NLP實戰|如何用280多萬條豆瓣影評預測電影評分?

為了預測電影評分,我們收集了豆瓣電影網站上2.8萬名使用者對5萬多部電影的280萬條評論...
真實目的,其實是為了讓大家能夠通過這次的教程,更加了解自然語言處理。
所以,使用電影評論來預測電影評分,到底需要分幾步?

專案簡介
本專案只使用電影評論來預測電影評分。
由於豆瓣電影網站的評分為1-5的整數,因此將該問題轉化為5個輸出類別的分類問題。
資料集
此資料集包含豆瓣電影網站上2.8萬名使用者對5萬多部電影的280萬條評論。資料共有6列,包括使用者名稱,電影名,時間戳,電影評論,電影評分和評論被點贊數。
具體可在https://www.flyai.com 專案中查詢
專案過程
資料處理
搭建神經網路
定義損失函式,選擇優化器
訓練神經網路並儲存最優的網路
資料處理
為了將電影評論輸入到神經網路中,需要將原始的評論句子進行分詞,然後將詞轉化為詞向量。本專案使用了清華大學開發的thulac分詞器。要使用此分詞器,首先使用pip安裝thulac庫:

在python中建立分詞器例項,設定分詞器模式為僅分詞,對每條評論 (comment) 進行分詞:

將分好的詞與預處理的詞嵌入模型 (vocab) 比對,並獲得詞向量,詞向量維度為200。

為了使每個batch的輸入大小一致,需要對句子長度進行統一,設定句子最大長度為20,若句子長度超過20個詞則保留前20個詞,否則將空餘的詞補零。

輸入的評分 (rating) 為1-5的整型數字,而pytorch進行分類時,類別索引必須從0開始,因此對輸入評分做簡單處理:

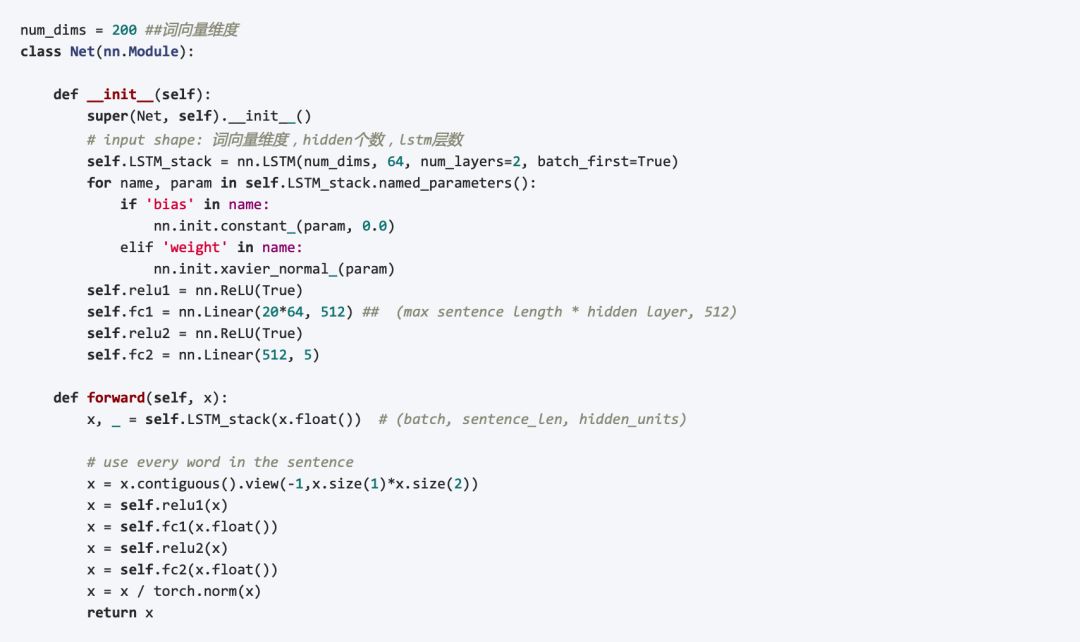
搭建神經網路
本專案使用了LSTM + 全連線層 來解決句子的分類問題。在PyTorch中搭建LSTM網路非常簡單,只需要定義輸入詞向量維度,LSTM隱單元個數,LSTM層數即可。在LSTM層後,使用兩個全連線層將LSTM輸出的所有整個句子對映到5個類別上:
定義損失函式和優化
由於此專案為分類問題,使用CrossEntropy交叉熵作為損失函式,並選用Adam優化器。設定學習速率為0.001。

訓練神經網路並儲存最優的網路
為了讓程式碼能夠同時在cpu和gpu上執行,首先判斷gpu是否可用,並由此設定pytorch計算所使用的硬體:

完整的訓練過程如下所示,當訓練集上準確率高於當前最高的準確率時,儲存當前網路模型:

其中,eval()的作用為計算訓練集上的準確率:

結語
本專案基於PyTorch框架,完成了根據漢語文字評論預測評分的任務。其中使用的網路簡單,高效,適合NLP初學者進行學習。
獲取更多相關專案程式碼 請訪問:https://www.flyai.com
— END —
完整程式碼請訪問:https://www.flyai.com/d/MovieRatings