
Java8影響並行流效能的主要因素
阿新 • • 發佈:2019-01-07
影響並行流效能的主要因素有5 個,依次分析如下。
- 資料大小
- 源資料結構
- 裝箱
- 核的數量
- 單元處理開銷
比如資料大小,這是一場並行執行花費時間和分解合併操作開銷之間的戰爭。花在流中每個元素身上的時間越長,並行操作帶來的效能提升越明顯。
使用並行流框架,理解如何分解和合並問題是很有幫助的。這讓我們能夠知悉底層如何工作,但卻不必瞭解框架的細節。來看一個具體的問題,看看如何分解和合並它。如下是很簡單的並行求和的程式碼。
在底層,並行流還是沿用了fork/join 框架。fork 遞迴式地分解問題,然後每段並行執行,最終由join 合併結果,返回最後的值。private static int addIntegers(List<Integer> values) { return values.parallelStream() .mapToInt(i -> i) .sum(); }
下圖形象地展示了上面程式碼所示的操作。
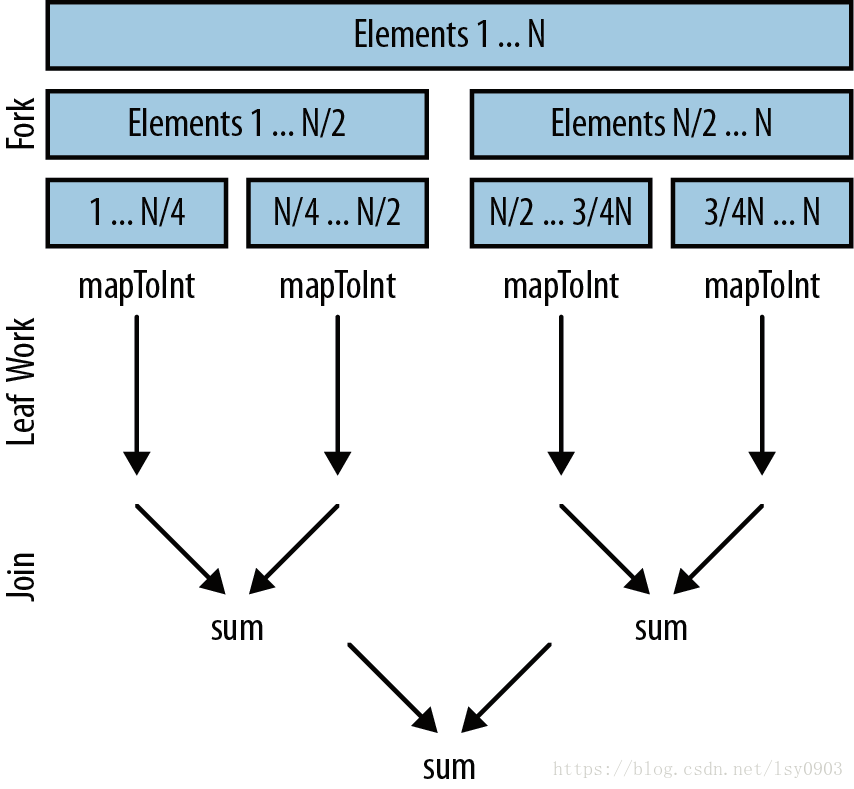
使用fork/join 分解合併問題
假設並行流將我們的工作分解開,在一個四核的機器上並行執行。1. 資料被分成四塊。
2. 如程式碼所示,計算工作在每個執行緒裡並行執行。這包括將每個Integer 物件對映為int值,然後在每個執行緒裡將1/4 的數字相加。理想情況下,我們希望在這裡花的時間越多越好,因為這裡是並行操作的最佳場所。
3. 然後合併結果。在上面程式碼中,就是sum 操作,但這也可能是reduce、collect 或其他終結操作。
我們可以根據效能的好壞,將核心類庫提供的通用資料結構分成以下3 組。
- 效能好
- 效能一般
- 效能差
初始的資料結構影響巨大。舉一個極端的例子,對比對10 000 個整數並行求和,使用ArrayList要比使用LinkedList 快10 倍。這不是說業務邏輯的效能情況也會如此,只是說明了資料結構對於效能的影響之大。使用形如LinkedList 這樣難於分解的資料結構並行執行可能更慢。
理想情況下,一旦流框架將問題分解成小塊,就可以在每個執行緒裡單獨處理每一小塊,執行緒之間不再需要進一步通訊。無奈現實不總遂人願!
在討論流中單獨操作每一塊的種類時,可以分成兩種不同的操作:無狀態的和有狀態的。無狀態操作整個過程中不必維護狀態,有狀態操作則有維護狀態所需的開銷和限制。如果能避開有狀態,選用無狀態操作,就能獲得更好的並行效能。無狀態操作包括map、filter 和flatMap,有狀態操作包括sorted、distinct 和limit。
