
Web前後端快取技術
Web快取技術
一、快取概述
快取原本是一個硬體的概念:快取就是資料交換的緩衝區(稱作Cache),當某一硬體要讀取資料時,會首先從快取中查詢需要的資料,如果找到了則直接執行,找不到的話則從記憶體中找。由於快取的執行速度比記憶體快得多,故快取的作用就是幫助硬體更快地執行。
在一個Web應用中,應用到快取的地方有很多,主要有瀏覽器快取,頁面快取,伺服器快取,資料庫快取等。
快取的作用主要有:
- 加快頁面開啟速度
- 減少網路頻寬消耗
- 降低伺服器壓力
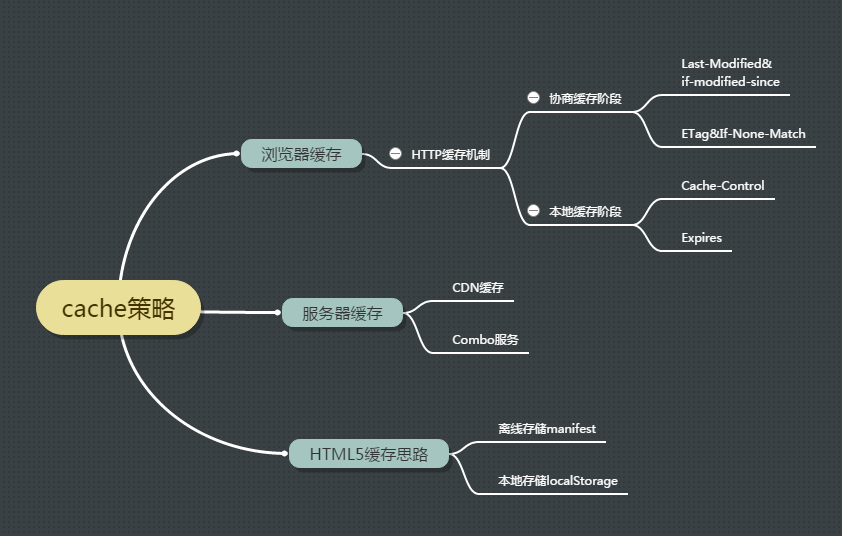
二、瀏覽器快取
瀏覽器端快取規則主要在HTTP協議頭和HTML的meta標籤中定義。他們分別從新鮮度和校驗值兩個維度來規定瀏覽器是否可以直接使用快取中的副本,還是需要去源伺服器獲取更新的版本。
新鮮度(過期機制):也就是快取副本有效期。一個快取副本必須滿足以下條件,瀏覽器會認為它是有效的,足夠新的:
- 含有完整的過期時間控制頭資訊(HTTP協議報頭),並且仍在有效期內;
- 瀏覽器已經使用過這個快取副本,並且在一個會話中已經檢查過新鮮度
- 滿足以上兩個情況的一種,瀏覽器會直接從快取中獲取副本並渲染。
滿足以上兩個情況的一種,瀏覽器會直接從快取中獲取副本並渲染。
校驗值(驗證機制):伺服器返回資源的時候有時在控制頭資訊帶上這個資源的實體標籤Etag(Entity Tag),它可以用來作為瀏覽器再次請求過程的校驗標識。如過發現校驗標識不匹配,說明資源已經被修改或過期,瀏覽器需求重新獲取資源內容。
使用HTML Meta 標籤,Web開發者可以在HTML頁面的<head>節點中加入<meta>標籤,程式碼如下:
<META HTTP-EQUIV="Pragma" CONTENT="no-cache">上述程式碼的作用是告訴瀏覽器當前頁面不被快取,每次訪問都需要去伺服器拉取。使用上很簡單,但只有部分瀏覽器可以支援,而且所有快取代理伺服器都不支援,因為代理不解析HTML內容本身。而廣泛應用的還是 HTTP頭資訊 來控制快取。
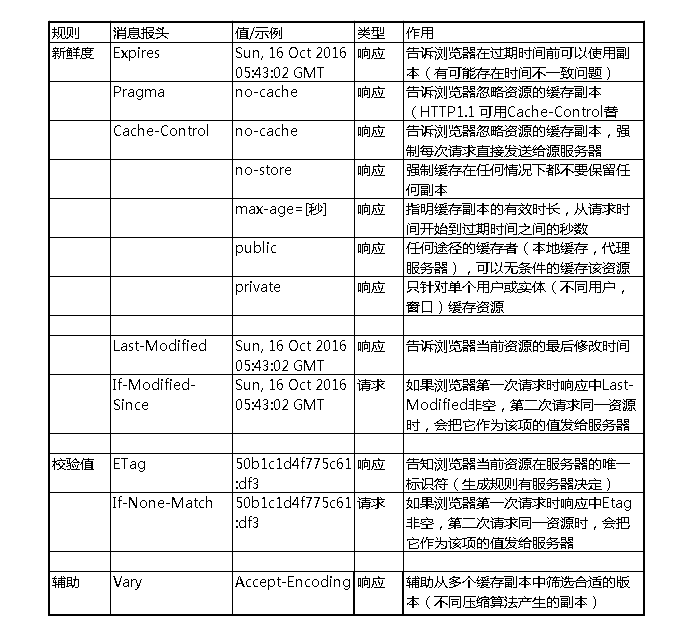
在HTTP請求和響應的訊息報頭中,常見的與快取有關的訊息報頭有:
HTTP快取機制
快取行為主要由快取策略決定,而快取策略由內容擁有者設定。這些策略主要通過特定的HTTP頭部來清晰地表達。
當一個使用者發起一個靜態資源請求的時候,瀏覽器會通過以下幾步來獲取資源:
- 本地快取階段:先在本地查詢該資源,如果有發現該資源,而且該資源還沒有過期,就使用這一個資源,完全不會發送http請求到伺服器;
- 協商快取階段:如果在本地快取找到對應的資源,但是不知道該資源是否過期或者已經過期,則發一個http請求到伺服器,然後伺服器判斷這個請求,如果請求的資源在伺服器上沒有改動過,則返回304,讓瀏覽器使用本地找到的那個資源;
- 快取失敗階段:當伺服器發現請求的資源已經修改過,或者這是一個新的請求(在本來沒有找到資源),伺服器則返回該資源的資料,並且返回200, 當然這個是指找到資源的情況下,如果伺服器上沒有這個資源,則返回404。
使用者操作行為與快取的關係
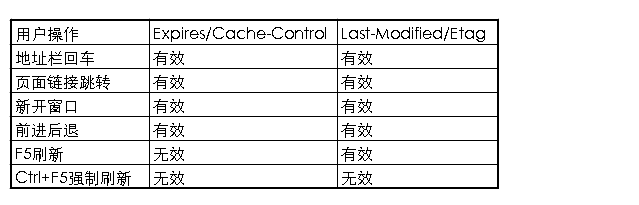
瀏覽器中的操作對快取的影響:
- 強制重新整理 – 當按下ctrl+F5來重新整理頁面的時候, 瀏覽器將繞過各種快取(本地快取和協商快取), 直接讓伺服器返回最新的資源;
- 普通重新整理 – 當按下F5或者點選重新整理按鈕來重新整理頁面的時候,瀏覽器將繞過本地快取來發送請求到伺服器, 此時, 協商快取是有效的
- 回車或轉向 – 當在位址列上輸入回車或者按下跳轉按鈕的時候, 所有快取都生效
本地快取階段
Expires
指定快取到期GMT的絕對時間,如果設了max-age,max-age就會覆蓋expires。如果expires到期需要重新請求。
Cache-Control
Cache-Control是http 1.1中為了彌補 Expires 缺陷新加入的。對已快取的內容進行控制:
- Cache-control: public表示快取的版本可以被代理伺服器或者其他中間伺服器識別。
- Cache-control: private意味著這個檔案對不同的使用者是不同的。只有使用者自己的瀏覽器能夠進行快取,公共的代理伺服器不允許快取。
- Cache-control: no-cache意味著檔案的內容不應當被快取。這在搜尋或者翻頁結果中非常有用,因為同樣的URL,對應的內容會發生變化。
其他相關控制欄位
- max-age: 指定快取過期的相對時間秒數,max-ag=0或者是負值,瀏覽器會在對應的快取中把Expires設定為1970-01-01 08:00:00。
- s-maxage: 類似於max-age,只用在共享快取上,比如proxy。
- public: 通常情況下需要http身份驗證的情況,響應是不可cahce的,加上public可以使它被cache。
- no-cache: 強制瀏覽器在使用cache拷貝之前先提交一個http請求到源伺服器進行確認。這對身份驗證來說是非常有用的,能比較好的遵守 (可以結合public進行考慮)。它對維持一個資源總是最新的也很有用,與此同時還不完全喪失cache帶來的好處),因為它在本地是有拷貝的,但是在用之前都進行了確認,這樣http請求並未減少,但可能會減少一個響應體。
- no-store: 告訴瀏覽器在任何情況下都不要進行cache,不在本地保留拷貝。
- must-revalidate: 強制瀏覽器嚴格遵守你設定的cache規則。
- proxy-revalidate: 強制proxy嚴格遵守你設定的cache規則。
- cache:使用本地快取,不發生請求。
用法舉例: Cache-Control: max-age=3600, must-revalidate
協商快取階段
Last-Modified & if-modified-since
Last-Modified與If-Modified-Since是一對報文頭,屬於http 1.0。
last-modified是WEB伺服器認為物件的最後修改時間,比如檔案的最後修改時間,動態頁面的最後產生時間。
ETag & If-None-Match
ETag與If-None-Match是一對報文,屬於http 1.1。
ETag可以用來解決這種問題。ETag是一個檔案的唯一標誌符。就像一個雜湊或者指紋,每個檔案都有一個單獨的標誌,只要這個檔案發生了改變,這個標誌就會發生變化。
ETag機制類似於樂觀鎖機制,如果請求報文的ETag與伺服器的不一致,則表示該資源已經被修改過,需要發最新的內容給瀏覽器。
同時使用這兩個報文頭,在完全匹配If-Modified-Since和If-None-Match即檢查完修改時間和Etag之後,如都與伺服器的相符,伺服器返回304,否則,傳送最新內容給瀏覽器。
Etag/lastModified過程如下:
- 客戶端請求一個頁面(A)。
- 伺服器返回頁面A,並在給A加上一個Last-Modified/ETag。
- 客戶端展現該頁面,並將頁面連同Last-Modified/ETag一起快取。
- 客戶再次請求頁面A,並將上次請求時伺服器返回的Last-Modified/ETag一起傳遞給伺服器。
- 伺服器檢查該Last-Modified或ETag,並判斷出該頁面自上次客戶端請求之後還未被修改,直接返回響應304和一個空的響應體。
304:通過If-Modified-Since If-Match判斷資源是否修改,如未修改則返回304,發生了一次請求,但請求內容長度為0,節省了頻寬。 如果有多臺負載均衡的伺服器,不同伺服器計算出的Etag可能不同,這樣就會造成資源的重複載入。
Etag 主要為了解決 Last-Modified 無法解決的一些問題:
1、一些檔案也許會週期性的更改,但是他的內容並不改變(僅僅改變的修改時間),這個時候我們並不希望客戶端認為這個檔案被修改了,而重新GET;
2、某些檔案修改非常頻繁,比如在秒以下的時間內進行修改,(比方說1s內修改了N次),If-Modified-Since能檢查到的粒度是s級的,這種修改無法判斷(或者說UNIX記錄MTIME只能精確到秒);
3、某些伺服器不能精確的得到檔案的最後修改時間。
其他標籤
Content-Length:儘管並沒有在快取中明確涉及,Content-Length頭部在設定快取策略時很重要。某些軟體如果不提前獲知內容的大小以留出足夠空間,則會拒絕快取該內容。
Vary:快取系統通常使用請求的主機和路徑作為儲存該資源的鍵。當判斷一個請求是否是請求同樣內容時,Vary頭部可以被用來提醒快取系統需要注意另一個附加頭部。它通常被用來告訴快取系統同樣注意Accept-Encoding頭部,以便快取系統能夠區分壓縮和未壓縮的內容。
總結
瀏覽器第一次請求時:
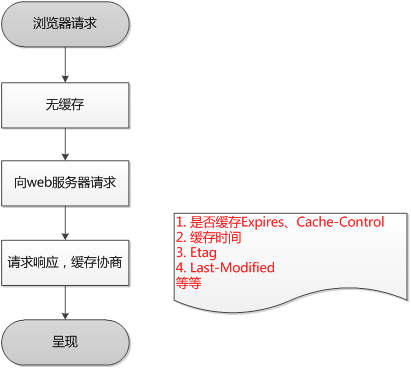
瀏覽器再次請求時:
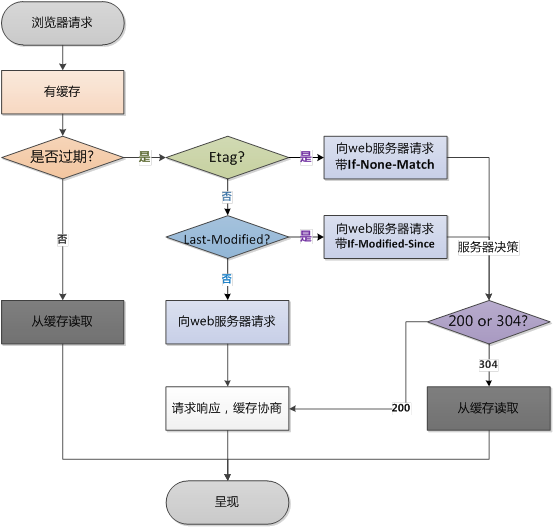
Question: 設定了一個月才過期的快取,如果伺服器端更新了css程式碼,要怎麼讓使用者更新快取呢?
三、頁面快取
頁面快取是將動態頁面直接生成靜態的頁面放在伺服器端,使用者調取相同頁面時,靜態頁面將直接下載到客戶端,不再需要通過程式的執行和資料庫的訪問,大大節約了伺服器的負載。每次訪問頁面時,會檢測相應的快取頁面是否存在,若不存在,則連線資料庫得到資料渲染頁面並生成快取頁面檔案,這樣下次訪問的頁面檔案就發揮作用了。
MemCache的快取策略:(visio不能用了,自己畫的,略醜慎看)
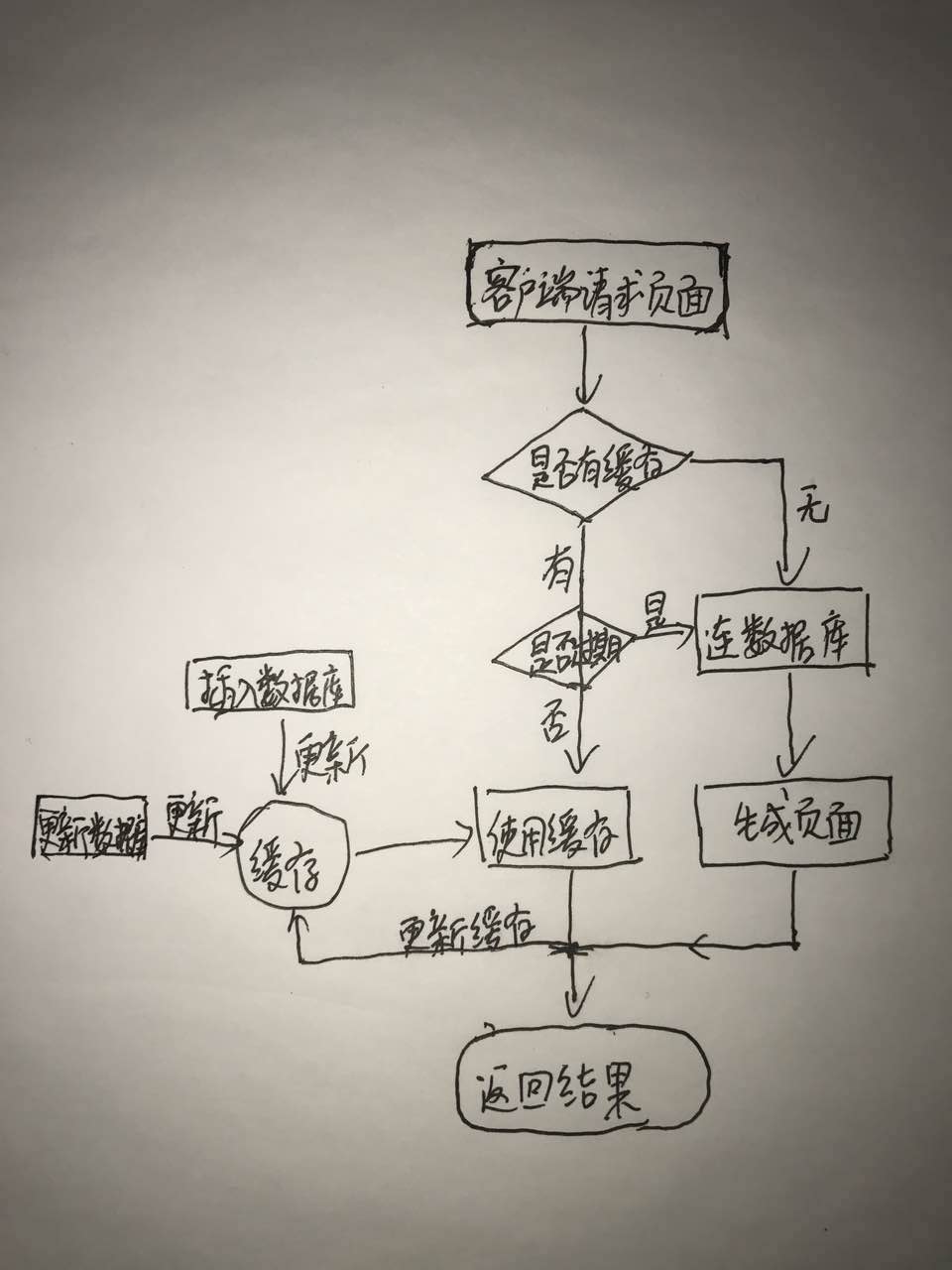
四、資料庫快取
資料庫的快取一般由資料庫提供,可以對錶建立快取記憶體。資料庫中,使用者可能多次執行相同的查詢語句,為了提高查詢效率,資料庫會在記憶體劃分一個專門的區域,用來存放使用者最近執行的查詢,這塊區域就是快取。
資料庫快取的使用必須在一定的應用環境下:查詢的資料庫表不會經常變動、有大量相同的查詢(如訂單資訊查詢)。
PS:這個快取策略也可以用在前端,比如訂單資訊不變的情況下,可以在前端設定一個物件,儲存請求的地址、引數、結果,第一次請求時會儲存請求的地址、引數和結果,再次請求時,如果請求的地址、引數一樣,則查詢該物件直接返回請求的結果。
五、快取的同步、複製與分發
快取的同步指的是寫命中快取的時候,如果保持快取與磁碟上資料一致性的問題。一般有兩種方案:
直寫式WT(Write Through):當CPU要將資料寫入記憶體時,除了更新緩衝記憶體上的資料外,也將資料寫在磁碟中以維持主存與緩衝記憶體的一致性,當要寫入記憶體的資料多起來的話,速度自然就慢了下來。回寫式WB(Write Back):當CPU要將資料寫入記憶體時,只會先更新緩衝記憶體上的資料,隨後再讓緩衝記憶體在匯流排不塞車的時候才把資料寫回磁碟,所以速度會快得多。
兩種方式各有利弊,直寫快取方法利用了快取記憶體中的資料始終與主儲存器中資料匹配的特點。但是,需要的匯流排週期卻非常耗時,從而降低效能。回寫快取可以維持效能,因為寫入始終是在“爆發”中進行的,因而執行所需的匯流排週期將大大減少。
兩個CPU,或者CPU與DMA同時共享一塊實體記憶體時,writer在寫完後,要write back,這樣另一個reader才能看到它寫入的資料;在writer變為reader的時候,需要invalidate,否則看不到另一個 writer寫入的資料。所以在共享的時候,需要同時做writeback和invalidate。
六、與快取相關的演算法
- 先進先出演算法(FIFO):如果一個數據最先進入快取中,則應該最早淘汰掉。如果伺服器接受到的資料請求與時間高度相關,可以考慮使用FIFO演算法。
- 最不經常使用演算法(LFU):這個快取演算法使用一個計數器來記錄條目被訪問的頻率。通過使用LFU快取演算法,最低訪問數的條目首先被移除。這個方法並不經常使用,因為它無法對一個擁有最初高訪問率之後長時間沒有被訪問的條目快取負責。
- 最近最少使用演算法(LRU):這個快取演算法將最近使用的條目存放到靠近快取頂部的位置。當一個新條目被訪問時,LRU將它放置到快取的頂部。當快取達到極限時,較早之前訪問的條目將從快取底部開始被移除。這裡會使用到昂貴的演算法,而且它需要記錄“年齡位”來精確顯示條目是何時被訪問的。此外,當一個LRU快取演算法刪除某個條目後,“年齡位”將隨其他條目發生改變。
- 自適應快取替換演算法(ARC):在IBM Almaden研究中心開發,這個快取演算法同時跟蹤記錄LFU和LRU,以及驅逐快取條目,來獲得可用快取的最佳使用。
- 最近最常使用演算法(MRU):這個快取演算法最先移除最近最常使用的條目。一個MRU演算法擅長處理一個條目越久,越容易被訪問的情況。
應用:圖片快取的預載與分發
圖片的預載入
為了防止圖片在需要的時候才載入,而付出的時間開銷,可以將圖片進行預載入。程式碼如下:
<html>
<script>
var img = new Image();
image.src = "b.jpg";
</script>
<body>
<img src="a.jpg" alt="pic" onmouseover="this.src='b.jpg'">
</body>
</html>圖片的分發
網頁傳輸過程中,圖片會佔用大量的資料量,是影響網站效能的主要因素,因此大部分網站會將圖片儲存從網站中分離出來,假設一個或多個圖片伺服器來儲存圖片,將圖片放到一個虛擬目錄中,而網頁上仍然用同一個URL地址指向伺服器上的某一個圖片的地址。這樣可以大大提高網站的效能。