
一文讀懂Faster RCNN
1 前言
經過R-CNN和Fast RCNN的積澱,Ross B. Girshick在2016年提出了新的Faster RCNN,在結構上,Faster RCNN已經將特徵抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一個網路中,使得綜合性能有較大提高,在檢測速度方面尤為明顯。

2 總覽
依作者看來,如圖1,Faster RCNN其實可以分為4個主要內容:
- Conv layers。作為一種CNN網路目標檢測方法,Faster RCNN首先使用一組基礎的conv+relu+pooling層提取image的feature maps。該feature maps被共享用於後續RPN層和全連線層。
- Region Proposal Networks。RPN網路用於生成region proposals。該層通過softmax判斷anchors屬於foreground或者background,再利用bounding box regression修正anchors獲得精確的proposals。
- Roi Pooling。該層收集輸入的feature maps和proposals,綜合這些資訊後提取proposal feature maps,送入後續全連線層判定目標類別。Classification。利用proposal feature maps計算proposal的類別,同時再次bounding box regression獲得檢測框最終的精確位置。
- Classification。利用proposal feature maps計算proposal的類別,同時再次bounding box regression獲得檢測框最終的精確位置。
所以本文以上述4個內容作為切入點介紹Faster R-CNN網路。
圖2展示了python版本中的VGG16模型中的faster_rcnn_test.pt的網路結構,可以清晰的看到該網路對於一副任意大小PxQ的影象,首先縮放至固定大小MxN,然後將MxN影象送入網路;而Conv layers中包含了13個conv層+13個relu層+4個pooling層;RPN網路首先經過3x3卷積,再分別生成foreground anchors與bounding box regression偏移量,然後計算出proposals;而Roi Pooling層則利用proposals從feature maps中提取proposal feature送入後續全連線和softmax網路作classification(即分類proposal到底是什麼object)。

3 Conv layers
Conv layers包含了conv,pooling,relu三種層。以python版本中的VGG16模型中的faster_rcnn_test.pt的網路結構為例,如圖2,Conv layers部分共有13個conv層,13個relu層,4個pooling層。這裡有一個非常容易被忽略但是又無比重要的資訊,在Conv layers中:
- 所有的conv層都是: kernel_size=3 ,pad=1 , stride=1
- 所有的pooling層都是: kernel_size=2 , pad=0 , stride=2 所有的pooling層都是: kernel_size=2 , pad=0, stride=2
為何重要?在Faster RCNN Conv layers中對所有的卷積都做了擴邊處理( pad=1,即填充一圈0),導致原圖變為 (M+2)x(N+2)大小,再做3x3卷積後輸出MxN 。正是這種設定,導致Conv layers中的conv層不改變輸入和輸出矩陣大小。如圖3:
 類似的是,Conv layers中的pooling層kernel_size=2,stride=2。這樣每個經過pooling層的MxN矩陣,都會變為(M/2)x(N/2)大小。綜上所述,在整個Conv layers中,conv和relu層不改變輸入輸出大小,只有pooling層使輸出長寬都變為輸入的1/2。
類似的是,Conv layers中的pooling層kernel_size=2,stride=2。這樣每個經過pooling層的MxN矩陣,都會變為(M/2)x(N/2)大小。綜上所述,在整個Conv layers中,conv和relu層不改變輸入輸出大小,只有pooling層使輸出長寬都變為輸入的1/2。
那麼,一個MxN大小的矩陣經過Conv layers固定變為(M/16)x(N/16)!這樣Conv layers生成的featuure map中都可以和原圖對應起來。
4 Region Proposal Networks(RPN)
經典的檢測方法生成檢測框都非常耗時,如OpenCV adaboost使用滑動視窗+影象金字塔生成檢測框;或如R-CNN使用SS(Selective Search)方法生成檢測框。而Faster RCNN則拋棄了傳統的滑動視窗和SS方法,直接使用RPN生成檢測框,這也是Faster R-CNN的巨大優勢,能極大提升檢測框的生成速度。
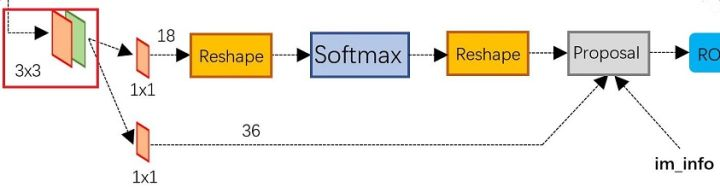
上圖4展示了RPN網路的具體結構。可以看到RPN網路實際分為2條線,上面一條通過softmax分類anchors獲得foreground和background(檢測目標是foreground),下面一條用於計算對於anchors的bounding box regression偏移量,以獲得精確的proposal。而最後的Proposal層則負責綜合foreground anchors和bounding box regression偏移量獲取proposals,同時剔除太小和超出邊界的proposals。其實整個網路到了Proposal Layer這裡,就完成了相當於目標定位的功能。
4.1 多通道影象卷積基礎知識介紹
在介紹RPN前,還要多解釋幾句基礎知識,已經懂的看官老爺跳過就好。
- 對於單通道影象+單卷積核做卷積,第一章中的圖3已經展示了;
- 對於多通道影象+多卷積核做卷積,計算方式如下:
 如圖5,輸入有3個通道,同時有2個卷積核。對於每個卷積核,先在輸入3個通道分別作卷積,再將3個通道結果加起來得到卷積輸出。所以對於某個卷積層,無論輸入影象有多少個通道,輸出影象通道數總是等於卷積核數量!
如圖5,輸入有3個通道,同時有2個卷積核。對於每個卷積核,先在輸入3個通道分別作卷積,再將3個通道結果加起來得到卷積輸出。所以對於某個卷積層,無論輸入影象有多少個通道,輸出影象通道數總是等於卷積核數量!
對多通道影象做1x1卷積,其實就是將輸入影象於每個通道乘以卷積係數後加在一起,即相當於把原影象中本來各個獨立的通道“聯通”在了一起。
4.2 anchors
提到RPN網路,就不能不說anchors。所謂anchors,實際上就是一組由rpn/generate_anchors.py生成的矩形。直接執行作者demo中的generate_anchors.py可以得到以下輸出:
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
其中每行的4個值
表矩形左上和右下角點座標。9個矩形共有3種形狀,長寬比為大約為 width:height ∈ {1:1, 1:2, 2:1} 三種,如圖6。實際上通過anchors就引入了檢測中常用到的多尺度方法。
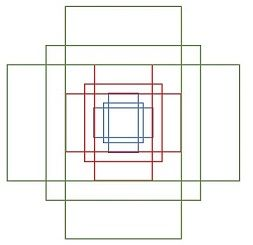
注:關於上面的anchors size,其實是根據檢測影象設定的。在python demo中,會把任意大小的輸入影象reshape成800x600(即圖2中的M=800,N=600)。再回頭來看anchors的大小,anchors中長寬1:2中最大為352x704,長寬2:1中最大736x384,基本是cover了800x600的各個尺度和形狀。
那麼這9個anchors是做什麼的呢?借用Faster RCNN論文中的原圖,如圖7,遍歷Conv layers計算獲得的feature maps,為每一個點都配備這9種anchors作為初始的檢測框。這樣做獲得檢測框很不準確,不用擔心,後面還有2次bounding box regression可以修正檢測框位置。
 解釋一下上面這張圖的數字。
解釋一下上面這張圖的數字。
- 在原文中使用的是ZF model中,其Conv Layers中最後的conv5層num_output=256,對應生成256張特徵圖,所以相當於feature map每個點都是256-dimensions
- 在conv5之後,做了rpn_conv/3x3卷積且num_output=256,相當於每個點又融合了周圍3x3的空間資訊(猜測這樣做也許更魯棒?反正我沒測試),同時256-d不變(如圖4和圖7中的紅框)
- 假設在conv5 feature map中每個點上有k個anchor(預設k=9),而每個anhcor要分foreground和background,所以每個點由256d feature轉化為cls=2k scores;而每個anchor都有(x, y, w, h)對應4個偏移量,所以reg=4k coordinates
- 補充一點,全部anchors拿去訓練太多了,訓練程式會在合適的anchors中隨機選取128個postive anchors+128個negative anchors進行訓練(什麼是合適的anchors下文5.1有解釋)
注意,在本文講解中使用的VGG conv5 num_output=512,所以是512d,其他類似。
其實RPN最終就是在原圖尺度上,設定了密密麻麻的候選Anchor。然後用cnn去判斷哪些Anchor是裡面有目標的foreground anchor,哪些是沒目標的backgroud。所以,僅僅是個二分類而已!
那麼Anchor一共有多少個?原圖800x600,VGG下采樣16倍,feature map每個點設定9個Anchor,所以:
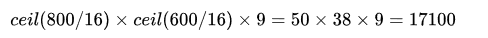
其中ceil()表示向上取整,是因為VGG輸出的feature map size= 50*38。
 看官老爺們,這還不懂?再問Anchor怎麼來的直播跳樓!
看官老爺們,這還不懂?再問Anchor怎麼來的直播跳樓!
4.3 softmax判定foreground與background
一副MxN大小的矩陣送入Faster RCNN網路後,到RPN網路變為(M/16)x(N/16),不妨設 W=M/16,H=N/16。在進入reshape與softmax之前,先做了1x1卷積,如圖9:

圖9 RPN中判定fg/bg網路結構
該1x1卷積的caffe prototxt定義如下:
layer {
name: "rpn_cls_score"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_cls_score"
convolution_param {
num_output: 18 # 2(bg/fg) * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
}
}
可以看到其num_output=18,也就是經過該卷積的輸出影象為WxHx18大小(注意第二章開頭提到的卷積計算方式)。這也就剛好對應了feature maps每一個點都有9個anchors,同時每個anchors又有可能是foreground和background,所有這些資訊都儲存WxHx(9*2)大小的矩陣。為何這樣做?後面接softmax分類獲得foreground anchors,也就相當於初步提取了檢測目標候選區域box(一般認為目標在foreground anchors中)。
那麼為何要在softmax前後都接一個reshape layer?其實只是為了便於softmax分類,至於具體原因這就要從caffe的實現形式說起了。在caffe基本資料結構blob中以如下形式儲存資料:
blob=[batch_size, channel,height,width]
對應至上面的儲存bg/fg anchors的矩陣,其在caffe blob中的儲存形式為[1, 2x9, H, W]。而在softmax分類時需要進行fg/bg二分類,所以reshape layer會將其變為[1, 2, 9xH, W]大小,即單獨“騰空”出來一個維度以便softmax分類,之後再reshape回覆原狀。貼一段caffe softmax_loss_layer.cpp的reshape函式的解釋,非常精闢:
"Number of labels must match number of predictions; "
"e.g., if softmax axis == 1 and prediction shape is (N, C, H, W), "
"label count (number of labels) must be N*H*W, "
"with integer values in {0, 1, ..., C-1}.";
綜上所述,RPN網路中利用anchors和softmax初步提取出foreground anchors作為候選區域。
4.4 bounding box regression原理
如圖9所示綠色框為飛機的Ground Truth(GT),紅色為提取的foreground anchors,即便紅色的框被分類器識別為飛機,但是由於紅色的框定位不準,這張圖相當於沒有正確的檢測出飛機。所以我們希望採用一種方法對紅色的框進行微調,使得foreground anchors和GT更加接近。
 圖10
圖10
對於視窗一般使用四維向量 (x, y, w, h) 表示,分別表示視窗的中心點座標和寬高。對於圖 11,紅色的框A代表原始的Foreground Anchors,綠色的框G代表目標的GT,我們的目標是尋找一種關係,使得輸入原始的anchor A經過對映得到一個跟真實視窗G更接近的迴歸視窗G’,即:
給定:anchor
和
尋找一種變換F,使得:
,其中
。
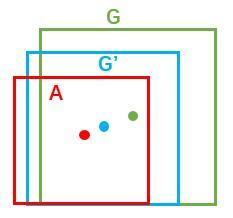 圖11
圖11
那麼經過何種變換F才能從圖10中的anchor A變為G’呢? 比較簡單的思路就是:
-
先做平移
-
再做縮放