
用Python+Gephi畫《人民的名義》人物關係圖
理一下畫關係圖的步驟:
首先,要找到《人民的名義》的臺詞(或劇本),可以使用UTF8編碼的txt檔案。
其次,要提取劇中的角色,這裡我們使用jieba分詞模組來提取文字中的角色名,得到圖的“節點”
然後,為再劇本中每一段中出現的若干個角色,兩兩之間建立一條“邊”,根據兩兩角色一同出現頻度,來決定邊的“權值”
最後,根據上面的資訊,使用Gephi來圖
可以先定義三個變數
# names : 儲存人物,鍵為人物名稱,值為該人物在全文中出現的次數 # relationship : 儲存人物關係的有向邊,鍵為有向邊的起點,值為一個字典 edge ,edge 的鍵為有向邊的終點,值是有向邊的權值, # 代表兩個人物之間聯絡的緊密程度 # lineNames : 快取變數,儲存對每一段分詞得到當前段中出現的人物名稱 names = {} relationships = {} lineNames = []
1.提取角色(節點)
jieba分詞中對人名的識別不夠準確,比如,可能會把“明白”、“文明”這樣的詞識別為人名,針對這個問題,可以建立使用者自定義字典,以提高《人民的名義》中人名的識別準確率。
可以在網上查詢角色表,寫入一個txt檔案。如下是一個自定義字典的示例,每行第一個代表字典中的詞,第二個代表頻數,第三個代表詞性。
| 侯亮平 100 nr 沙瑞金 100 nr 李達康 100 nr 高育良 100 nr 祁同偉 100 nr 陸亦可 100 nr 高小琴 100 nr 吳慧芬 100 nr 劉新建 100 nr 陳岩石 100 nr 季昌明 100 nr 趙瑞龍 100 nr 鄭西坡 100 nr 鍾小艾 100 nr 趙東來 100 nr 蔡成功 100 nr 歐陽菁 100 nr 丁義珍 100 nr 程度 100 nr 陳海 100 nr 鄭勝利 100 nr 王文革 100 nr 田國富 100 nr 趙德漢 100 nr 易學習 100 nr 樑璐 100 nr 孫連成 100 nr 肖鋼玉 100 nr 林華華 100 nr |
jieba.load_userdict("RoleTable.txt")在分詞後判斷一個詞是否為人名,可以用下面兩個條件篩選,滿足條件的可以人為不是人名
1) 該詞詞性不為 “nr” 2) 該詞長度小於2
with codecs.open("人民的名義.txt", 'r', 'utf8') as f: for line in f.readlines(): # 注意是 readlines 要加s 不加s 只讀取一行 poss = pseg.cut(line) # 分詞,返回詞性 lineNames.append([]) # 為本段增加一個人物列表 for w in poss: if w.flag != 'nr' or len(w.word) < 2: continue # 當分詞長度小於2或該詞詞性不為nr(人名)時認為該詞不為人名 lineNames[-1].append(w.word) # 為當前段的環境增加一個人物 if names.get(w.word) is None: # 如果某人物(w.word)不在人物字典中 names[w.word] = 0 relationships[w.word] = {} names[w.word] += 1
可以檢視一下結果:
# 輸出人物出現次數統計結果
for name, times in names.items():
print(name, times)2.建立角色關係(邊)
# 對於 lineNames 中每一行,我們為該行中出現的所有人物兩兩相連。如果兩個人物之間尚未有邊建立,則將新建的邊權值設為 1,
# 否則將已存在的邊的權值加 1。這種方法將產生很多的冗餘邊,這些冗餘邊將在最後處理。
for line in lineNames:
for name1 in line:
for name2 in line:
if name1 == name2:
continue
if relationships[name1].get(name2) is None:
relationships[name1][name2] = 1
else:
relationships[name1][name2] = relationships[name1][name2] + 1
3.輸出圖的資訊
# 由於分詞的不準確會出現很多不是人名的“人名”,從而導致出現很多冗餘邊,為此可設定閾值為10,即當邊出現10次以上則認為不是冗餘
with codecs.open("People_node.txt", "w", "utf8") as f:
f.write("ID Label Weight\r\n")
for name, times in names.items():
if times > 10:
f.write(name + " " + name + " " + str(times) + "\r\n")
with codecs.open("People_edge.txt", "w", "utf8") as f:
f.write("Source Target Weight\r\n")
for name, edges in relationships.items():
for v, w in edges.items():
if w > 10:
f.write(name + " " + v + " " + str(w) + "\r\n")節點:

邊:
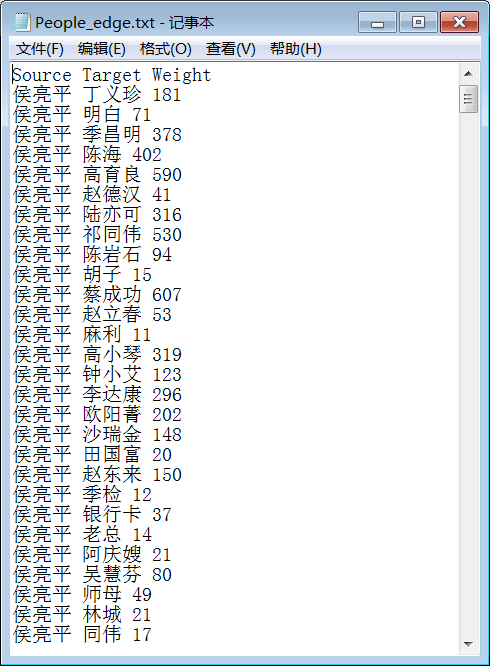
至此工作已完成一大半。
4.使用Gephi畫圖
筆者是在Windows環境下使用Gephi,為了能將圖的資訊匯入Gephi,需要對上面的People_node.txt與People_edge.txt檔案進行預處理。Linux環境可以跳過此步驟。
我們藉助Office的Excel將txt檔案轉換為csv檔案(一種逗號分隔的檔案)
開啟Excel -> 資料 -> 自文字 -> 選擇要轉換的txt檔案
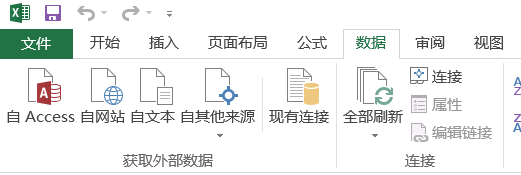
選擇下一步
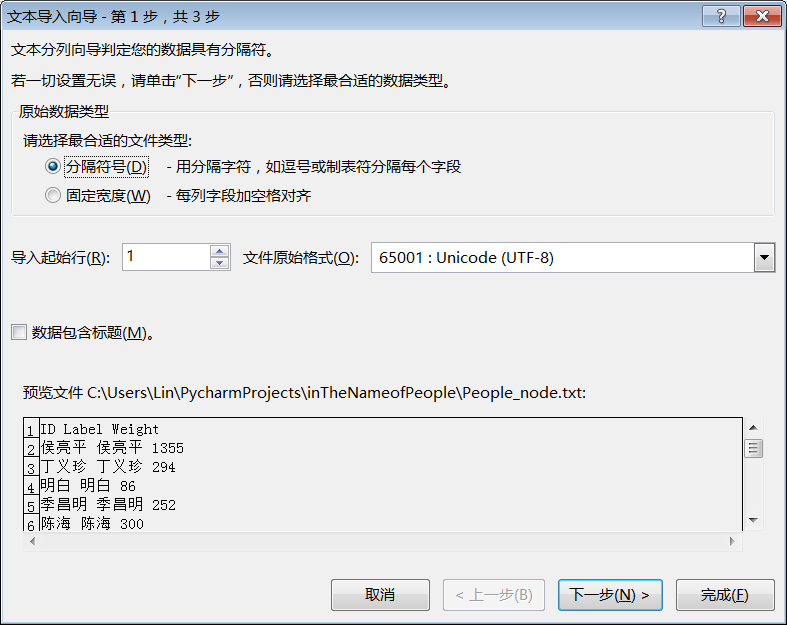
注意選擇分隔符號為空格
然後就可以將txt文字匯入,最後選擇另存為csv檔案即可。
開啟Gephi -> 檔案 -> 匯入電子表格 -> 選擇剛剛生成的csv檔案
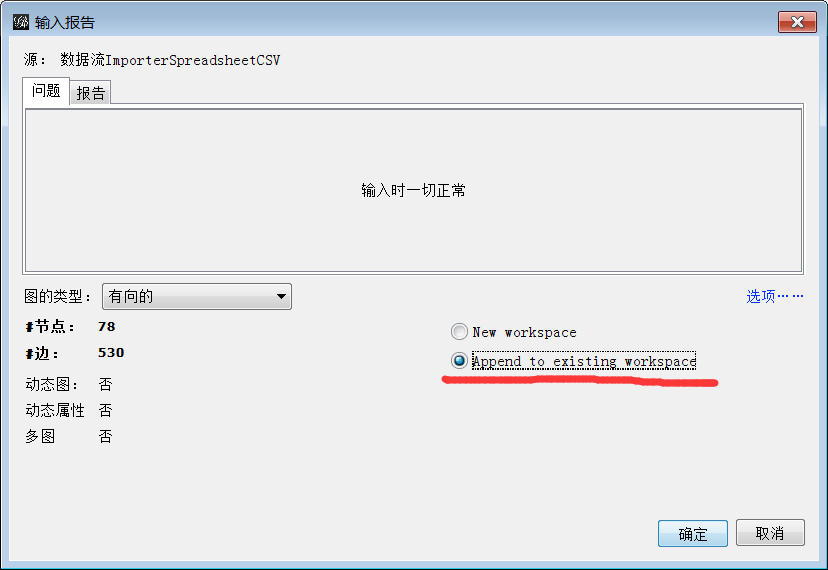
注意:先匯入節點後匯入邊,兩個檔案匯入到同一個工作區域內
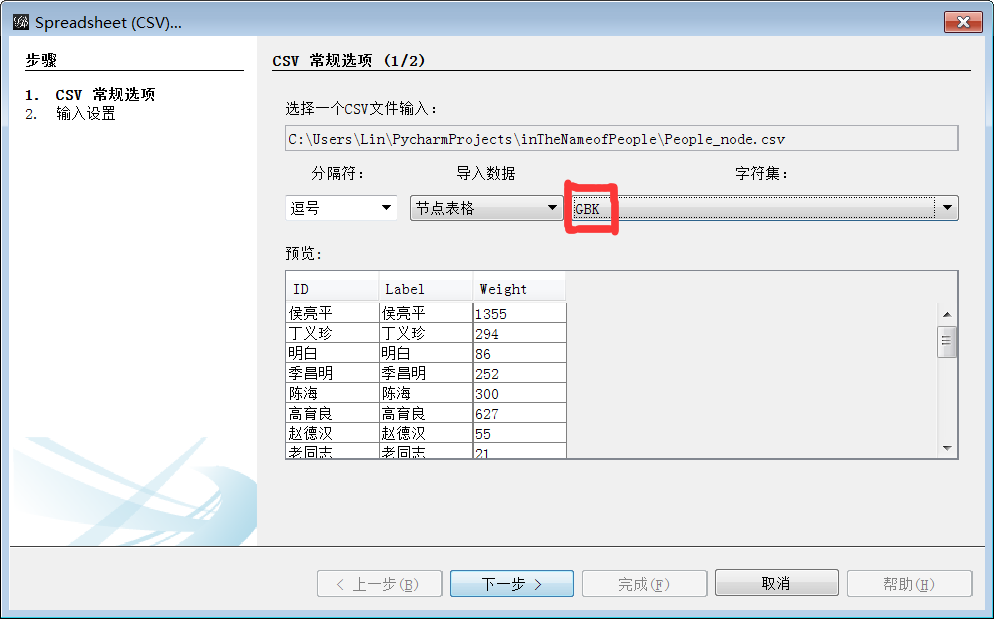
若出現亂碼重選字符集(如GBK)
注意:匯入節點檔案時可以是新建一個工作空間,但記得匯入邊檔案時要加入同一個工作空間
在 概況 -> 工作區 -> 外觀 中選擇你想要的外觀
在 概況 -> 工作區 -> 佈局 中選擇你想要的佈局,記得點執行
在 預覽 -> 預覽設定 -> 節點 中勾選 顯示標籤,選擇合適的字型字號
在 預覽 -> 預覽設定 -> 邊 中勾選 重新調整權重
為了美觀可以將邊箭頭尺寸調為零,最後選擇重新整理
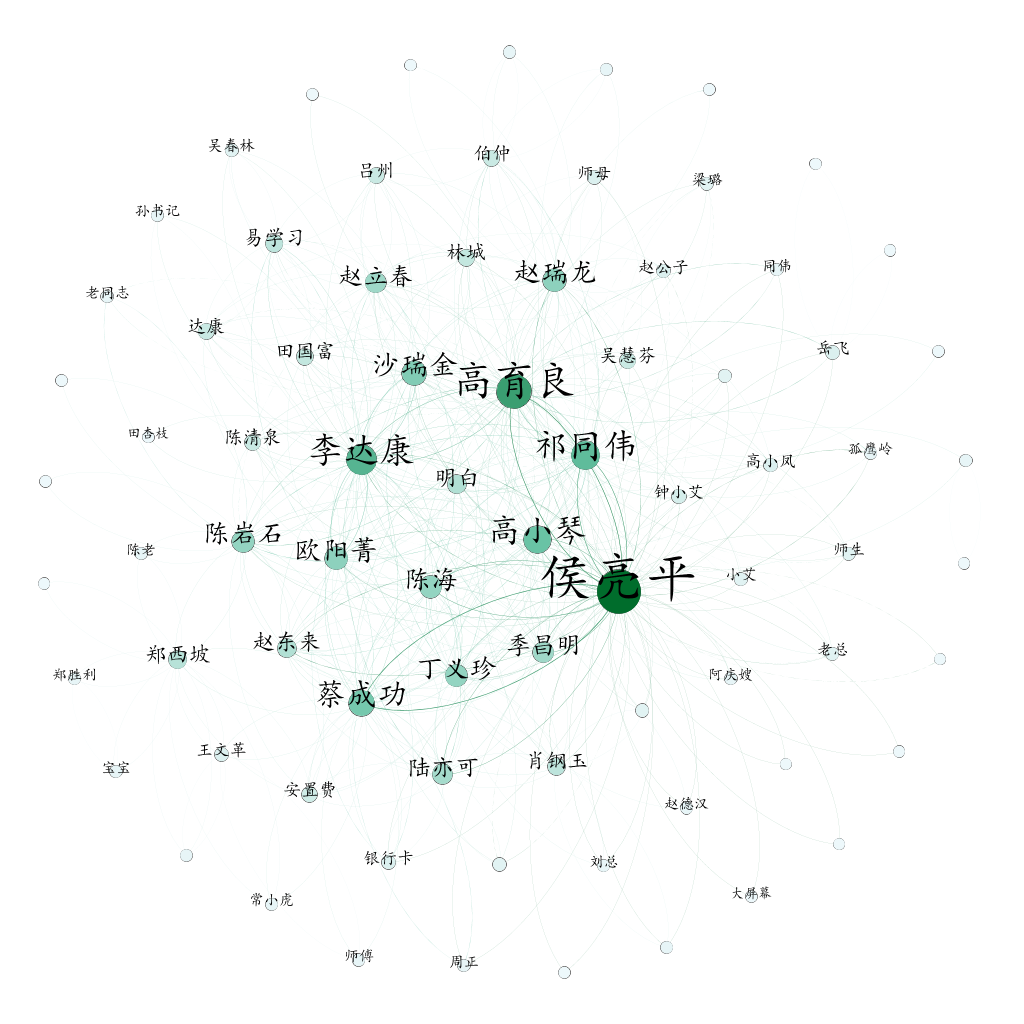
可以通過 檔案 -> 輸出 來輸出圖檔案,下面是筆者做出來的示例:
全部程式碼:
# -*- conding: utf-8 -*-
import codecs
import jieba.posseg as pseg
import jieba
# names : 儲存人物,鍵為人物名稱,值為該人物在全文中出現的次數
# relationship : 儲存人物關係的有向邊,鍵為有向邊的起點,值為一個字典 edge ,edge 的鍵為有向邊的終點,值是有向邊的權值,
# 代表兩個人物之間聯絡的緊密程度
# lineNames : 快取變數,儲存對每一段分詞得到當前段中出現的人物名稱
names = {}
relationships = {}
lineNames = []
jieba.load_userdict("RoleTable.txt")
with codecs.open("人民的名義.txt", 'r', 'utf8') as f:
for line in f.readlines(): # 注意是 readlines 要加s 不加s 只讀取一行
poss = pseg.cut(line) # 分詞,返回詞性
lineNames.append([]) # 為本段增加一個人物列表
for w in poss:
if w.flag != 'nr' or len(w.word) < 2:
continue # 當分詞長度小於2或該詞詞性不為nr(人名)時認為該詞不為人名
lineNames[-1].append(w.word) # 為當前段的環境增加一個人物
if names.get(w.word) is None: # 如果某人物(w.word)不在人物字典中
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1
# 輸出人物出現次數統計結果
# for name, times in names.items():
# print(name, times)
# 對於 lineNames 中每一行,我們為該行中出現的所有人物兩兩相連。如果兩個人物之間尚未有邊建立,則將新建的邊權值設為 1,
# 否則將已存在的邊的權值加 1。這種方法將產生很多的冗餘邊,這些冗餘邊將在最後處理。
for line in lineNames:
for name1 in line:
for name2 in line:
if name1 == name2:
continue
if relationships[name1].get(name2) is None:
relationships[name1][name2] = 1
else:
relationships[name1][name2] = relationships[name1][name2] + 1
# 由於分詞的不準確會出現很多不是人名的“人名”,從而導致出現很多冗餘邊,為此可設定閾值為10,即當邊出現10次以上則認為不是冗餘
with codecs.open("People_node.txt", "w", "utf8") as f:
f.write("ID Label Weight\r\n")
for name, times in names.items():
if times > 10:
f.write(name + " " + name + " " + str(times) + "\r\n")
with codecs.open("People_edge.txt", "w", "utf8") as f:
f.write("Source Target Weight\r\n")
for name, edges in relationships.items():
for v, w in edges.items():
if w > 10:
f.write(name + " " + v + " " + str(w) + "\r\n")