
CTC學習筆記(一) 簡介
阿新 • • 發佈:2019-01-07
背景
Connectionist temporal classification簡稱CTC,翻譯不太清楚,可以理解為基於神經網路的時序類分類。其中classification比較好理解,表示分類問題;temporal可以理解為時序類問題,比如語音識別的一幀資料,很難給出一個label,但是幾十幀資料就容易判斷出對應的發音label,這個詞也給出CTC最核心的意義;connectionist可以理解為神經網路中的連線。
語音識別聲學模型的訓練屬於監督學習,需要知道每一幀對應的label才能進行有效的訓練,在訓練的資料準備階段必須要對語音進行強制對齊。
CTC的引入可以放寬了這種一一對應的限制要求,只需要一個輸入序列和一個輸出序列即可以訓練。有兩點好處:不需要對資料對齊和一一標註;CTC直接輸出序列預測的概率,不需要外部的後處理。
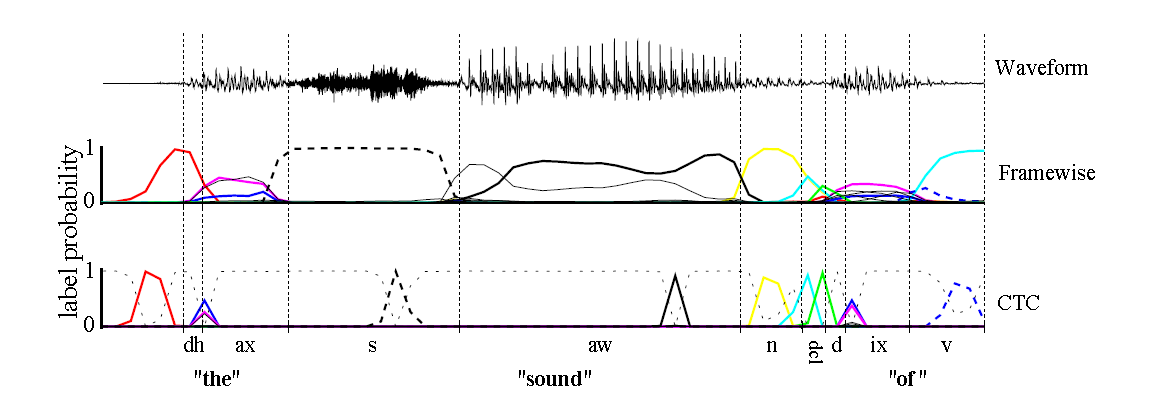
如上圖,傳統的Framewise訓練需要進行語音和音素髮音的對齊,比如“s”對應的一整段語音的標註都是s;而CTC引入了blank(該幀沒有預測值),“s”對應的一整段語音中只有一個spike(尖峰)被認為是s,其他的認為是blank。對於一段語音,CTC最後的輸出是spike的序列,不關心每一個音素對應的時間長度。
輸出
語音識別中的DNN訓練,每一幀都有相應的狀態標記,比如有5幀輸入x1,x2,x3,x4,x5,對應的標註分別是狀態a1,a1,a1,a2,a2。
CTC的不同之處在於輸出狀態引入了一個blank,輸出和label滿足如下的等價關係:
多個輸出序列可以對映到一個輸出。