
Caffe:CPU模式下使用openblas-openmp(多執行緒版本)
從所周知,所有的深度學習框架使用GPU執行是最快的,但是在不具備Nvidia顯示卡的環境下只使用CPU來執行,慢就慢點吧,對於學習階段還是夠用的。
Caffe用到的Blas可以選擇Altas,OpenBlas,Intel MKL,Blas承擔了大量了數學工作,所以在Caffe中Blas對效能的影響很大。
MKL要收費,Altas略顯慢(在我的電腦上執行Caffe自帶的example/mnist/lenet_solver.prototxt,大概需要45分鐘。。。)
根據網上資料的介紹使用OpenBlas要快一些,於是嘗試安裝使用OpenBlas來加速訓練過程。
我用的系統是CentOS6.5 64位,雙至強處理器(24核),CPU是夠強悍的,只是沒有Nivdia顯示卡
安裝OpenBlas的過程有兩個辦法,最簡單的就是安裝yum源提供的編譯好的二進位制版本。另一個是自己下載原始碼去編譯。現在先講最簡單的yum安裝
yum 安裝
執行
sudo yum install openblas-devel
安裝瞭如下軟體
openblas.x86_64 0.2.18-5.el6 @epel
openblas-devel.x86_64 0.2.18-5.el6 @epel
openblas-openmp.x86_64 0.2.18-5.el6 @epel
openblas-threads.x86_64 0.2.18-5.el6 @epel
OpenBlas這就算安裝好了,簡單吧?
然後,如下編譯Caffe,
#!/bin/sh
# 執行cmake生成Makefile
mkdir build && cd build
cmake -DBLAS=Open -DCPU_ONLY=ON -DBUILD_python=OFF -DBUILD_python_layer=OFF -DBoost_INCLUDE_DIR=/usr/include/boost148 -DBoost_LIBRARY_DIR=/usr/lib64/boost148 ..
# 開始編譯 24執行緒
make install -j 24-DBLAS=Open
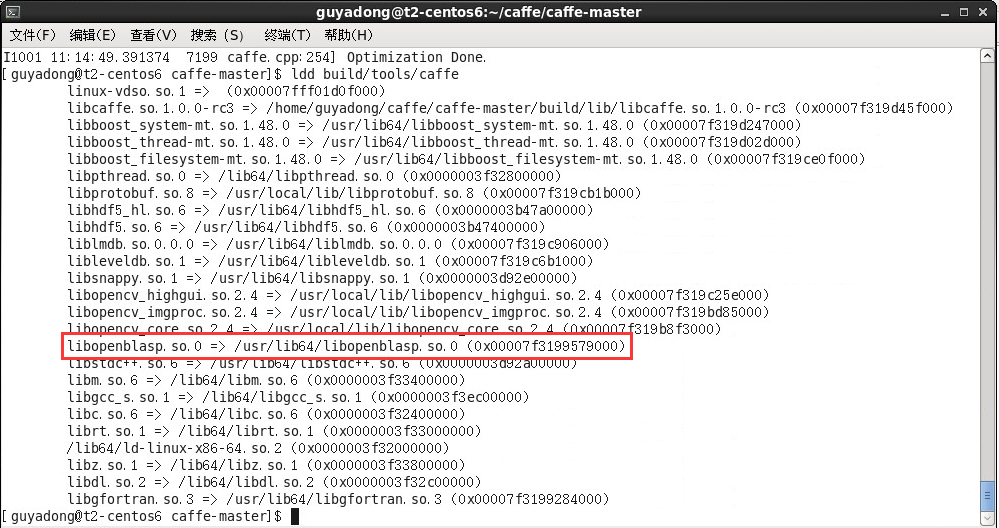
編譯好後,執行ldd檢視caffe的依賴庫,指向了/usr/lib64/libopenblas.so.0
mnist測試
再執行mnist訓練,大概耗時13分鐘,比用altas速度快了3倍多。
./build/tools/caffe train –solver=examples/mnist/lenet_solver.prototxt
但執行時我也發現,雖然電腦有24核,實際只用到一個核,也就是說Caffe在執行時基本上是單執行緒工作的。。。
請注意前面安裝OpenBlas的軟體列表,有一項是openblas-openmp,看到這裡我似乎明白了什麼。到網上一查,果然openblas-openmp是OpenBlas的多執行緒優化版本。
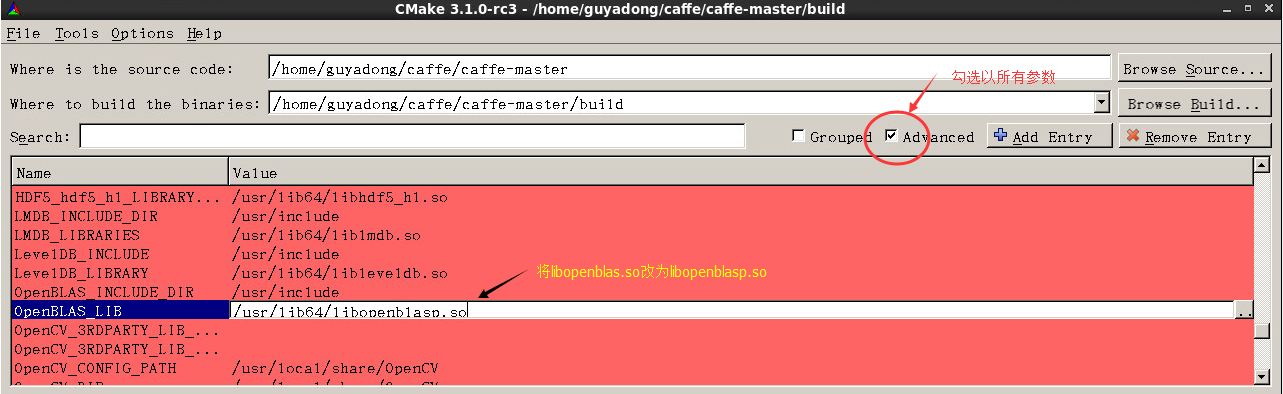
在/usr/lib64下不僅有libopenblas.so.0(單執行緒版本),還有一個libopenblasp.so.0,這個就是前面軟體列表中的openblas-openmp的so檔案(多執行緒版本),

於是用cmake-gui開啟build目錄如下圖將OpenBLAS_LIB改為多執行緒版本,再點”Generate”按鈕重新重新Makefile。
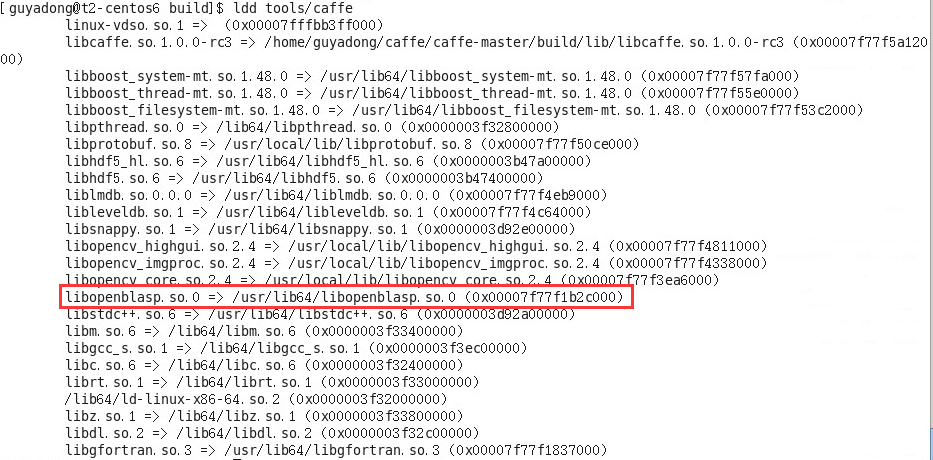
重新執行make編譯Caffe後再執行ldd,顯示已經依賴/usr/lib64/libopenblasp.so.0
再執行mnist訓練,CPU立即被佔滿了
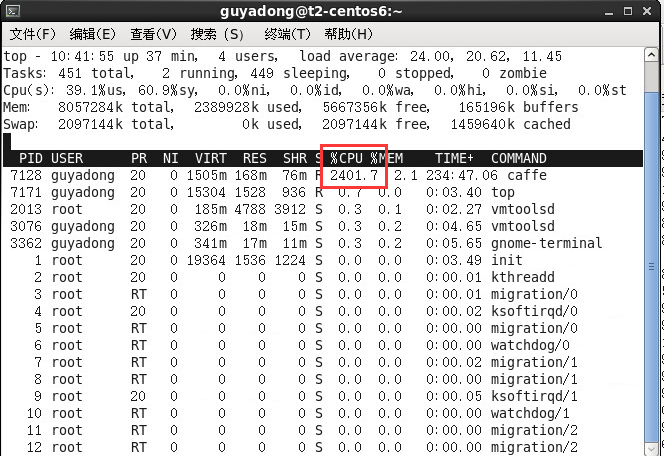
但耗時20分鐘,卻更慢了,為什麼?現在也沒搞明白。
於是修改OMP_NUM_THREADS或(OPENBLAS_NUM_THREADS)引數減少OpenBlas的執行緒數再試
export OMP_NUM_THREADS=4 && ./build/tools/caffe train –solver=examples/mnist/lenet_solver.prototxt
關於OMP_NUM_THREADS和OPENBLAS_NUM_THREADS的詳細用法說明參見《OpenBlas github網站》
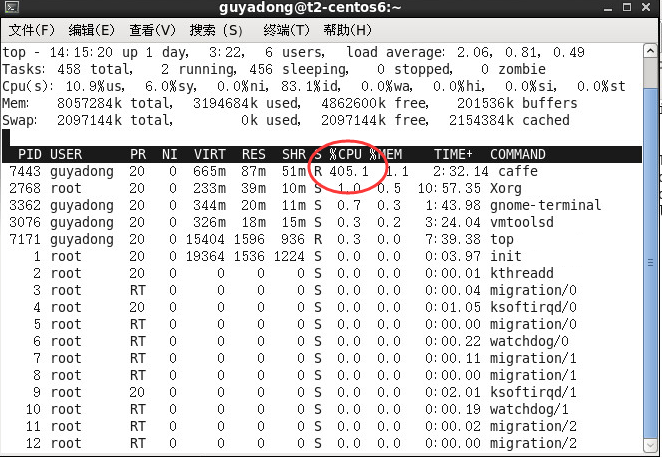
訓練時間減少到10分鐘,CPU跑滿4核
編譯安裝OpenBlas
#!/bin/sh
unzip OpenBLAS-0.2.18.zip
cd OpenBLAS-0.2.18
make USE_OPENMP=1
sudo make install關於OpenBLAS更詳細的安裝說明參見《OpenBLAS編譯和安裝簡介》
預設安裝到/opt/OpenBLAS下,cmake生成Caffe的Makefile時會自動找到,剩下的步驟就和前面一樣了。
最後的問題:
用OpenBlas時,OPENBLAS_NUM_THREADS設定為最大,讓CPU負載跑滿,並不能大幅提高速度,這是為什麼?一直沒搞明白。
看到Caffe上有人提交了《Parallel version of caffe for CPU based on OpenMP》,據說在CPU模式下有高達10倍的但似乎為了減少程式碼維護的複雜性,Caffe官方並沒有接受這個PR。根據Caffe的作者Yangqing Jia的回覆,應該會在Caffe2中解決這個問題。