
Python 使用Charles爬取APP資訊以及公眾號資訊
這個就不介紹了,自行網上查閱,官網下載然後破解一下,開啟手機操作一波,都挺簡單的。
注意事項:都需要安裝證書,手機和電腦都需要安裝證書,443埠指的是https服務。
二、APP資訊抓取
分析
前期準備,需要知道url,cookies,response返回的資料,請求的方式
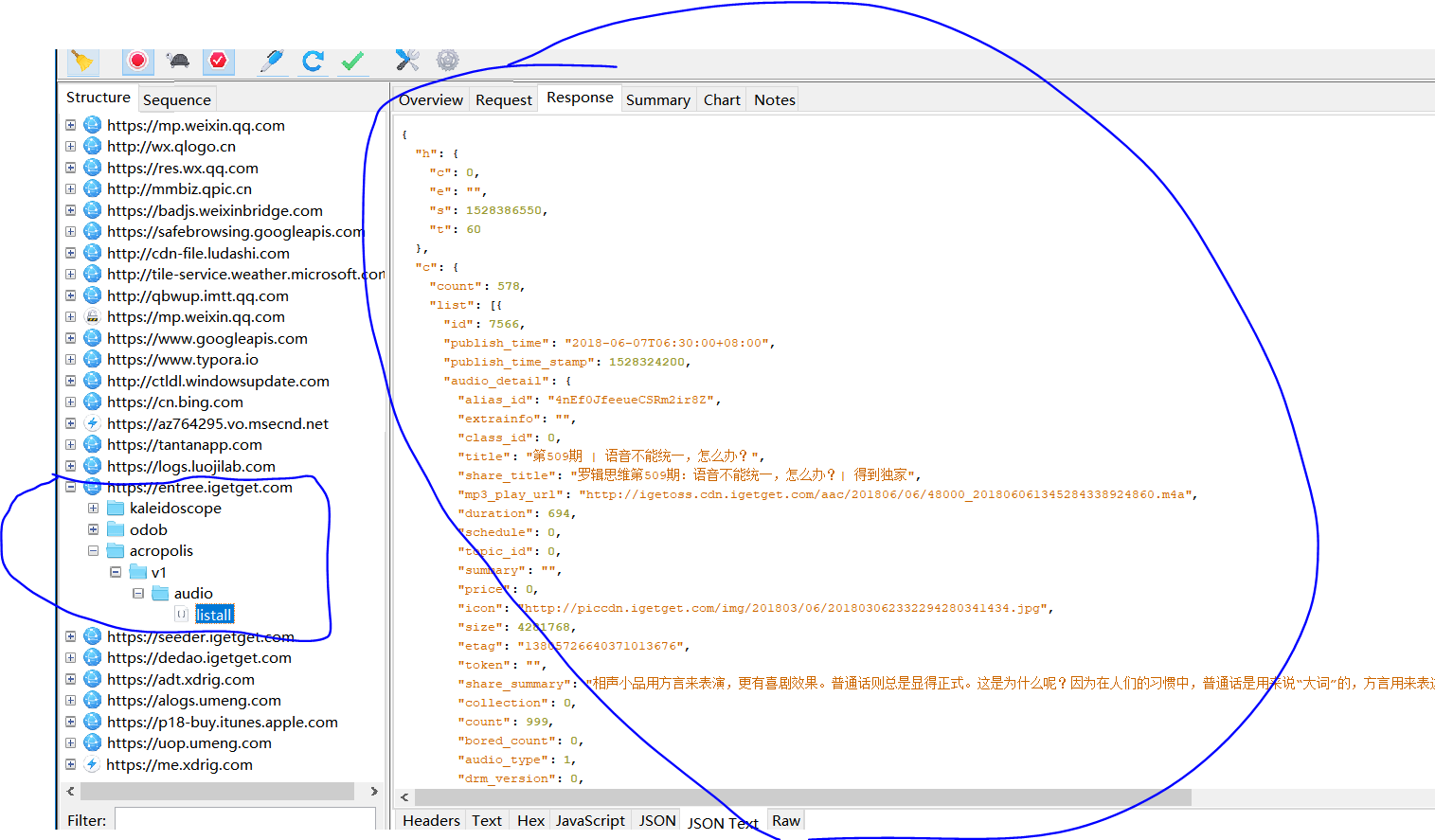
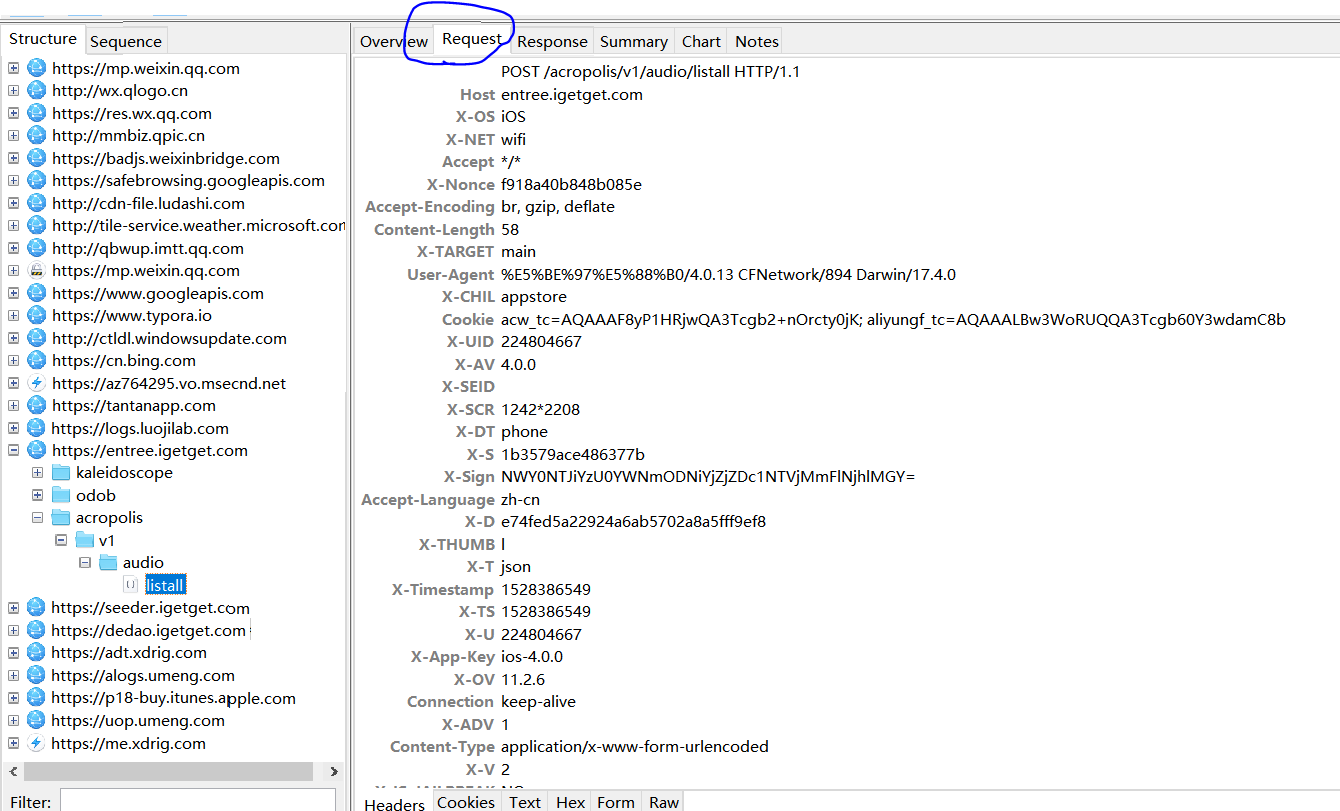
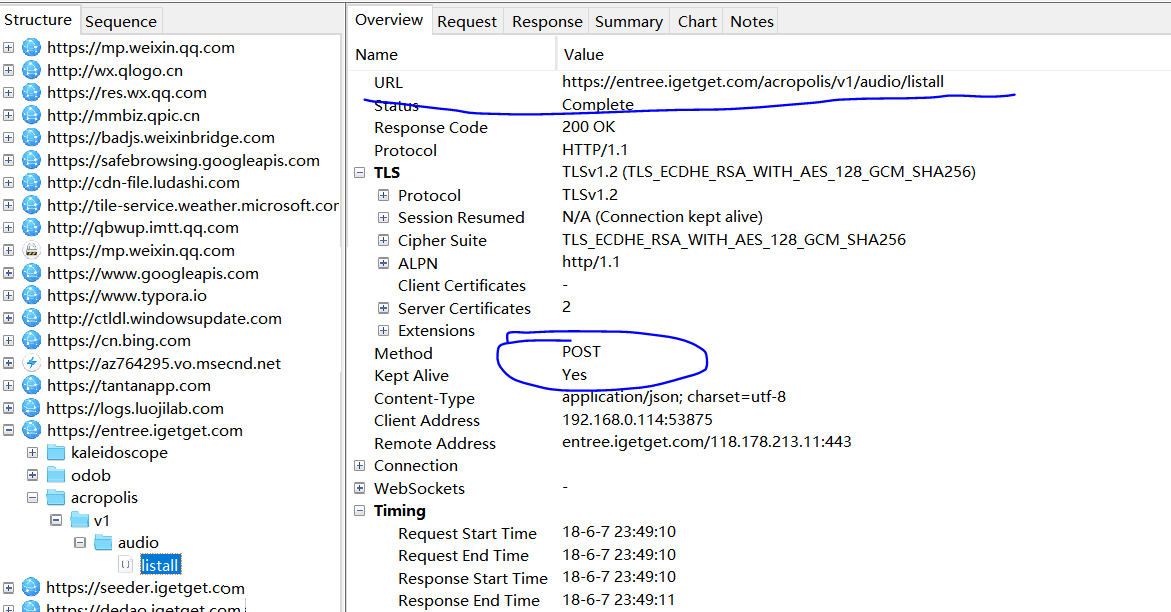
開啟想要抓取的APP,這裡是得到頁面邏輯思維欄目,在手機上不斷重新整理,能在Charles的Structure中看到有黃色變化,點選去。如下圖一。然後開始分析這個請求,得到自己想要的資料。首先在Overview選項卡中可以得到我們需要請求的url地址,發現其請求方式是POST。在Request選項卡中,在底部點選切換,我們需要headers資料,不設定的話就需要登入,這裡要注意拷貝過來的headers,放入程式碼中僅僅是加個引號,逗號,內容中間不要有空格。在Response中,能發現這就是我們需要的資料,而且還是json格式的資料。然後接下來就是編寫程式碼了
程式碼
# coding=utf-8 import requests import json from Utils import Utils import os import time class DeDao(object): def __init__(self): self.row_title = ['來源目錄', '標題', '圖片', '分享標題', 'mp3地址', '音訊時長', '檔案大小'] sheet_name = '邏輯思維音訊' return_execl = Utils.create_execl(sheet_name, self.row_title) self.execl_f = return_execl[0] self.sheet_table = return_execl[1] self.audio_info = [] # 存放每一條資料中的各元素 self.count = 0 self.base_url = 'https://entree.igetget.com/acropolis/v1/audio/listall' self.max_id = 0 self.headers = { 'Host': 'entree.igetget.com', 'X-OS': 'iOS', 'X-NET': 'wifi', 'Accept': '*/*', 'X-Nonce': '70291808a4530748', 'Accept-Encoding': 'br, gzip, deflate', 'X-TARGET': 'main', 'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/894 Darwin/17.4.0', 'X-CHIL': 'appstore', 'Cookie': 'acw_tc=AQAAAPt0EXBorQgA3Tcgb+9WeJpgznSn; aliyungf_tc=AQAAADwDyS2DbAgA3TcgbxkoU3Bb9E7e', 'X-UID': '224804667', 'X-AV': '4.0.0', 'X-SEID': '', 'X-SCR': '1242*2208', 'X-DT': 'phone', 'X-S': '1b3579ace486377b', 'X-Sign': 'ZjQzMzZkNWI2YmJmOTMzNmUyOWJlNGY5NWRhZDYzNzY=', 'Accept-Language': 'zh-cn', 'X-D': 'e74fed5a22924a6ab5702a8a5fff9ef8', 'X-THUMB': 'l', 'X-T': 'json', 'X-Timestamp': '1528304815', 'X-TS': '1528304815', 'X-U': '224804667', 'X-App-Key': 'ios-4.0.0', 'X-OV': '11.2.6', 'Connection': 'keep-alive', 'X-ADV': '1', 'Content-Type': 'application/x-www-form-urlencoded', 'X-V': '2', 'X-IS_JAILBREAK': 'NO', 'X-DV': 'iPhone9,2', } def request_data(self): try: data = { 'max_id': self.max_id, 'since_id': 0, 'column_id': 2, 'count': 20, 'order': 1, 'section': 0 } response = requests.post( self.base_url, headers=self.headers, data=data) print(response.status_code) if 200 == response.status_code: self.parse_data(response) except Exception as e: print(e) def parse_data(self, response): dict_json = json.loads(response.text) datas = dict_json['c']['list'] for data in datas: source_name = data['audio_detail']['source_name'] title = data['audio_detail']['title'] icon = data['audio_detail']['icon'] share_title = data['audio_detail']['share_title'] mp3_url = data['audio_detail']['mp3_play_url'] duction = str(data['audio_detail']['duration'])+'秒' size = data['audio_detail']['size'] / (1000 * 1000) size = '%.2fM' % size self.download_mp3(mp3_url) self.audio_info.append(source_name) self.audio_info.append(title) self.audio_info.append(icon) self.audio_info.append(share_title) self.audio_info.append(mp3_url) self.audio_info.append(duction) self.audio_info.append(size) self.count += 1 Utils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, '邏輯思維.xlsx') self.audio_info = [] print('採集了{}條資料'.format(self.count)) time.sleep(3) max_id = datas[-1]['publish_time_stamp'] if self.max_id != max_id: self.max_id = max_id self.request_data() else: print("資料抓取完畢") def download_mp3(self, mp3_url): mp3_path = "D:/Photo/mp3/" if not os.path.exists(mp3_path): os.makedirs(mp3_path) with open(mp3_path+mp3_url.split('/')[-1], 'wb') as f: f.write(requests.get(mp3_url).content) if __name__ == '__main__': d = DeDao() d.request_data()
三、獲取公眾號資訊,文章
1. 分析
和抓取APP資訊一樣,只不過這裡不怎麼好弄,最終結果是點選公眾號右上角聯絡人按鈕,進入歷史訊息爬取的,其它方式,例如精選文章什麼的,請求傳入的資料不固定,這種方式的好處是隻需要設定offset,偏移量即可,並且在每次請求後可以得到下一個請求的偏移量。
由於公眾號爬取涉及號主的隱私,這不大好,並且經常爬取容易被封號,這裡就不截執行效果圖了,自己執行一下就看出來了,注意第一個請求它的response不是json,可以從第二條開始分析,資料都會爬取到的。
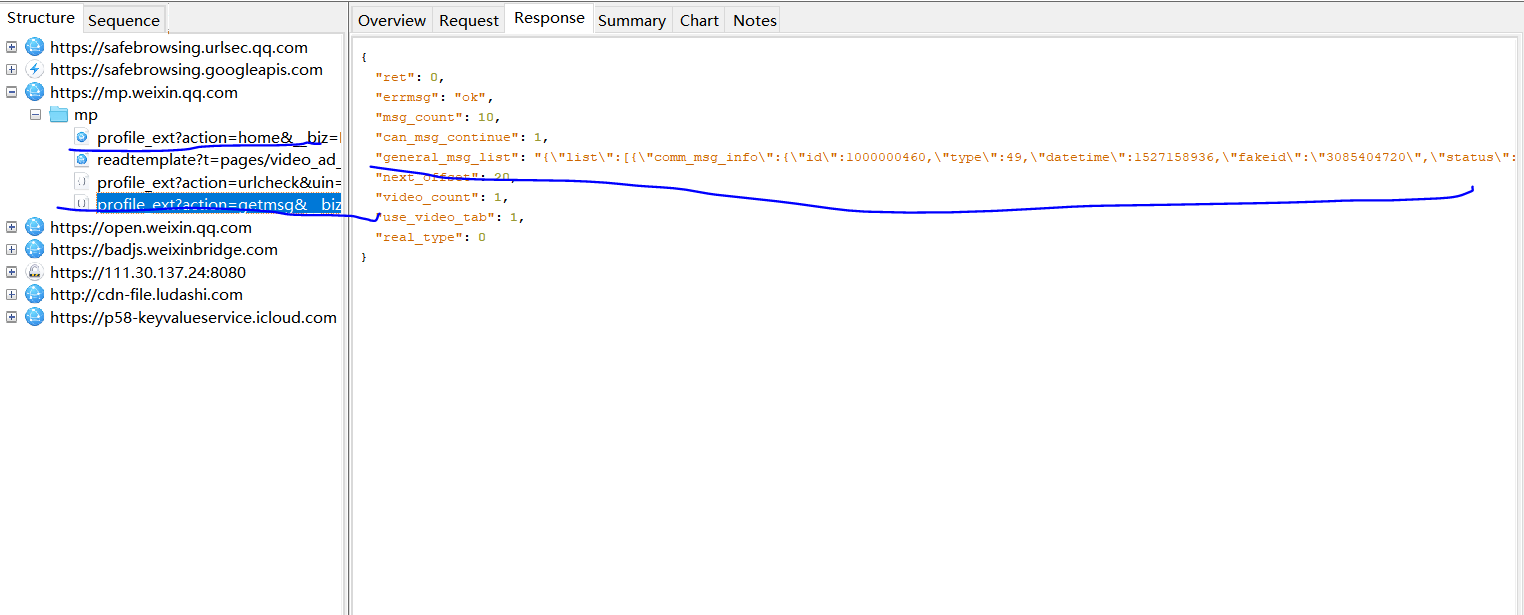
這裡請求頭和資料解析和爬取APP資訊類似,不同的地方是,baseUrl中的引數的資訊是有時間限制的,一般半個小時會更新一次。爬取APP資訊中將資訊存入了Excel檔案中,這裡就不做演示了,做法類似。
# coding:utf-8 import requests import json import time class GZH(): def __init__(self): self.base_url = "https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MzA4NTQwNDcyMA==&f=json&offset={}&count=10&is_ok=1&scene=124&uin=MjI3NjA3NTMyNA%3D%3D&key=c98d6c02144b06270885a670c2a286663f9642c3ff72f373a00f06810301c8c7a7f3cc6229ddc696d9bccda804f946faf49bdb9c864015d943c50daa854219b3590115d9427bc059598cedb40e9d4613&pass_ticket=lYcbXQqfbHyz0ho29nS7V4jaOV82KM5wZk3wD53mBIPfs5kdYJSOVhwkuIWc18P9&wxtoken=&appmsg_token=960_DqPqoyT1gBzGPQoYtXXQ7vvGbGfE1hZOfXdaDw~~&x5=0&f=json" self.headers = { 'Host': 'mp.weixin.qq.com', 'Connection': 'keep-alive', 'Accept': '*/*', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.691.400 QQBrowser/9.0.2524.400', 'X-Requested-With': 'XMLHttpRequest', 'Referer': 'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzA4NTQwNDcyMA==&scene=124&uin=MjI3NjA3NTMyNA%3D%3D&key=80b590d5e3a259312a4b1997f955cf49f1face919a96bf8f306fd5f9319a4cfe97dcce3de77d021ef4c31c24bb796ab3bdca5915daa97fd8450d32a29b328129fc54f66dfa544ea2e003f294d4fb0b32&devicetype=Windows+10&version=6206021b&lang=zh_CN&a8scene=7&pass_ticket=lYcbXQqfbHyz0ho29nS7V4jaOV82KM5wZk3wD53mBIPfs5kdYJSOVhwkuIWc18P9&winzoom=1', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.8,en-us;q=0.6,en;q=0.5;q=0.4', 'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=2276075324; devicetype=Windows10; version=6206021b; lang=zh_CN; pass_ticket=lYcbXQqfbHyz0ho29nS7V4jaOV82KM5wZk3wD53mBIPfs5kdYJSOVhwkuIWc18P9; wap_sid2=CLzOqL0IElxLNWE4dV9EQURLc3JOdU9WLTBlR2Vaa0lHQ1phc1p5ekNfWlZwVmVkeVdpcFJrZkZjU2hNX3RPd3dDeDg4S2Joa3JTblFVWkZaYW9FX3RQRTZGN1Q0c0FEQUFBfjDrj+XYBTgNQJVO' } self.offset = 10 def request_data(self): try: response = requests.get(self.base_url.format( self.offset), headers=self.headers) if response.status_code == 200: self.parse_data(response.text) except Exception as e: print(e) def parse_data(self, jsonText): datas = json.loads(jsonText) print(datas['ret']) if datas['ret'] == 0: self.offset = datas['next_offset'] msg_list = datas['general_msg_list'] result = json.loads(msg_list)['list'] for data in result: try: title = data['app_msg_ext_info']['title'] digest = data['app_msg_ext_info']['digest'] content_url = data['app_msg_ext_info']['digest'] cover = data['app_msg_ext_info']['cover'] print('title:{} digest:{} content_url:{} cover:{}'.format( title, digest, content_url, cover)) except Exception as e: print(e) continue print('***************************************************') time.sleep(2) self.request_data() else: print("資料抓取錯誤") if __name__ == '__main__': g = GZH() g.request_data()
四、只要Python基礎紮實,有思路,就能做到。