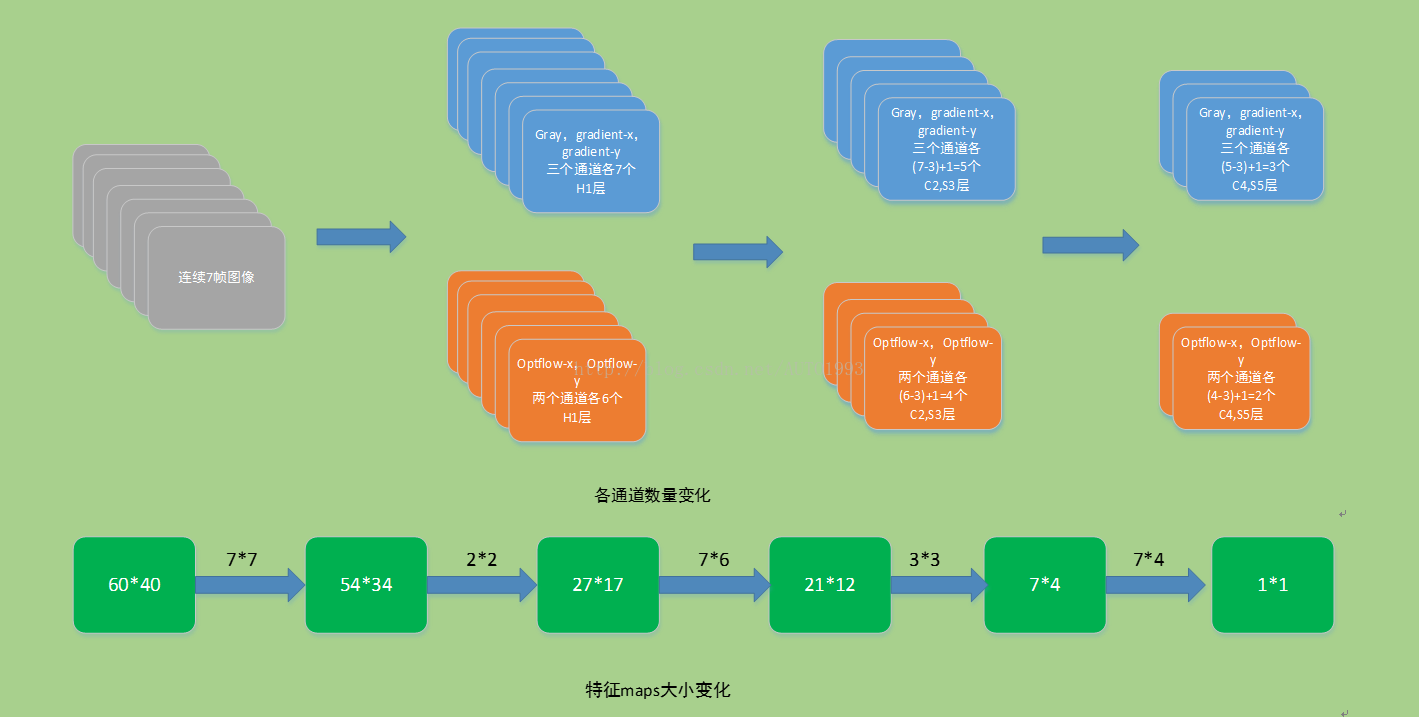
3D CNN框架結構各層計算
3D CNN框架結構各層詳細計算過程
這篇部落格主要詳細介紹3D CNN框架結構的計算過程,我們都知道3D CNN 在視訊分類,動作識別等領域發揮著巨大的優勢,前兩個星期看了這篇文章:3D Convolutional Neural Networks for Human Action Recognition,打算用這個框架應用於動態表情識別,當時對這篇文章的3 D CNN各層maps的計算不怎麼清楚,所以自己另外對3D CNN結構層數maps等等重新計算了一下,下面是主要的計算過程。在介紹計算過程之前,先介紹一下 2D CNN和3D CNN的區別
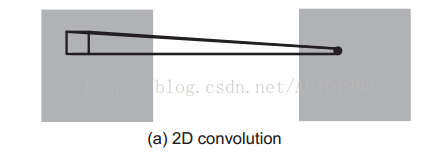
採用2D CNN對視訊進行操作的方式,一般都是對視訊的每一幀影象分別利用CNN來進行識別,這種方式的識別沒有考慮到時間維度的幀間運動資訊。下面是傳統的2DCNN對影象進行採用2D卷積核進行卷積操作:
使用3D CNN能更好的捕獲視訊中的時間和空間的特徵資訊,以下是3D CNN對影象序列(視訊)採用3D卷積核進行卷積操作:
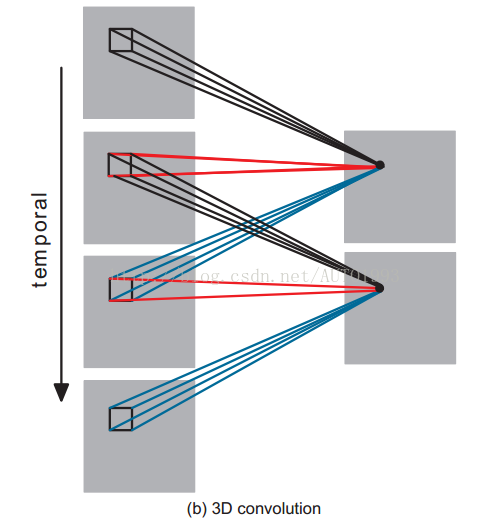
上面進行卷積操作的時間維度為3,即對連續的三幀影象進行卷積操作,上面的 3D卷積是通過堆疊多個連續的幀組成一個立方體,然後在立方體中運用3D卷積核。在這個結構中,卷積層中每一個特徵map都會與上一層中多個鄰近的連續幀相連,因此捕捉運動資訊。例如上面左圖,一個卷積map的某一位置的值是通過卷積上一層的三個連續的幀的同一個位置的區域性感受野得到的。
需要注意的是:3D卷積核只能從cube中提取一種型別的特徵,因為在整個cube中卷積核的權值都是一樣的,也就是共享權值,都是同一個卷積核(圖中同一個顏色的連線線表示相同的權值)。我們可以採用多種卷積核,以提取多種特徵。
3D CNN架構
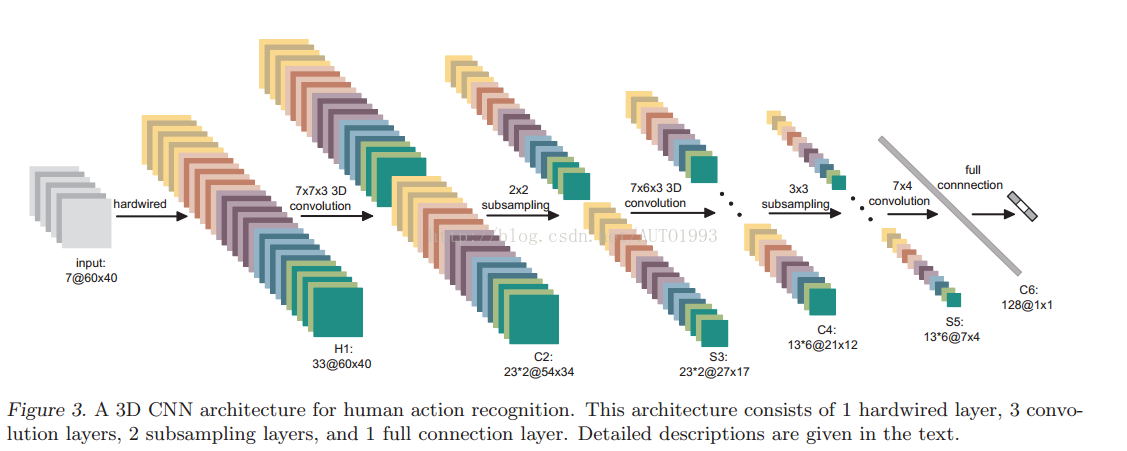
輸入層(input):連續的大小為60*40的視訊幀影象作為輸入。.
硬線層(hardwired,H1):每幀提取5個通道資訊(灰度gray,橫座標梯度(gradient-x),縱座標梯度(gradient-y),x光流(optflow-x),y光流(optflow-y))。前面三個通道的資訊可以直接對每幀分別操作獲取,後面的光流(x,y)則需要利用兩幀的資訊才能提取,因此
H1層的特徵maps數量:(7+7+7+6+6=33),特徵maps的大小依然是60* 40;
卷積層(convolution C2):以硬線層的輸出作為該層的輸入,對輸入5個通道資訊分別使用大小為7* 7 * 3的3D卷積核進行卷積操作(7* 7表示空間維度,3表示時間維度,也就是每次操作3幀影象),同時,為了增加特徵maps的個數,在這一層採用了兩種不同的3D卷積核,因此C2層的特徵maps數量為:
(((7-3)+1)* 3+((6-3)+1)* 2)* 2=23* 2
這裡右乘的2表示兩種卷積核。
特徵maps的大小為:((60-7)+1)* ((40-7)+1)=54 * 34
降取樣層(sub-sampling S3):在該層採用max pooling操作,降取樣之後的特徵maps數量保持不變,因此S3層的特徵maps數量為:23 *2
特徵maps的大小為:((54 / 2) * (34 /2)=27 *17
卷積層(convolution C4):對兩組特徵maps分別採用7 6 3的卷積核進行操作,同樣為了增加特徵maps的數量,文中採用了三種不同的卷積核分別對兩組特徵map進行卷積操作。這裡的特徵maps的數量計算有點複雜,請仔細看清楚了
我們知道,從輸入的7幀影象獲得了5個通道的資訊,因此結合總圖S3的上面一組特徵maps的數量為((7-3)+1) * 3+((6-3)+1) * 2=23,可以獲得各個通道在S3層的數量分佈:
前面的乘3表示gray通道maps數量= gradient-x通道maps數量= gradient-y通道maps數量=(7-3)+1)=5;
後面的乘2表示optflow-x通道maps數量=optflow-y通道maps數量=(6-3)+1=4;
假設對總圖S3的上面一組特徵maps採用一種7 6 3的3D卷積核進行卷積就可以獲得:
((5-3)+1)* 3+((4-3)+1)* 2=9+4=13;
三種不同的3D卷積核就可獲得13* 3個特徵maps,同理對總圖S3的下面一組特徵maps採用三種不同的卷積核進行卷積操作也可以獲得13*3個特徵maps,
因此C4層的特徵maps數量:13* 3* 2=13* 6
C4層的特徵maps的大小為:((27-7)+1)* ((17-6)+1)=21*12
降取樣層(sub-sampling S5):對每個特徵maps採用3 3的核進行降取樣操作,此時每個maps的大小:7* 4
在這個階段,每個通道的特徵maps已經很小,通道maps數量分佈情況如下:
gray通道maps數量= gradient-x通道maps數量= gradient-y通道maps數量=3
optflow-x通道maps數量=optflow-y通道maps數量=2;
卷積層(convolution C6):此時對每個特徵maps採用7* 4的2D卷積核進行卷積操作,此時每個特徵maps的大小為:1*1,至於數量為128是咋來的,就不咋清楚了,估計是經驗值。
對於CNNs,有一個通用的設計規則就是:在後面的層(離輸出層近的)特徵map的個數應該增加,這樣就可以從低階的特徵maps組合產生更多型別的特徵。
通過多層的卷積和降取樣,每連續7幀影象就可以獲得128維的特徵向量。輸出層的單元數與視訊動作數是相同的,輸出層的每個單元與這128維的特徵向量採用全連線。在後面一般採用線性分類器對128維的特徵向量進行分類,實現行為識別,3DCNN模型中所有可訓練的引數都是隨機初始化的,然後通過線上BP演算法進行訓練。
下面是3DCNN各通道數量變化情況以及特徵maps大小變化情況