
深度學習小trick收集
梯度消失/梯度爆炸的解決方案
首先,梯度消失與梯度爆炸的根本原因是基於bp的反向傳播演算法

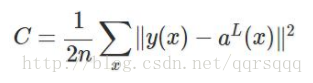


且上述的反向傳播錯誤小於1/4
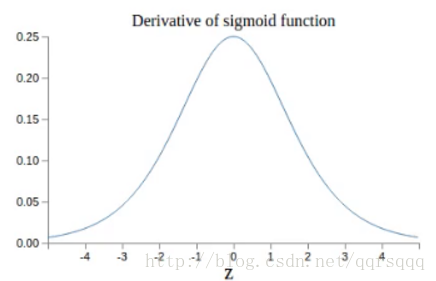
總的來說就是,更新w和b的時候,更新的步長與learningrate成正比,當所處的層數越淺,每層的w的值和反向傳播錯誤的值乘的愈多,導致w和b更新的步長收到很大影響,最終導致梯度爆炸或者梯度消失。這時候深度網路並不能比千層網路效能好。後面基層學習情況好,而淺層網路則學不到東西。sigmoid網路中存在指數級的梯度消失。
策略大概有以下幾種。
每層網路以不同的學習率進行學習
更換啟用函式
使用relu啟用函式,簡化計算,且解決梯度消失問題,並且一部分神經元輸出為0,可以使網路具有稀疏性,減少引數的依存關係,緩解過擬合的發生。
使用batch normolization
訓練網路前需要對資料做歸一化處理。用處在於:神經網路本質是學習資料分佈,如果尋來你資料與測試資料分佈不同,網路的泛化能力將降低,且在每一批訓練資料不同的情況下,網路的訓練速度會降低。
batch normolization可以解決梯度消失問題,使得不同層不同scale的權重變化整體步調更一致,也可以加快訓練速度。放在每一層網路的非線性對映前,即放在啟用函式之前。
區域性最優解怎麼辦
模擬退火
加入momentum項
不收斂怎麼回事,怎麼解決
資料太少
learningrate過大
可能導致從一開始就不收斂,每一層的w都很大,或者跑著跑著loss突然變得很大(一般是因為網路的前面使用relu作為啟用函式而最後一層使用softmax作為分類的函式導致)
網路結構不好
更換其他的最優化演算法
我做試驗的時候遇到過一次,adam不收斂,用最簡單的sgd收斂了。。具體原因不詳
對引數做歸一化
就是將輸入歸一化到均值為0方差為1然後使用BN等
初始化
改一種初始化的方案
過擬合
增加訓練集的資料量
影象的話可以平移反轉加噪聲
使用relu啟用函式
dropout
每次迭代訓練隨機選取一部分節點進行訓練和權重更新,另一部分權重保持不變。在測試時,使用mean network網路獲得輸出。
正則化
也是為了簡化網路,加入l2範數
提前終止訓練
怎樣提升效果?/或許有欠擬合
增加特徵數量
本來輸入只有座標位置,欠擬合後再增加一個顏色特徵
減少正則化項的引數