
吳恩達Deeplearning.ai 第五課 Sequence Model 第一週------Long Short Term Memory(LSTM)
阿新 • • 發佈:2019-01-07
這一節主要講解了LSTM單元

LSTM和GRU略有區別,可以說是一種更加通用的GRU模型
在LSTM中,c<t>不再等於a<t>,因此原來公式中的c<t-1>要改成a<t-1>,同時在LSTM中,也沒有了Γr這個門
但不同是,除了同樣保持了Γu這個門之外,還增加了Γf(forget gate)和Γo(output gate)兩個門。在原來c<t>的更新公式中,將(1-Γu)替換為Γf,並且在利用Γo來得到a<t>
LSTM的公式和單元結構:
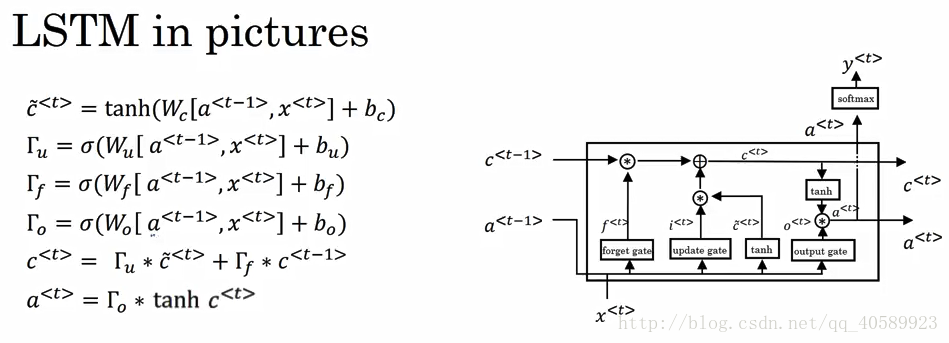
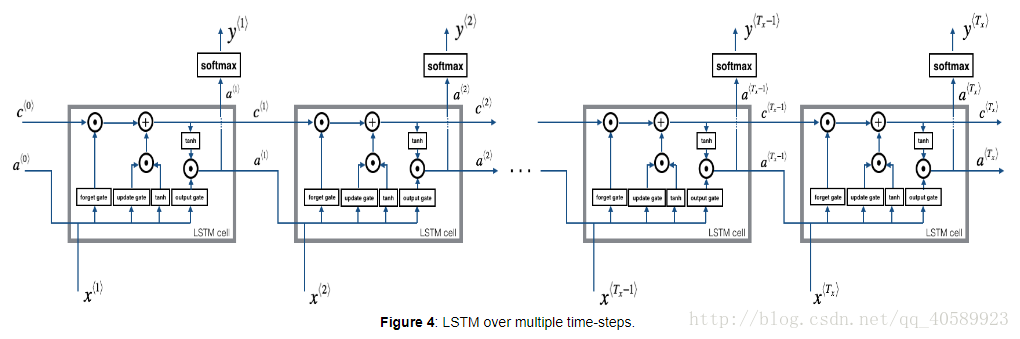
很多個這樣的單元組合起來就成了LSTM network:
一些不同的版本:
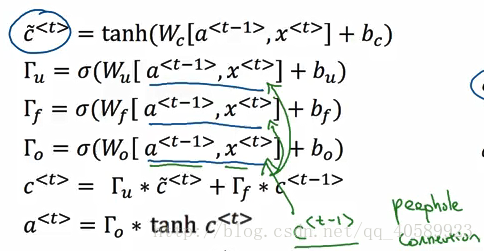
同樣,在這裡面,有時候也會在gate的計算中加入c<t-1>項,即變成Wu[a<t-1>, x<t>, c<t-1>]等,這被稱為peephole connection
但在這裡面c<t-1>的每個元素隻影響gate中對應的某個元素,而不會影響gate中其他位置的元素
LSTM和GRU的選擇:
1.關於二者孰優孰劣並沒有明確的論斷,在實際專案中可以進行嘗試。
2.GRU的優點是隻需要兩個門,計算量更小,當要搭建大型神經網路時可以更好得scaling(感覺這個詞只可意會不可翻譯)
3.LSTM的優點是有三個門,因此效率更高,但是計算量更大。
在現在的一些研究中,使用LSTM的會更多一些