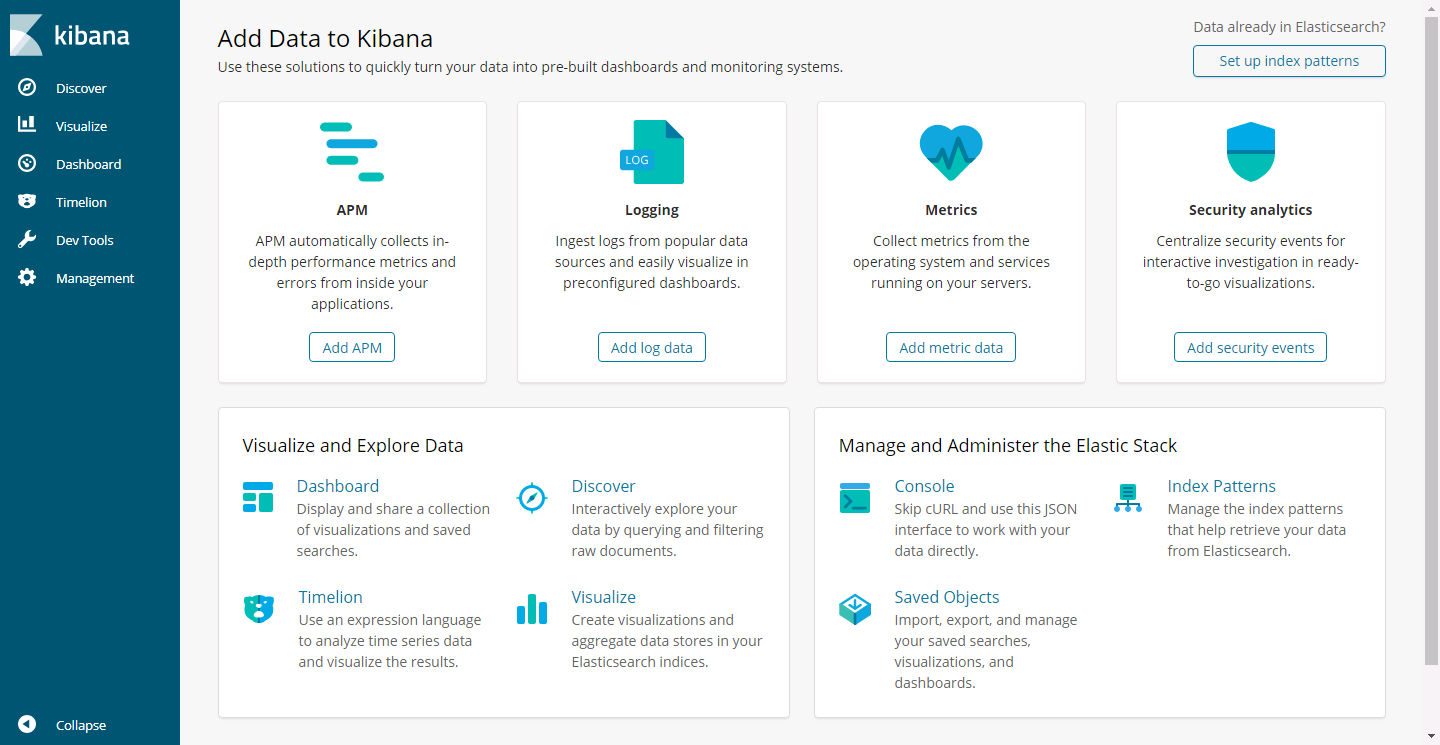
通過點選“Discover”,就能夠實時看看從容器中獲取到的日誌資訊:
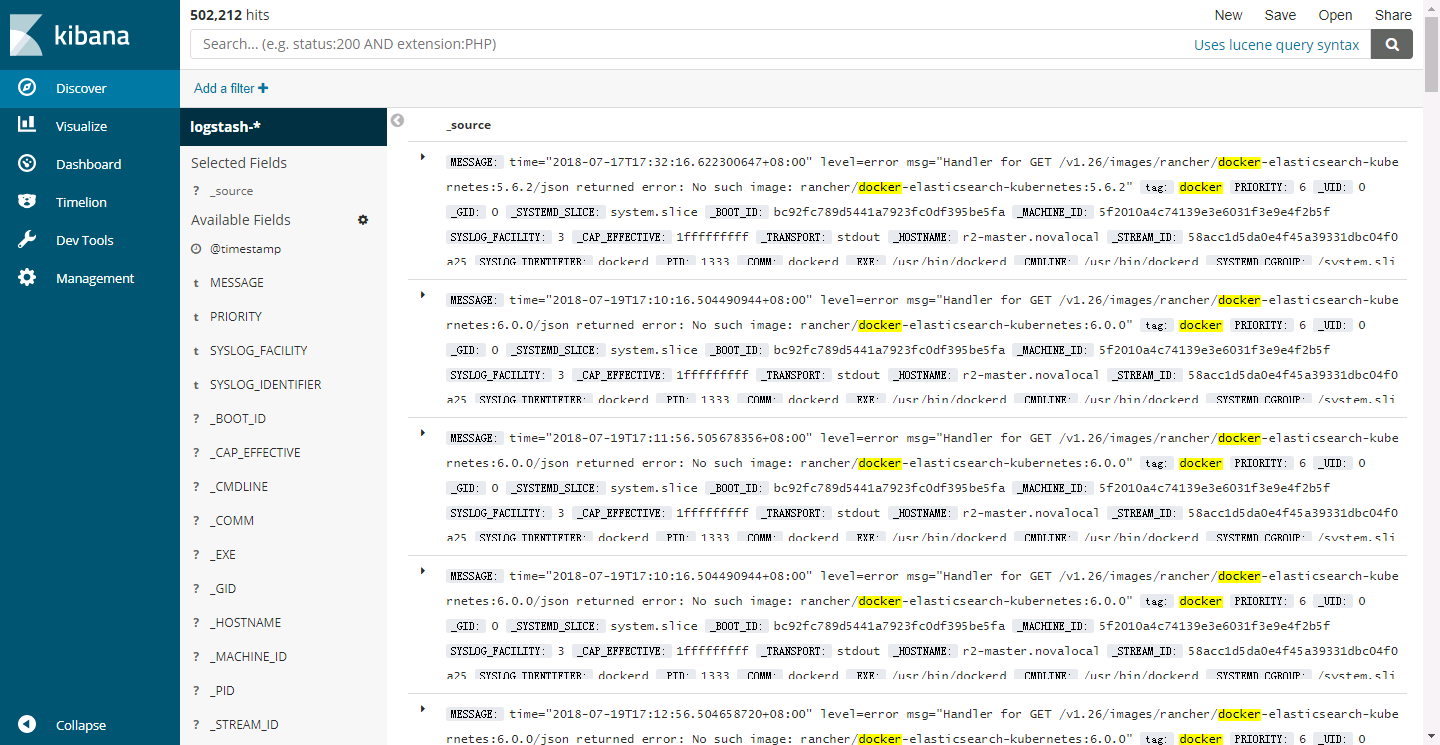
參考資料
1.《Logging Architecture》地址:https://kubernetes.io/docs/concepts/cluster-administration/logging/
2.《Kubernetes Logging with Fluentd》地址:https://docs.fluentd.org/v0.12/articles/kubernetes-fluentd
3.《Quickstart Guide》地址:https://docs.fluentd.org/v0.12/articles/quickstart
4.《fluentd-elasticsearch》地址:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/fluentd-elasticsearch
5.《Elasticsearch》地址:https://www.elastic.co/products/elasticsearch
6.《What is Fluentd?》地址:https://www.fluentd.org/architecture
7.《Configuration File Syntax》地址:https://docs.fluentd.org/v1.0/articles/config-file
8.《A Practical Introduction to Elasticsearch》地址:https://www.elastic.co/blog/a-practical-introduction-to-elasticsearch