
常用影象庫整理
此篇博文裡的大部分內容來源於我在知乎上對做影象檢索,影象庫從哪兒能下載到?問題的回答。
這個問題對於每個剛做影象檢索的人都會碰到,我剛開始CBIR的時候也是谷歌影象庫漫天搜,後來隨著論文讀得多了,接觸到的影象庫也漸漸多了。回到正題,目前做CBIR用得比較多且流行的有下面幾個:
-
MNIST手寫數字影象庫, Yann LeCun, Corinna Cortes and Chris Burges,這個庫有共70,000張圖片,每張圖片的大小是28*28,共包含10類從數字0到9的手寫字元影象,在影象檢索裡一般是直接使用它的灰度畫素作為特徵,特徵維度為784維。
-
CIFAR-10 and CIFAR-100 datasets
,這個資料庫包含10類影象,每類6k,影象解析度是32*32。另外還有一個CIFAR-100。如果嫌CIFAR-100小,還有一個更大的Tiny Images Dataset,上面CIFAR-10和CIFAR-100都是從這個庫裡篩選出來的,這個庫有80M圖片。 -
Caltech101和Caltech256,從後面的資料可以看出它們分別有多少類了。雖然這兩個庫用於做影象分類用得很多,不過也非常適合做CBIR,前面給的兩個資料庫由於影象大小尺寸較小,在檢索視覺化的時候顯示的效果不是很好。所以我比較推薦用Caltech256和Caltech101,Caltech256有接近30k的圖片,用這個發發論文完全是沒什麼問題的。如果要做幾百萬的實際應用,那得另尋資料庫。
-
INRIA Holidays,也是一個在做CBIR時用的很多的資料庫,影象檢索的論文裡很多都會用這個資料庫。該資料集是Herve Jegou研究所經常度假時拍的圖片(風景為主),一共1491張圖,500張query(一張圖一個group)和對應著991張相關影象,已提取了128維的SIFT點4455091個,visual dictionaries來自Flickr60K,連結。

- Oxford Buildings Dataset,5k Dataset images,有5062張圖片,是牛津大學VGG小組公佈的,在基於詞彙樹做檢索的論文裡面,這個資料庫出現的頻率極高,下載連結。

- Oxford Paris,The Paris Dataset,oxford的VGG組從Flickr蒐集了6412張巴黎旅遊圖片,包括Eiffel Tower等。

- 201Books and CTurin180,The CTurin180 and 201Books Data Sets,2011.5,Telecom Italia提供於Compact Descriptors for Visual Search,該資料集包括:Nokia E7拍攝的201本書的封面圖片(多視角拍攝,各6張),共1.3GB; Turin市180個建築的視訊影象,拍攝的camera有Galaxy S、iPhone 3、Canon A410、Canon S5 IS,共2.7GB。

- Stanford Mobile Visual Search,Stanford Mobile Visual Search Dataset,2011.2,stanford提供,包括8種場景,如CD封面、油畫等,每組相關圖片都是採自不同相機(手機),所有場景共500張圖,連結;隨後又釋出了一個patch資料集,Compact Descriptors for Visual Search Patches Dataset,校對了相同patch。
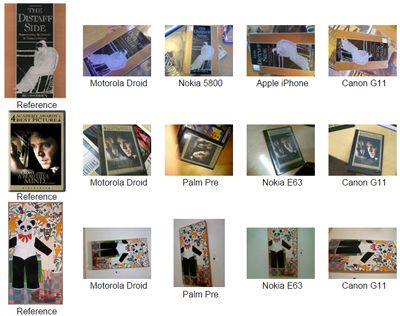
- UKBench,UKBench database,2006.7,Henrik Stewénius在他CVPR06文章中提供的資料集,影象都為640*480,每個group有4張圖,檔案接近2GB,提供visual words,連結。

- MIR-FLICKR,MIR-FLICKR-1M,2010,1M張Flickr上的圖片,也提供25K子集下載,連結。
此外,還有COREL,NUS-WIDE等。一般做影象檢索驗證演算法,前面給出的四個資料庫應該是足夠了的。
-
ImageCLEFmed醫學影象資料庫,見Online Multiple Kernel Similarity Learning for Visual Search。這個Project page裡,有5個影象庫,分別是Indoor、Caltech256、Corel (5000)、ImageCLEF (Med)、Oxford Buildings,在主頁上不僅可以下到影象庫,而且作者還提供了已經提取好的特徵。
-
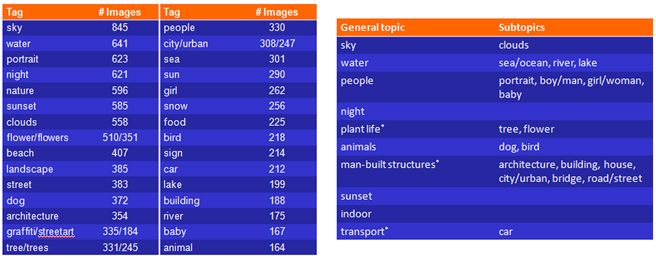
雜湊檢索常用資料庫,如下圖:
