
JDK8 新特性流式資料處理
在學習JDK8新特性Optional類的時候,提到對於Optional的兩個操作對映和過濾設計到JDK提供的流式出來。這篇文章便詳細的介紹流式處理:
一. 流式處理簡介
流式處理給開發者的第一感覺就是讓集合操作變得簡潔了許多,通常我們需要多行程式碼才能完成的操作,藉助於流式處理可以在一行中實現。比如我們希望對一個包含整數的集合中篩選出所有的偶數,並將其封裝成為一個新的List返回,那麼在java8之前,我們需要通過如下程式碼實現:
對於一個nums的集合:
List<Integer> evens = new ArrayList<>();
for (final 通過java8的流式處理,我們可以將程式碼簡化為:
List<Integer> evens = nums.stream().filter(num -> num % 2 == 0).collect(Collectors.toList());先簡單解釋一下上面這行語句的含義,stream()操作將集合轉換成一個流,filter()執行我們自定義的篩選處理,這裡是通過lambda表示式篩選出所有偶數,最後我們通過collect()對結果進行封裝處理,並通過Collectors.toList()指定其封裝成為一個List集合返回。
由上面的例子可以看出,java8的流式處理極大的簡化了對於集合的操作,實際上不光是集合,包括陣列、檔案等,只要是可以轉換成流,我們都可以藉助流式處理,類似於我們寫SQL語句一樣對其進行操作。java8通過內部迭代來實現對流的處理,一個流式處理可以分為三個部分:轉換成流、中間操作、終端操作。如下圖:
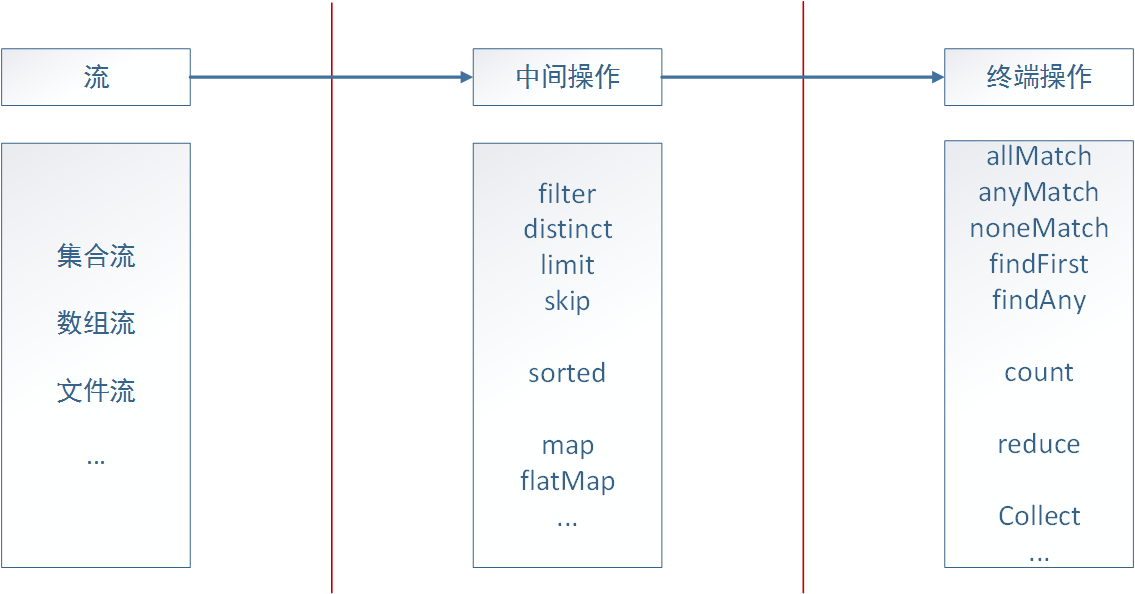
以集合為例,一個流式處理的操作我們首先需要呼叫stream()函式將其轉換成流,然後再呼叫相應的中間操作達到我們需要對集合進行的操作,比如篩選、轉換等,最後通過終端操作對前面的結果進行封裝,返回我們需要的形式。
二. 中間操作
我們定義一個簡單的學生實體類,用於後面的例子演示:
public 初始化:
// 初始化
List<Student> students = new ArrayList<Student>() {
{
add(new Student(20160001, "孔明", 20, 1, "土木工程", "武漢大學"));
add(new Student(20160002, "伯約", 21, 2, "資訊保安", "武漢大學"));
add(new Student(20160003, "玄德", 22, 3, "經濟管理", "武漢大學"));
add(new Student(20160004, "雲長", 21, 2, "資訊保安", "武漢大學"));
add(new Student(20161001, "翼德", 21, 2, "機械與自動化", "華中科技大學"));
add(new Student(20161002, "元直", 23, 4, "土木工程", "華中科技大學"));
add(new Student(20161003, "奉孝", 23, 4, "電腦科學", "華中科技大學"));
add(new Student(20162001, "仲謀", 22, 3, "土木工程", "浙江大學"));
add(new Student(20162002, "魯肅", 23, 4, "電腦科學", "浙江大學"));
add(new Student(20163001, "丁奉", 24, 5, "土木工程", "南京大學"));
}
};過濾:
過濾,顧名思義就是按照給定的要求對集合進行篩選滿足條件的元素,java8提供的篩選操作包括:filter、distinct、limit、skip。
filter
在前面的例子中我們已經演示瞭如何使用filter,其定義為:Stream<T> filter(Predicate<? super T> predicate),filter接受一個謂詞Predicate,我們可以通過這個謂詞定義篩選條件,在介紹lambda表示式時我們介紹過Predicate是一個函式式介面,其包含一個test(T t)方法,該方法返回boolean。現在我們希望從集合students中篩選出所有武漢大學的學生,那麼我們可以通過filter來實現,並將篩選操作作為引數傳遞給filter:
List<Student> whuStudents = students.stream()
.filter(student -> "武漢大學".equals(student.getSchool()))
.collect(Collectors.toList());distinct
distinct操作類似於我們在寫SQL語句時,新增的DISTINCT關鍵字,用於去重處理,distinct基於Object.equals(Object)實現,回到最開始的例子,假設我們希望篩選出所有不重複的偶數,那麼可以新增distinct操作:
List<Integer> evens = nums.stream()
.filter(num -> num % 2 == 0).distinct()
.collect(Collectors.toList());limit
limit操作也類似於SQL語句中的LIMIT關鍵字,不過相對功能較弱,limit返回包含前n個元素的流,當集合大小小於n時,則返回實際長度,比如下面的例子返回前兩個專業為土木工程專業的學生:
List<Student> civilStudents = students.stream()
.filter(student -> "土木工程".equals(student.getMajor())).limit(2)
.collect(Collectors.toList());說到limit,不得不提及一下另外一個流操作:sorted。該操作用於對流中元素進行排序,sorted要求待比較的元素必須實現Comparable介面,如果沒有實現也不要緊,我們可以將比較器作為引數傳遞給sorted(Comparator
List<Student> sortedCivilStudents = students.stream()
.filter(student -> "土木工程".equals(student.getMajor())).sorted((s1, s2) -> s1.getAge() - s2.getAge())
.limit(2)
.collect(Collectors.toList());
skip
skip操作與limit操作相反,如同其字面意思一樣,是跳過前n個元素,比如我們希望找出排序在2之後的土木工程專業的學生,那麼可以實現為:
List<Student> civilStudents = students.stream()
.filter(student -> "土木工程".equals(student.getMajor()))
.skip(2)
.collect(Collectors.toList());
通過skip,就會跳過前面兩個元素,返回由後面所有元素構造的流,如果n大於滿足條件的集合的長度,則會返回一個空的集合。
對映處理:
在SQL中,藉助SELECT關鍵字後面新增需要的欄位名稱,可以僅輸出我們需要的欄位資料,而流式處理的對映操作也是實現這一目的,在java8的流式處理中,主要包含兩類對映操作:map和flatMap。
map
舉例說明,假設我們希望篩選出所有專業為電腦科學的學生姓名,那麼我們可以在filter篩選的基礎之上,通過map將學生實體對映成為學生姓名字串,具體實現如下:
List<String> names = students.stream()
.filter(student -> "電腦科學".equals(student.getMajor()))
.map(Student::getName).collect(Collectors.toList());熟悉Optional的話可以看出,這與Optional的處理方法一樣。
除了上面這類基礎的map,java8還提供了mapToDouble(ToDoubleFunction<? super T> mapper),mapToInt(ToIntFunction<? super T> mapper),mapToLong(ToLongFunction<? super T> mapper),這些對映分別返回對應型別的流,java8為這些流設定了一些特殊的操作,比如我們希望計算所有專業為電腦科學學生的年齡之和,那麼我們可以實現如下:
int totalAge = students.stream()
.filter(student -> "電腦科學".equals(student.getMajor()))
.mapToInt(Student::getAge).sum();通過將Student按照年齡直接對映為IntStream,我們可以直接呼叫提供的sum()方法來達到目的,此外使用這些數值流的好處還在於可以避免jvm裝箱操作所帶來的效能消耗。
flatMap
flatMap與map的區別在於* flatMap是將一個流中的每個值都轉成一個個流,然後再將這些流扁平化成為一個流 。*舉例說明,假設我們有一個字串陣列String[] strs = {“java8”, “is”, “easy”, “to”, “use”};,我們希望輸出構成這一陣列的所有非重複字元,那麼我們可能首先會想到如下實現:
List<String[]> distinctStrs = Arrays.stream(strs)
.map(str -> str.split("")) // 對映成為Stream<String[]>
.distinct()
.collect(Collectors.toList());在執行map操作以後,我們得到是一個包含多個字串(構成一個字串的字元陣列)的流,此時執行distinct操作是基於在這些字串陣列之間的對比,所以達不到我們希望的目的,此時的輸出為:
[j, a, v, a, 8]
[i, s]
[e, a, s, y]
[t, o]
[u, s, e]distinct只有對於一個包含多個字元的流進行操作才能達到我們的目的,即對Stream<String>進行操作。此時flatMap就可以達到我們的目的:
List<String> distinctStrs = Arrays.stream(strs)
.map(str -> str.split("")) // 對映成為Stream<String[]>
.flatMap(Arrays::stream) // 扁平化為Stream<String>
.distinct()
.collect(Collectors.toList());flatMap將由map對映得到的Stream<String[]>,轉換成由各個字串陣列對映成的流Stream<String>,再將這些小的流扁平化成為一個由所有字串構成的大流Steam<String>,從而能夠達到我們的目的。
與map類似,flatMap也提供了針對特定型別的對映操作:flatMapToDouble(Function<? super T,? extends DoubleStream> mapper),flatMapToInt(Function<? super T,? extends IntStream> mapper),flatMapToLong(Function<? super T,? extends LongStream> mapper)
三. 終端操作
終端操作是流式處理的最後一步,我們可以在終端操作中實現對流查詢、歸約等操作。
3.1 查詢
allMatch
allMatch用於檢測是否全部都滿足指定的引數行為,如果全部滿足則返回true,例如我們希望檢測是否所有的學生都已滿18週歲,那麼可以實現為:
boolean isAdult = students.stream().allMatch(student -> student.getAge() >= 18);anyMatch
anyMatch則是檢測是否存在一個或多個滿足指定的引數行為,如果滿足則返回true,例如我們希望檢測是否有來自武漢大學的學生,那麼可以實現為:
boolean hasWhu = students.stream().anyMatch(student -> "武漢大學".equals(student.getSchool()));noneMathch
noneMatch用於檢測是否不存在滿足指定行為的元素,如果不存在則返回true,例如我們希望檢測是否不存在專業為電腦科學的學生,可以實現如下:
boolean noneCs = students.stream().noneMatch(student -> "電腦科學".equals(student.getMajor()));findFirst
findFirst用於返回滿足條件的第一個元素,比如我們希望選出專業為土木工程的排在第一個學生,那麼可以實現如下:
Optional<Student> optStu = students.stream().filter(student -> "土木工程".equals(student.getMajor())).findFirst();findFirst不攜帶引數,具體的查詢條件可以通過filter設定,此外我們可以發現findFirst返回的是一個Optional型別.
findAny
findAny相對於findFirst的區別在於,findAny不一定返回第一個,而是返回任意一個,比如我們希望返回任意一個專業為土木工程的學生,可以實現如下:
Optional<Student> optStu = students.stream().filter(student -> "土木工`程".equals(student.getMajor())).findAny();實際上對於順序流式處理而言,findFirst和findAny返回的結果是一樣的,至於為什麼會這樣設計,接下來我們介紹的並行流式處理,當我們啟用並行流式處理的時候,查詢第一個元素往往會有很多限制,如果不是特別需求,在並行流式處理中使用findAny的效能要比findFirst好。
歸約
前面的例子中我們大部分都是通過collect(Collectors.toList())對資料封裝返回,如我的目標不是返回一個新的集合,而是希望對經過引數化操作後的集合進行進一步的運算,那麼我們可用對集合實施歸約操作。java8的流式處理提供了reduce方法來達到這一目的。
前面我們通過mapToInt將Stream<Student>對映成為IntStream,並通過IntStream的sum方法求得所有學生的年齡之和,實際上我們通過歸約操作,也可以達到這一目的,實現如下:
// 前面例子中的方法
int totalAge = students.stream()
.filter(student -> "電腦科學".equals(student.getMajor()))
.mapToInt(Student::getAge).sum();
// 歸約操作
int totalAge = students.stream()
.filter(student -> "電腦科學".equals(student.getMajor()))
.map(Student::getAge)
.reduce(0, (a, b) -> a + b);
// 進一步簡化
int totalAge2 = students.stream()
.filter(student -> "電腦科學".equals(student.getMajor()))
.map(Student::getAge)
.reduce(0, Integer::sum);
// 採用無初始值的過載版本,需要注意返回Optional
Optional<Integer> totalAge = students.stream()
.filter(student -> "電腦科學".equals(student.getMajor()))
.map(Student::getAge)
.reduce(Integer::sum); // 去掉初始值
收集
前面利用collect(Collectors.toList())是一個簡單的收集操作,是對處理結果的封裝,對應的還有toSet、toMap,以滿足我們對於結果組織的需求。這些方法均來自於java.util.stream.Collectors,我們可以稱之為收集器。
收集器也提供了相應的歸約操作,但是與reduce在內部實現上是有區別的,收集器更加適用於可變容器上的歸約操作,這些收集器廣義上均基於Collectors.reducing()實現。
求學生的總人數
long count = students.stream().collect(Collectors.counting());
// 進一步簡化
long count = students.stream().count();求年齡的最大值和最小值
// 求最大年齡
Optional<Student> olderStudent = students.stream().collect(Collectors.maxBy((s1, s2) -> s1.getAge() - s2.getAge()));
// 進一步簡化
Optional<Student> olderStudent2 = students.stream().collect(Collectors.maxBy(Comparator.comparing(Student::getAge)));
// 求最小年齡
Optional<Student> olderStudent3 = students.stream().collect(Collectors.minBy(Comparator.comparing(Student::getAge)));求年齡總和
int totalAge4 = students.stream().collect(Collectors.summingInt(Student::getAge));字串拼接
String names = students.stream().map(Student::getName).collect(Collectors.joining());
// 輸出:孔明伯約玄德雲長翼德元直奉孝仲謀魯肅丁奉
String names = students.stream().map(Student::getName).collect(Collectors.joining(", "));
// 輸出:孔明, 伯約, 玄德, 雲長, 翼德, 元直, 奉孝, 仲謀, 魯肅, 丁奉四. 並行流式資料處理
流式處理中的很多都適合採用 分而治之 的思想,從而在處理集合較大時,極大的提高程式碼的效能,java8的設計者也看到了這一點,所以提供了 並行流式處理。上面的例子中我們都是呼叫stream()方法來啟動流式處理,java8還提供了parallelStream()來啟動並行流式處理,parallelStream()本質上基於java7的Fork-Join框架實現,其預設的執行緒數為宿主機的核心數。
啟動並行流式處理雖然簡單,只需要將stream()替換成parallelStream()即可,但既然是並行,就會涉及到多執行緒安全問題,所以在啟用之前要先確認並行是否值得(並行的效率不一定高於順序執行),另外就是要保證執行緒安全。此兩項無法保證,那麼並行毫無意義,畢竟結果比速度更加重要。