
十四、跳躍表詳解
跳躍表
跳躍表(skiplist)是一種隨機化的資料,其實就是給順序單鏈表加了多個索引,高層次的索引跳躍節點數大於等於低層的,在。 由 William Pugh 在論文《Skip lists: a probabilistic alternative to balanced trees》中提出, 跳躍表以有序的方式在層次化的連結串列中儲存元素, 效率和平衡樹媲美 —— 查詢、刪除、新增等操作都可以在對數期望時間下完成, 並且比起平衡樹來說, 跳躍表的實現要簡單直觀得多。
以下是個典型的跳躍表例子(圖片來自維基百科):
{kind=link}
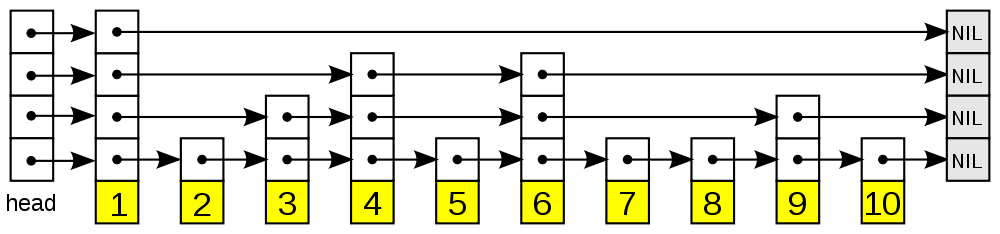
從圖中可以看到, 跳躍表主要由以下部分構成:
- 表頭(head):負責維護跳躍表的節點指標。
- 跳躍表節點:儲存著元素值,以及多個層。
- 層:儲存著指向其他元素的指標。高層的指標越過的元素數量大於等於低層的指標,為了提高查詢的效率,程式總是從高層先開始訪問,然後隨著元素值範圍的縮小,慢慢降低層次。
- 表尾:全部由
NULL組成,表示跳躍表的末尾。
因為跳躍表的定義可以在任何一本演算法或資料結構的書中找到, 所以本章不介紹跳躍表的具體實現方式或者具體的演算法, 而只介紹跳躍表在 Redis 的應用、核心資料結構和 API 。
跳躍表的實現
為了滿足自身的功能需要, Redis 基於 William Pugh 論文中描述的跳躍表進行了以下修改:
- 允許重複的
score值:多個不同的member的score值可以相同。 - 進行對比操作時,不僅要檢查
score值,還要檢查member:當score值可以重複時,單靠score值無法判斷一個元素的身份,所以需要連member域都一併檢查才行。 - 每個節點都帶有一個高度為 1 層的後退指標,用於從表尾方向向表頭方向迭代:當執行 ZREVRANGE 或 ZREVRANGEBYSCORE這類以逆序處理有序集的命令時,就會用到這個屬性。
這個修改版的跳躍表由 redis.h/zskiplist 結構定義:
typedef struct zskiplist {
// 頭節點,尾節點
struct zskiplistNode *header, *tail;
// 節點數量
unsigned long length;
// 目前表內節點的最大層數
int level;
} zskiplist;
跳躍表的節點由 redis.h/zskiplistNode 定義:
typedef struct zskiplistNode {
// member 物件
robj *obj;
// 分值
double score;
// 後退指標
struct zskiplistNode *backward;
// 層
struct zskiplistLevel {
// 前進指標
struct zskiplistNode *forward;
// 這個層跨越的節點數量
unsigned int span;
} level[];
} zskiplistNode;
以下是操作這兩個資料結構的 API ,API 的用途與相應的演算法複雜度:
| 函式 | 作用 | 複雜度 |
|---|---|---|
zslCreateNode |
建立並返回一個新的跳躍表節點 | 最壞 O(1)O(1) |
zslFreeNode |
釋放給定的跳躍表節點 | 最壞 O(1)O(1) |
zslCreate |
建立並初始化一個新的跳躍表 | 最壞 O(1)O(1) |
zslFree |
釋放給定的跳躍表 | 最壞 O(N)O(N) |
zslInsert |
將一個包含給定 score 和 member 的新節點新增到跳躍表中 |
最壞 O(N)O(N) 平均 O(logN)O(logN) |
zslDeleteNode |
刪除給定的跳躍表節點 | 最壞 O(N)O(N) |
zslDelete |
刪除匹配給定 member 和 score 的元素 |
最壞 O(N)O(N) 平均 O(logN)O(logN) |
zslFirstInRange |
找到跳躍表中第一個符合給定範圍的元素 | 最壞 O(N)O(N) 平均 O(logN)O(logN) |
zslLastInRange |
找到跳躍表中最後一個符合給定範圍的元素 | 最壞 O(N)O(N) 平均 O(logN)O(logN) |
zslDeleteRangeByScore |
刪除 score 值在給定範圍內的所有節點 |
最壞 O(N2)O(N2) |
zslDeleteRangeByRank |
刪除給定排序範圍內的所有節點 | 最壞 O(N2)O(N2) |
zslGetRank |
返回目標元素在有序集中的排位 | 最壞 O(N)O(N) 平均 O(logN)O(logN) |
zslGetElementByRank |
根據給定排位,返回該排位上的元素節點 | 最壞 O(N)O(N) 平均 O(logN)O(logN) |
跳躍表的應用
和字典、連結串列或者字串這幾種在 Redis 中大量使用的資料結構不同, 跳躍表在 Redis 的唯一作用, 就是實現有序集資料型別。
跳躍表將指向有序集的 score 值和 member 域的指標作為元素, 並以 score 值為索引, 對有序集元素進行排序。
舉個例子, 以下程式碼建立了一個帶有 3 個元素的有序集:
redis> ZADD s 6 x 10 y 15 z (integer) 3 redis> ZRANGE s 0 -1 WITHSCORES 1) "x" 2) "6" 3) "y" 4) "10" 5) "z" 6) "15"
在底層實現中, Redis 為 x 、 y 和 z 三個 member 分別建立了三個字串, 值分別為 double 型別的 6 、 10 和 15 , 然後用跳躍表將這些指標有序地儲存起來, 形成這樣一個跳躍表:
![digraph zset { rankdir = LR; node [shape = record, style = filled]; edge [style = bold]; skiplist [label ="<head>zskipNode\n(head) |<3> |<2> |<1> |<score>score\n NULL |<robj>robj\n NULL", fillcolor = "#F2F2F2"]; six [label = "<head>zskipNode |<3> |<2> |<1> |<score>score\n 6 |<robj>robj\n x", fillcolor = "#95BBE3"]; ten [label = "<head>zskipNode | <1> |<score>score\n 10 |<robj>robj\n y", fillcolor = "#95BBE3"]; fiften [label = "<head>zskipNode |<3> |<2> |<1> |<score>score\n 15 |<robj>robj\n z", fillcolor = "#95BBE3"]; skiplist:3 -> six:3; skiplist:2 -> six:2; skiplist:1 -> six:1; six:1 -> ten:1; six:2 -> fiften:2; six:3 -> fiften:3; ten:1 -> fiften:1; null_1 [label = "NULL", shape=plaintext]; null_2 [label = "NULL", shape=plaintext]; null_3 [label = "NULL", shape=plaintext]; fiften:1 -> null_1; fiften:2 -> null_2; fiften:3 -> null_3; }](https://redisbook.readthedocs.io/en/latest/_images/graphviz-ba063df77d0d9a6581ef14368644db453ab8a7f7.svg)
為了方便展示, 在圖片中我們直接將 member 和 score 值包含在表節點中, 但是在實際的定義中, 因為跳躍表要和另一個實現有序集的結構(字典)分享 member 和 score 值, 所以跳躍表只儲存指向 member 和 score 的指標。 更詳細的資訊,請參考《有序集》章節。
小結
- 跳躍表是一種隨機化資料結構,查詢、新增、刪除操作都可以在對數期望時間下完成。
- 跳躍表目前在 Redis 的唯一作用,就是作為有序集型別的底層資料結構(之一,另一個構成有序集的結構是字典)。
- 為了滿足自身的需求,Redis 基於 William Pugh 論文中描述的跳躍表進行了修改,包括:
score值可重複。- 對比一個元素需要同時檢查它的
score和memeber。 - 每個節點帶有高度為 1 層的後退指標,用於從表尾方向向表頭方向迭代。