
十三、REDIS的資料結構以及應用場景
1、顯示最新的專案列表 2、刪除與過濾 3、排行榜相關 4、按照使用者投票和時間排序 5、處理過期專案 6、計數 7、特定時間內的特定專案 8、實時分析正在發生的情況,用於資料統計與防止垃圾郵件等 9、Pub/Sub 10、佇列 11、快取
1. MySql+Memcached架構的問題
實際MySQL是適合進行海量資料儲存的,通過Memcached將熱點資料載入到cache,加速訪問,很多公司都曾經使用過這樣的架構,但隨著業務資料量的不斷增加,和訪問量的持續增長,我們遇到了很多問題:
1.MySQL需要不斷進行拆庫拆表,Memcached也需不斷跟著擴容,擴容和維護工作佔據大量開發時間。
2.Memcached與MySQL資料庫資料一致性問題。
3.Memcached資料命中率低或down機,大量訪問直接穿透到DB,MySQL無法支撐。
4.跨機房cache同步問題。
眾多NoSQL百花齊放,如何選擇
最近幾年,業界不斷湧現出很多各種各樣的NoSQL產品,那麼如何才能正確地使用好這些產品,最大化地發揮其長處,是我們需要深入研究和思考的問題,實際歸根結底最重要的是瞭解這些產品的定位,並且瞭解到每款產品的tradeoffs,在實際應用中做到揚長避短,總體上這些NoSQL主要用於解決以下幾種問題
1.少量資料儲存,高速讀寫訪問。此類產品通過資料全部in-momery 的方式來保證高速訪問,同時提供資料落地的功能,實際這正是Redis最主要的適用場景。
2.海量資料儲存,分散式系統支援,資料一致性保證,方便的叢集節點新增/刪除。
3.這方面最具代表性的是dynamo和bigtable 2篇論文所闡述的思路。前者是一個完全無中心的設計,節點之間通過gossip方式傳遞叢集資訊,資料保證最終一致性,後者是一箇中心化的方案設計,通過類似一個分散式鎖服務來保證強一致性,資料寫入先寫記憶體和redo log,然後定期compat歸併到磁碟上,將隨機寫優化為順序寫,提高寫入效能。
4.Schema free,auto-sharding等。比如目前常見的一些文件資料庫都是支援schema-free的,直接儲存json格式資料,並且支援auto-sharding等功能,比如mongodb。
面對這些不同型別的NoSQL產品,我們需要根據我們的業務場景選擇最合適的產品。
Redis最適合所有資料in-momory的場景,雖然Redis也提供持久化功能,但實際更多的是一個disk-backed的功能,跟傳統意義上的持久化有比較大的差別,那麼可能大家就會有疑問,似乎Redis更像一個加強版的Memcached,那麼何時使用Memcached,何時使用Redis呢?
如果簡單地比較Redis與Memcached的區別,大多數都會得到以下觀點:
1 、Redis不僅僅支援簡單的k/v型別的資料,同時還提供list,set,zset,hash等資料結構的儲存。
2 、Redis支援資料的備份,即master-slave模式的資料備份。
3 、Redis支援資料的持久化,可以將記憶體中的資料保持在磁碟中,重啟的時候可以再次載入進行使用。
2. Redis常用資料型別
Redis最為常用的資料型別主要有以下:
-
String
-
Hash
-
List
-
Set
-
Sorted set
-
pub/sub
-
Transactions
在具體描述這幾種資料型別之前,我們先通過一張圖瞭解下Redis內部記憶體管理中是如何描述這些不同資料型別的:
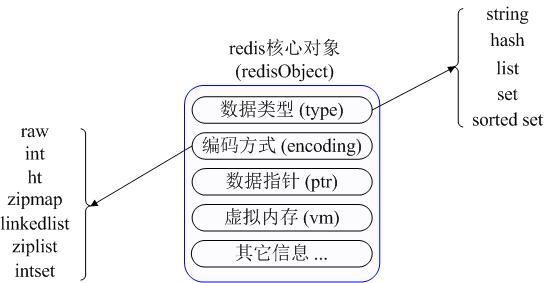
首先Redis內部使用一個redisObject物件來表示所有的key和value,redisObject最主要的資訊如上圖所示:
type代表一個value物件具體是何種資料型別,
encoding是不同資料型別在redis內部的儲存方式,
比如:type=string代表value儲存的是一個普通字串,那麼對應的encoding可以是raw或者是int,如果是int則代表實際redis內部是按數值型類儲存和表示這個字串的,當然前提是這個字串本身可以用數值表示,比如:"123" "456"這樣的字串。
這裡需要特殊說明一下vm欄位,只有打開了Redis的虛擬記憶體功能,此欄位才會真正的分配記憶體,該功能預設是關閉狀態的,該功能會在後面具體描述。通過上圖我們可以發現Redis使用redisObject來表示所有的key/value資料是比較浪費記憶體的,當然這些記憶體管理成本的付出主要也是為了給Redis不同資料型別提供一個統一的管理介面,實際作者也提供了多種方法幫助我們儘量節省記憶體使用,我們隨後會具體討論。
3. 各種資料型別應用和實現方式
下面我們先來逐一的分析下這7種資料型別的使用和內部實現方式:
-
String:
Strings 資料結構是簡單的key-value型別,value其實不僅是String,也可以是數字.
常用命令: set,get,decr,incr,mget 等。
應用場景:String是最常用的一種資料型別,普通的key/ value 儲存都可以歸為此類.即可以完全實現目前 Memcached 的功能,並且效率更高。還可以享受Redis的定時持久化,操作日誌及 Replication等功能。除了提供與 Memcached 一樣的get、set、incr、decr 等操作外,Redis還提供了下面一些操作:
-
-
獲取字串長度
-
往字串append內容
-
設定和獲取字串的某一段內容
-
設定及獲取字串的某一位(bit)
-
批量設定一系列字串的內容
-
實現方式:String在redis內部儲存預設就是一個字串,被redisObject所引用,當遇到incr,decr等操作時會轉成數值型進行計算,此時redisObject的encoding欄位為int。
-
Hash
常用命令:hget,hset,hgetall 等。
應用場景:在Memcached中,我們經常將一些結構化的資訊打包成HashMap,在客戶端序列化後儲存為一個字串的值,比如使用者的暱稱、年齡、性別、積分等,這時候在需要修改其中某一項時,通常需要將所有值取出反序列化後,修改某一項的值,再序列化儲存回去。這樣不僅增大了開銷,也不適用於一些可能併發操作的場合(比如兩個併發的操作都需要修改積分)。而Redis的Hash結構可以使你像在資料庫中Update一個屬性一樣只修改某一項屬性值。
我們簡單舉個例項來描述下Hash的應用場景,比如我們要儲存一個使用者資訊物件資料,包含以下資訊:
使用者ID為查詢的key,儲存的value使用者物件包含姓名,年齡,生日等資訊,如果用普通的key/value結構來儲存,主要有以下2種儲存方式:
第一種方式將使用者ID作為查詢key,把其他資訊封裝成一個物件以序列化的方式儲存,這種方式的缺點是,增加了序列化/反序列化的開銷,並且在需要修改其中一項資訊時,需要把整個物件取回,並且修改操作需要對併發進行保護,引入CAS等複雜問題。
第二種方法是這個使用者資訊物件有多少成員就存成多少個key-value對兒,用使用者ID+對應屬性的名稱作為唯一標識來取得對應屬性的值,雖然省去了序列化開銷和併發問題,但是使用者ID為重複儲存,如果存在大量這樣的資料,記憶體浪費還是非常可觀的。
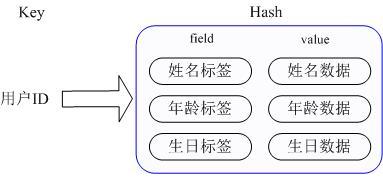
那麼Redis提供的Hash很好的解決了這個問題,Redis的Hash實際是內部儲存的Value為一個HashMap,並提供了直接存取這個Map成員的介面,如下圖:
也就是說,Key仍然是使用者ID, value是一個Map,這個Map的key是成員的屬性名,value是屬性值,這樣對資料的修改和存取都可以直接通過其內部Map的Key(Redis裡稱內部Map的key為field), 也就是通過 key(使用者ID) + field(屬性標籤) 就可以操作對應屬性資料了,既不需要重複儲存資料,也不會帶來序列化和併發修改控制的問題。很好的解決了問題。
這裡同時需要注意,Redis提供了介面(hgetall)可以直接取到全部的屬性資料,但是如果內部Map的成員很多,那麼涉及到遍歷整個內部Map的操作,由於Redis單執行緒模型的緣故,這個遍歷操作可能會比較耗時,而另其它客戶端的請求完全不響應,這點需要格外注意。
實現方式:
上面已經說到Redis Hash對應Value內部實際就是一個HashMap,實際這裡會有2種不同實現,這個Hash的成員比較少時Redis為了節省記憶體會採用類似一維陣列的方式來緊湊儲存,而不會採用真正的HashMap結構,對應的value redisObject的encoding為zipmap,當成員數量增大時會自動轉成真正的HashMap,此時encoding為ht。


-
List
常用命令:lpush,rpush,lpop,rpop,lrange等。
應用場景:
Redis list的應用場景非常多,也是Redis最重要的資料結構之一,比如twitter的關注列表,粉絲列表等都可以用Redis的list結構來實現。
Lists 就是連結串列,相信略有資料結構知識的人都應該能理解其結構。使用Lists結構,我們可以輕鬆地實現最新訊息排行等功能。Lists的另一個應用就是訊息佇列,
可以利用Lists的PUSH操作,將任務存在Lists中,然後工作執行緒再用POP操作將任務取出進行執行。Redis還提供了操作Lists中某一段的api,你可以直接查詢,刪除Lists中某一段的元素。實現方式:
Redis list的實現為一個雙向連結串列,即可以支援反向查詢和遍歷,更方便操作,不過帶來了部分額外的記憶體開銷,Redis內部的很多實現,包括髮送緩衝佇列等也都是用的這個資料結構。
-
Set
常用命令:
sadd,spop,smembers,sunion 等。
應用場景:
Redis set對外提供的功能與list類似是一個列表的功能,特殊之處在於set是可以自動排重的,當你需要儲存一個列表資料,又不希望出現重複資料時,set是一個很好的選擇,並且set提供了判斷某個成員是否在一個set集合內的重要介面,這個也是list所不能提供的。
Sets 集合的概念就是一堆不重複值的組合。利用Redis提供的Sets資料結構,可以儲存一些集合性的資料,比如在微博應用中,可以將一個使用者所有的關注人存在一個集合中,將其所有粉絲存在一個集合。Redis還為集合提供了求交集、並集、差集等操作,可以非常方便的實現如共同關注、共同喜好、二度好友等功能,對上面的所有集合操作,你還可以使用不同的命令選擇將結果返回給客戶端還是存集到一個新的集合中。
實現方式:
set 的內部實現是一個 value永遠為null的HashMap,實際就是通過計算hash的方式來快速排重的,這也是set能提供判斷一個成員是否在集合內的原因。
-
Sorted Set
常用命令:
zadd,zrange,zrem,zcard等
使用場景:
Redis sorted set的使用場景與set類似,區別是set不是自動有序的,而sorted set可以通過使用者額外提供一個優先順序(score)的引數來為成員排序,並且是插入有序的,即自動排序。當你需要一個有序的並且不重複的集合列表,那麼可以選擇sorted set資料結構,比如twitter 的public timeline可以以發表時間作為score來儲存,這樣獲取時就是自動按時間排好序的。
另外還可以用Sorted Sets來做帶權重的佇列,比如普通訊息的score為1,重要訊息的score為2,然後工作執行緒可以選擇按score的倒序來獲取工作任務。讓重要的任務優先執行。
實現方式:
Redis sorted set的內部使用HashMap和跳躍表(SkipList)來保證資料的儲存和有序,HashMap裡放的是成員到score的對映,而跳躍表裡存放的是所有的成員,排序依據是HashMap裡存的score,使用跳躍表的結構可以獲得比較高的查詢效率,並且在實現上比較簡單。
-
Pub/Sub
Pub/Sub 從字面上理解就是釋出(Publish)與訂閱(Subscribe),在Redis中,你可以設定對某一個key值進行訊息釋出及訊息訂閱,當一個key值上進行了訊息釋出後,所有訂閱它的客戶端都會收到相應的訊息。這一功能最明顯的用法就是用作實時訊息系統,比如普通的即時聊天,群聊等功能。
-
Transactions
誰說NoSQL都不支援事務,雖然Redis的Transactions提供的並不是嚴格的ACID的事務(比如一串用EXEC提交執行的命令,在執行中伺服器宕機,那麼會有一部分命令執行了,剩下的沒執行),但是這個Transactions還是提供了基本的命令打包執行的功能(在伺服器不出問題的情況下,可以保證一連串的命令是順序在一起執行的,中間有會有其它客戶端命令插進來執行)。Redis還提供了一個Watch功能,你可以對一個key進行Watch,然後再執行Transactions,在這過程中,如果這個Watched的值進行了修改,那麼這個Transactions會發現並拒絕執行。
4. Redis實際應用場景
Redis在很多方面與其他資料庫解決方案不同:它使用記憶體提供主儲存支援,而僅使用硬碟做永續性的儲存;它的資料模型非常獨特,用的是單執行緒。另一個大區別在於,你可以在開發環境中使用Redis的功能,但卻不需要轉到Redis。
轉向Redis當然也是可取的,許多開發者從一開始就把Redis作為首選資料庫;但設想如果你的開發環境已經搭建好,應用已經在上面運行了,那麼更換資料庫框架顯然不那麼容易。另外在一些需要大容量資料集的應用,Redis也並不適合,因為它的資料集不會超過系統可用的記憶體。所以如果你有大資料應用,而且主要是讀取訪問模式,那麼Redis並不是正確的選擇。
然而我喜歡Redis的一點就是你可以把它融入到你的系統中來,這就能夠解決很多問題,比如那些你現有的資料庫處理起來感到緩慢的任務。這些你就可以通過Redis來進行優化,或者為應用建立些新的功能。在本文中,我就想探討一些怎樣將Redis加入到現有的環境中,並利用它的原語命令等功能來解決 傳統環境中碰到的一些常見問題。在這些例子中,Redis都不是作為首選資料庫。
1、顯示最新的專案列表
下面這個語句常用來顯示最新專案,隨著資料多了,查詢毫無疑問會越來越慢。
-
SELECT * FROM foo WHERE ... ORDER BY time DESC LIMIT 10
在Web應用中,“列出最新的回覆”之類的查詢非常普遍,這通常會帶來可擴充套件性問題。這令人沮喪,因為專案本來就是按這個順序被建立的,但要輸出這個順序卻不得不進行排序操作。
類似的問題就可以用Redis來解決。比如說,我們的一個Web應用想要列出使用者貼出的最新20條評論。在最新的評論邊上我們有一個“顯示全部”的連結,點選後就可以獲得更多的評論。
我們假設資料庫中的每條評論都有一個唯一的遞增的ID欄位。
我們可以使用分頁來製作主頁和評論頁,使用Redis的模板,每次新評論發表時,我們會將它的ID新增到一個Redis列表:
-
LPUSH latest.comments <ID>
我們將列表裁剪為指定長度,因此Redis只需要儲存最新的5000條評論:
LTRIM latest.comments 0 5000
每次我們需要獲取最新評論的專案範圍時,我們呼叫一個函式來完成(使用虛擬碼):
-
FUNCTION get_latest_comments(start, num_items):
-
id_list = redis.lrange("latest.comments",start,start+num_items - 1)
-
IF id_list.length < num_items
-
id_list = SQL_DB("SELECT ... ORDER BY time LIMIT ...")
-
END
-
RETURN id_list
-
END
這裡我們做的很簡單。在Redis中我們的最新ID使用了常駐快取,這是一直更新的。但是我們做了限制不能超過5000個ID,因此我們的獲取ID函式會一直詢問Redis。只有在start/count引數超出了這個範圍的時候,才需要去訪問資料庫。
我們的系統不會像傳統方式那樣“重新整理”快取,Redis例項中的資訊永遠是一致的。SQL資料庫(或是硬碟上的其他型別資料庫)只是在使用者需要獲取“很遠”的資料時才會被觸發,而主頁或第一個評論頁是不會麻煩到硬碟上的資料庫了。
2、刪除與過濾
我們可以使用LREM來刪除評論。如果刪除操作非常少,另一個選擇是直接跳過評論條目的入口,報告說該評論已經不存在。
有些時候你想要給不同的列表附加上不同的過濾器。如果過濾器的數量受到限制,你可以簡單的為每個不同的過濾器使用不同的Redis列表。畢竟每個列表只有5000條專案,但Redis卻能夠使用非常少的記憶體來處理幾百萬條專案。
3、排行榜相關
另一個很普遍的需求是各種資料庫的資料並非儲存在記憶體中,因此在按得分排序以及實時更新這些幾乎每秒鐘都需要更新的功能上資料庫的效能不夠理想。
典型的比如那些線上遊戲的排行榜,比如一個Facebook的遊戲,根據得分你通常想要:
- 列出前100名高分選手
- 列出某使用者當前的全球排名
這些操作對於Redis來說小菜一碟,即使你有幾百萬個使用者,每分鐘都會有幾百萬個新的得分。
模式是這樣的,每次獲得新得分時,我們用這樣的程式碼:
ZADD leaderboard <score> <username>
你可能用userID來取代username,這取決於你是怎麼設計的。
得到前100名高分使用者很簡單:ZREVRANGE leaderboard 0 99。
使用者的全球排名也相似,只需要:ZRANK leaderboard <username>。
4、按照使用者投票和時間排序
排行榜的一種常見變體模式就像Reddit或Hacker News用的那樣,新聞按照類似下面的公式根據得分來排序:
score = points / time^alpha
因此使用者的投票會相應的把新聞挖出來,但時間會按照一定的指數將新聞埋下去。下面是我們的模式,當然演算法由你決定。
模式是這樣的,開始時先觀察那些可能是最新的專案,例如首頁上的1000條新聞都是候選者,因此我們先忽視掉其他的,這實現起來很簡單。
每次新的新聞貼上來後,我們將ID新增到列表中,使用LPUSH + LTRIM,確保只取出最新的1000條專案。
有一項後臺任務獲取這個列表,並且持續的計算這1000條新聞中每條新聞的最終得分。計算結果由ZADD命令按照新的順序填充生成列表,老新聞則被清除。這裡的關鍵思路是排序工作是由後臺任務來完成的。
5、處理過期專案
另一種常用的專案排序是按照時間排序。我們使用unix時間作為得分即可。
模式如下:
- 每次有新專案新增到我們的非Redis資料庫時,我們把它加入到排序集合中。這時我們用的是時間屬性,current_time和time_to_live。
- 另一項後臺任務使用ZRANGE…SCORES查詢排序集合,取出最新的10個專案。如果發現unix時間已經過期,則在資料庫中刪除條目。
6、計數
Redis是一個很好的計數器,這要感謝INCRBY和其他相似命令。
我相信你曾許多次想要給資料庫加上新的計數器,用來獲取統計或顯示新資訊,但是最後卻由於寫入敏感而不得不放棄它們。
好了,現在使用Redis就不需要再擔心了。有了原子遞增(atomic increment),你可以放心的加上各種計數,用GETSET重置,或者是讓它們過期。
例如這樣操作:
INCR user:<id> EXPIRE
user:<id> 60
你可以計算出最近使用者在頁面間停頓不超過60秒的頁面瀏覽量,當計數達到比如20時,就可以顯示出某些條幅提示,或是其它你想顯示的東西。
7、特定時間內的特定專案
另一項對於其他資料庫很難,但Redis做起來卻輕而易舉的事就是統計在某段特點時間裡有多少特定使用者訪問了某個特定資源。比如我想要知道某些特定的註冊使用者或IP地址,他們到底有多少訪問了某篇文章。
每次我獲得一次新的頁面瀏覽時我只需要這樣做:
SADD page:day1:<page_id> <user_id>
當然你可能想用unix時間替換day1,比如time()-(time()%3600*24)等等。
想知道特定使用者的數量嗎?只需要使用SCARD page:day1:<page_id>。
需要測試某個特定使用者是否訪問了這個頁面?SISMEMBER page:day1:<page_id>。
8、實時分析正在發生的情況,用於資料統計與防止垃圾郵件等
我們只做了幾個例子,但如果你研究Redis的命令集,並且組合一下,就能獲得大量的實時分析方法,有效而且非常省力。使用Redis原語命令,更容易實施垃圾郵件過濾系統或其他實時跟蹤系統。
9、Pub/Sub
Redis的Pub/Sub非常非常簡單,執行穩定並且快速。支援模式匹配,能夠實時訂閱與取消頻道。
10、佇列
你應該已經注意到像list push和list pop這樣的Redis命令能夠很方便的執行佇列操作了,但能做的可不止這些:比如Redis還有list pop的變體命令,能夠在列表為空時阻塞佇列。
現代的網際網路應用大量地使用了訊息佇列(Messaging)。訊息佇列不僅被用於系統內部元件之間的通訊,同時也被用於系統跟其它服務之間的互動。訊息佇列的使用可以增加系統的可擴充套件性、靈活性和使用者體驗。非基於訊息佇列的系統,其執行速度取決於系統中最慢的元件的速度(注:短板效應)。而基於訊息佇列可以將系統中各元件解除耦合,這樣系統就不再受最慢元件的束縛,各元件可以非同步執行從而得以更快的速度完成各自的工作。
此外,當伺服器處在高併發操作的時候,比如頻繁地寫入日誌檔案。可以利用訊息佇列實現非同步處理。從而實現高效能的併發操作。
11、快取
Redis的快取部分值得寫一篇新文章,我這裡只是簡單的說一下。Redis能夠替代memcached,讓你的快取從只能儲存資料變得能夠更新資料,因此你不再需要每次都重新生成資料了。