
SQLSERVER 索引總結
一、儲存結構
在SQL Server中,有許多不同的可用排列規則選項。
二進位制:按字元的數字表示形式排序(ASCII碼中,用數字32表示空格,用68表示字母"D")。因為所有內容都表示為數字,所以處理起來速度最快,遺憾的是,它並不總是如人們所想象,在WHERE子句中進行比較時,使用該選項會造成嚴重的混亂。
字典順序:這種排序方式與在字典中看到的排序方式一樣,但是少有不同,可以設定大量不同的額外選項來決定是否區分大小寫、音調和字符集。
1、平衡樹(B-樹)
平衡樹或B-樹僅是提供了一種以一致且相對低成本的方式查詢特定資訊的方法。其名稱中的"平衡"是自說明的。平衡樹是自平衡的,這意味著每次樹進行分支時都有接近一半的資料在一邊,而另一半資料在另一邊。樹命名的由來是因為,如果繪製該結構,再倒過來,發現很像一棵樹,因此稱樹。
平衡樹始於根節點。如果有少量的資料,這個根節點可以直接指向資料的實際位置。
結構圖:
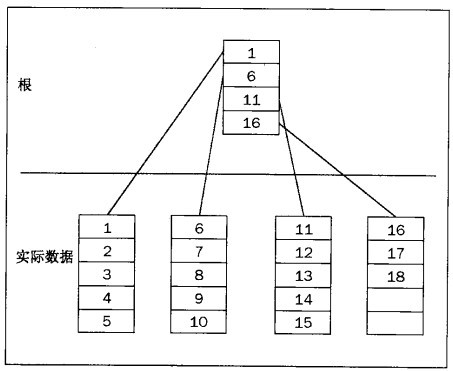
因此,從根節點開始並瀏覽記錄,直到找到以小於查詢值的值開始的最後一頁。然後獲得指向該節點的一個指標並且瀏覽它。直到找到想要的行。
當資料很多時,根節點中指向中間的節點(非頁級節點)。非頁級節點是位於根節點和說明資料的物理儲存位置的節點之間的節點
根節點->中間節點(非葉級節點)[n個]->儲存位置節點(葉級節點)
非葉級節點可以指向其他非葉級節點或葉級節點。葉級節點是從中可獲得實際物理資料的引用的節點。
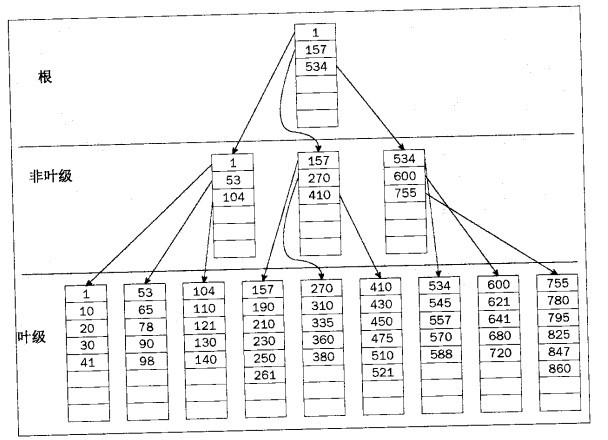
從上圖可以看出,查詢開始於根節點,然後移動到以等於或小於查詢值的最高值開始的同時也在下一級節點中的節點。然後重複這個過程-查詢具有等於或者小於查詢值的最高起始值節點。繼續沿著樹一級一級往下,直到二級節點-從而知道資料的物理位置。
2、頁拆分
所有這些頁在讀取方面工作良好-但在插入時會有點麻煩。前面提到B-樹結構,每次遇到樹中的分支時,因為每一邊都大約有一半的資料,所以B-樹是平衡的。另外,由於新增新資料到樹的方法一般可避免出現不平衡,所以B-樹有時被認為是自平衡的。
通過將資料新增到樹上,節點最終將變滿,並且將需要拆分。因為在 SQL Server中,一個節點相當於一個頁-所以這被稱為頁拆分。如圖所示:
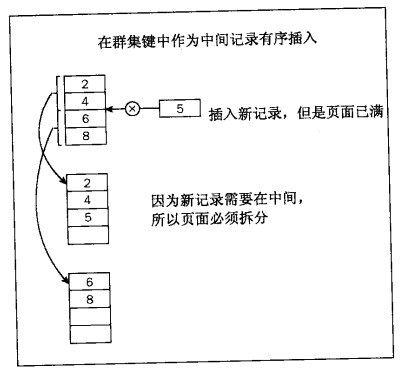
當發生頁拆分時,資料自動地四處移動以保持平衡,資料的前半部分保留在舊頁上,而資料的剩餘部分新增到新頁 - 這樣就形成了對半拆分,使得樹保持平衡。
如果考慮下這個拆分過程,將認識到它在拆分時增加了大量的系統開銷。不只是插入一頁還將進行下列操作:
- 建立新頁
- 將行從現有資料頁移動到新頁上
- 將新行新增到其中一頁上
- 在父節點中新增另一個記錄項
注意最後一條,如果在父節點中新增記錄時,父頁也滿了引起拆分,整個過程會重新開始。甚至會影響到根節點。並且,如果根節點拆分,那麼實際最終會建立兩個額外的頁,因此只能有一個根節點,所以之前的根節點的頁被拆分成兩個頁,而且稱為樹的新中間級別節點。然後建立全新的根節點,並且將有兩個記錄項,指向剛剛由根節點分拆出來的兩個中間節點。
由上面的原理可以知道,當向樹的上層移動時,頁拆分的數量變得越來越少。因為下級的一個頁拆分對上級來說是一條記錄。
雖然SQL Server有許多不同型別的索引,但是所有這些索引都以某種方式利用這種平衡樹方法。事實上由於平衡樹的靈活特性,所有索引在結構上都非常類似,不過他們實際上還有一點點區別,並且這些區別會對系統的效能產生影響。
3、SQL Server中訪問資料的方式
從廣義上講,SQL Server檢索所需資料的方法只有兩種:
- 使用全表掃描
- 使用索引
1、使用全表掃描
表掃描是相當直觀。當執行表掃描時,SQL Server從表的物理起點處開始,瀏覽表中的每一行。當發現和查詢條件匹配的行時,就在結果集中包含它們。關於表掃描很多說法都是效率低,但是如果表資料減少的情況下,實際上使用表掃描卻是最快的。
2、使用索引
在查詢優化過程中,優化器檢視所有可用的索引結構並且選擇最好的一個(這主要基於在連線和WHERE子句中所指定的資訊,以及SQL Server在索引結構中儲存的統計資訊)。一旦選擇了索引,SQL Server將在樹結構中導航至與條件匹配的資料位置,並且只提取它所需的記錄。與表掃描的區別在於,因為資料時排序的,所以查詢引擎知道它何時到達正在查詢的當前範圍的下界。然後它可以結束查詢,或者根據需要移至下一資料範圍。EXISTS的工作方式是查到匹配的記錄SQL Server就立即停止。使用索引所獲得的效能與使用EXISTS類似甚至更好,因為查詢資料的過程的工作方式是類似的;也就是說,伺服器可能使用某種索引知道何時沒有相關內容,並且立即停止。此外,可以對資料執行非常快速的查詢(稱為SEEK),而不是在整個表中查詢。
3、索引型別和索引導航
儘管表面上在SQL Server中有兩種索引結構(聚集索引和非聚集索引),但就內部而言,有3種不同的索引型別。
- 聚集索引
- 非聚集索引,其中非聚集索引又包括以下兩種:
- 堆上的非聚集索引
- 聚集表上的非聚集索引
物理資料的儲存方式在聚集索引和非聚集索引中是不同的。而SQL Server遍歷平衡樹以到達末端資料的方式在所有3種索引型別中也是不同的。
所有的SQL Server索引都有葉級和非葉級頁,葉級是儲存標識記錄的“鍵”的級別,非葉級是葉級的引導者。
索引在聚集表(如果表有聚集索引)或者堆(用於沒有聚集索引的表)上建立。
(1)、聚集表
聚集表是在其上具有聚集索引的任意表。但是它們對於表而言意味著以指定順序物理儲存資料。通過使用聚集索引鍵唯一地標誌獨立的行-聚集鍵即定義聚集索引的列。
如果聚集索引不是唯一的,那將怎樣?如果索引不是唯一索引,那麼聚集索引如何用於唯一地標誌一行?SQL Server會在內部新增一個字尾到鍵上,以保證行具有唯一的識別符號。
(2)、堆
堆是在其上沒有聚集索引的一個表。在這種情況下,基於行的區段、頁以及行偏移量(偏移頁頂部的位置)的組合建立唯一的識別符號,或者稱為行ID(RID)。如果沒有可用的聚集鍵(沒有聚集索引),那麼RID是唯一必要的內容。堆表並不是B樹結構。
4、聚集索引
聚集索引對於任意給定的表而言是唯一的,一個表只能有一個聚集索引。不一定非要有聚集索引。聚集索引特殊的方面是:聚集索引的葉級是實際的資料-也就是說,資料重新排序,按照和聚集索引排序條件宣告的相同物理順序儲存。這意味著,一旦到達索引的葉級,就到達了資料。而非聚集索引,到達了葉級只是找到了資料的引用。
任何新記錄都根據聚集列正確的物理順序插入到聚集索引中。建立新頁的方式隨需要插入記錄的位置而變化。如果新記錄需要插入到索引結構中間,就會發生正常的頁拆分。來自舊頁的後一半記錄被移到新頁,並且在適當的時候,將新記錄插入到新頁或舊頁。如果新記錄在邏輯上位於索引結構的末端,那麼建立新頁,但是隻將新記錄新增到新頁。

從資料插入的角度看,這裡應該能看到用int型別作為聚集索引的好處。
為了說明索引是表的順序,請看一下表:
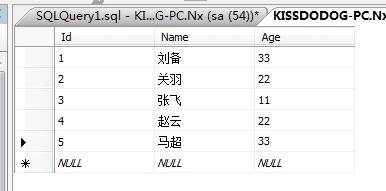
然後在Id列建立聚集索引:
CREATE CLUSTERED INDEX Index_Name ON Person(Id) --建立Id列聚集索引
執行查詢語句:
select top 3 * from Person
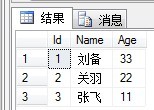
DROP INDEX Person.Index_Name --刪除索引
CREATE CLUSTERED
INDEX Index_Name ON Person(Name) --再在重建Name列聚集索引
再執行查詢語句:
select top 3 * from Person
輸出結果如下:
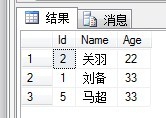
留意到同樣的語句,返回已經改變。可以聚集索引是表的順序,會影響到top語句。
5、導航樹
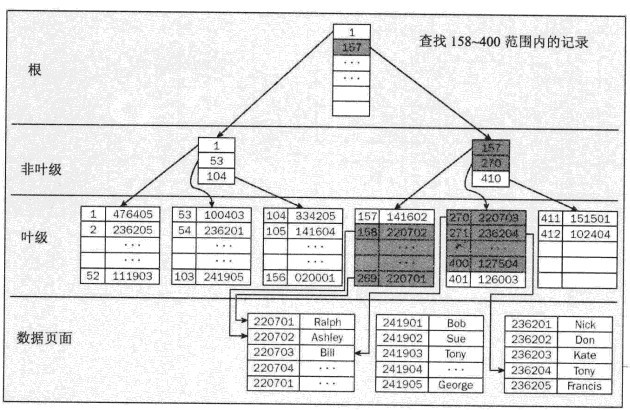
在SQL Server中甚至索引也是儲存在平衡樹中,在理論上,平衡樹在作為樹分支的每個可能方向上總是具有一般的剩餘資訊。聚集索引的平衡樹形式如下圖所示。
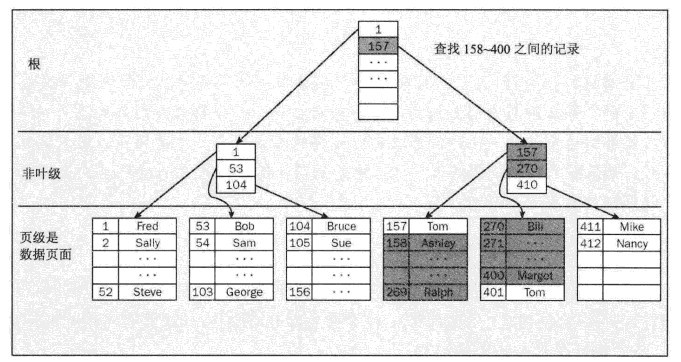
在這裡,執行對數字158-400的範圍查詢(聚集索引非常擅長的事情),只需要導航到第一個記錄,並且包含在該頁上的所有剩餘記錄。之所以知道需要該頁的剩餘部分,是因為來自於上一級節點的資訊也需要來自一些其他頁的資料。因為這是有序表,所以可以確信它是連續的-這意味著如果下一頁有符合條件的記錄,那麼這個頁的剩餘部分必須被包含。無需任何驗證。
首先導航到根節點。SQL Server能夠給予Sys.indexes系統元資料檢視中儲存記錄項定位根節點。
光說不練,純屬詐騙,下面以一個1萬行的PersonTenThousand表來說明B樹結構對資料頁讀取的提升。
表的內容大致如下:

一開始這張表並沒有任何索引:
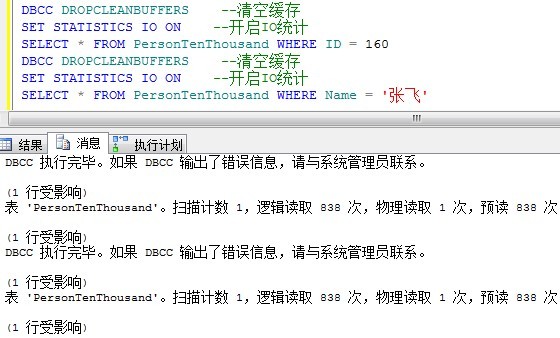
由於此表上沒有索引,因此只能夠通過堆表掃描獲得所需資料,因此,無論是檢索Id,還是Name列,都要整張表掃描一次。因此預讀,邏輯讀都要讀取所有的資料頁。
下面在該表的Id列建立一個聚集索引:
CREATE CLUSTERED INDEX index1 ON PersonTenThousand(ID)
再來執行相同的查詢:

我們看到,由於ID列是聚集索引,因此根據ID查詢,B樹結構的優點就充分發揮了出來,只需要2次物理讀就能夠定位到資料。
而Name列上沒有索引,因此還是需要預讀838次(還是聚集表掃描)才能定位到資料。
以上例子充分說明了B-樹結構的優點。
6、非聚集索引
6.1 非聚集索引優點:
1、因為在SQL Server中一頁只是8K,頁面空間有限,所以一行所包含的列數越少,它能儲存的行就越多。非聚集索引通常不包含表中所有的列,它一般只包含非常少數的列。因此,一個頁上將能包含比錶行(所有的列)更多行的非聚集索引。因此,同樣讀取一頁,在非聚集索引中可能包含200行,但是在表中可能只有10行,具體資料有錶行的大小以及非聚集列的大小確定。
2、非聚集索引的另一個好處是,它有一個獨立於資料表的結構,所以可以被放置在不同的檔案組,使用不同的I/O路徑,這意味著SQL Server可以並行訪問索引和表,使查詢更快速。
下面說明一下,非聚集索引的好處:
![]()
假設有一個單列的表,共有27行,每一頁上存了3行。沒有順序,假如我們要從中查詢值為5的行,那麼需要的讀次數為9,因為它必須掃描到最後一頁,才能夠確定所有頁都不存在值為5的行了。
假如建立了非聚集索引:
![]()
再次查詢值為5的行,那麼需要的讀次數為2,為什麼?因為非聚集索引是有順序的,當SQL Server讀取到值為6的那一行時,就知道不必再讀下去了。那麼如果要讀取值為25的頁呢?還是需要9個讀操作。因為它剛巧就在最後一頁。恰好這個東西,可以通過B樹結構來優化。B樹演算法最小化了定位所需的鍵值訪問的頁面數量,從而加速了資料訪問過程。
6.2 非聚集索引的開銷
索引給效能帶來的好處有一定的代價。有索引的表需要更多的儲存和記憶體空間容納資料頁面之外的索引頁面。資料的增刪改可能會花費更長的時間,需要更多的處理時間以維護不斷變化的表的索引。如果一個INSERT語句新增一行到表中,那麼它也必須新增一行到索引結構中。如果索引是一個聚集索引,開銷可能會更大,因為行必須以正確的順序新增到資料頁面(當然分int聚集列和string聚集列會不同)。UPDATE和DELETE類似。
雖然索引對增刪改有一定的影響,但是別忘了,要UPDATE或DELETE一行的前提是必須找到一行,因此索引實際上對於有複雜WHERE條件的UPDATE或DELETE也是有幫助的。在使用索引定位一行的有效性通常能彌補更新索引所帶來的額外開銷。除非索引設計不合理。
7、堆上的非聚集索引
在這裡要說明一點,無論是在堆上還是在聚集列上,非聚集索引都是排序後儲存的。按非聚集索引列排序。
堆上的非聚集索引和聚集索引在大多數方面以類似的方式工具。其差別如下:
葉級不是資料-相反,它是一個可從中獲得指向該資料的指標的級別。該指標以RID的形式出現(堆上一RID出現,聚集表上以聚集鍵出現),這種RID由索引指向的特定行的區段、頁以及行偏移量構成。即葉級不是實際的資料,使用葉級也僅僅比使用聚集索引多一個步驟。因為RID具有行的位置的全部資訊,所以可以直接到達資料。
差了一個步驟,實際上差別的系統開銷是很大的。
使用聚集索引,資料在物理上是按照聚集索引的順序排列的。這意味著,對於一定範圍的資料,當找到在其上具有資料範圍起點的行時,那麼很可能有其他行在同一頁上(也就是說,因為他們儲存在一起,所以在物理上已幾乎到達下一個記錄)。
使用堆,資料並未通過除索引外的其他方法連線在一起。從物理上看,絕對沒有任意種類的排序。這意味著從物理讀取的角度看,系統不得不從整個檔案中檢索記錄。實際上,很可能最終多次從同樣的頁中取出資料。SQL Server沒有方法指導它將需要回到該物理位置,因為在資料之間沒有連線。因此,堆上的非聚集索引的工作方式是:通過掃描堆上的非聚集索引,找到(Row_Number行號),每找到一個RID,再通過RID取得資料。如果搜尋是返回多個記錄,則效能可能比不上掃描全表。下圖顯示用堆上的非聚集索引執行與上面聚集索引相同的查詢:
主要通過索引導航,一切都按以前的方式工作,以相同的根節點開始,,並且遍歷數,處理越來越集中的頁。直到到達索引的葉級。這裡有了區別。以聚集索引的方式,能夠正好在這裡停止,而以非聚集索引的方式,則需要做更多的工作。如果索引是在堆上,那麼只要在進入一個級別,獲得來自葉級頁的RID,並且定位到該RID-直到這時才可以直接獲得實際的資料。
8、聚集表上的非聚集索引
使用聚集表上的非叢集索引時,還有一些類似性-但同樣也有區別。和堆上的非叢集索引一樣,索引的非葉級及誒單的工作與使用聚集索引時幾乎一樣。區別出現在葉級。
在葉級,與使用其他兩種索引結構所看到的內容有相當明顯的區別。聚集表上的非叢集索引有另外一個索引來查詢。使用聚集索引,當到達葉級時,可以找到實際的資料,當使用堆上的非叢集索引,不能找到實際的資料,但是可以找到能夠直接獲得資料的識別符號(僅僅多了一步)。使用聚集表上的非聚集索引,可以找到聚集鍵。也就是說,找到足夠的資訊繼續並利用聚集索引。
以上理解,說白了就是,當使用非聚集索引時,就是遍歷非聚集索引找到聚集索引,最後多次採用聚集索引找到資料。
最終結果如下圖所示:
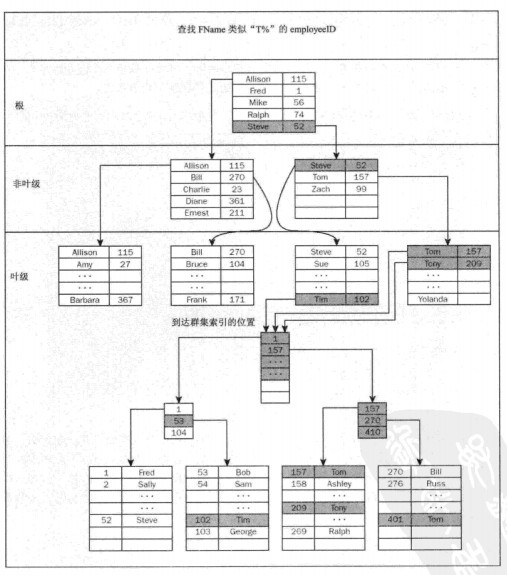
首先是一個範圍搜尋。在索引中執行一次單獨的查詢,並且可以瀏覽非聚集索引以找到滿足條件(T%)的連續資料範圍。這種能夠直接到達索引中的特定位置的查詢被稱為seek。
然後第二個查詢-使用聚集索引查詢,第二種查詢非常迅速:問題在於它必須執行多次。可以看到。SQL Server從第一個索引中查詢檢索列表(所有名字以"T"開始的列表),但是該列表在邏輯上並沒有以任意連續的方式與聚集鍵相匹配-每個記錄單獨地查詢。圖下圖所示:

自然,這種多個查詢的情況比一開始僅能使用聚集索引引入了更多的系統開銷。第一個索引查詢-通過非聚集索引的方法-只需要非常少的邏輯讀操作。
注意上圖,使用聚集表上的非聚集索引,找到的是一個聚集索引鍵的列表。然後用這個列表,逐個使用聚集索引查詢到所需的資料。
注意,如果表沒有聚集索引,建立了非聚集索引,那麼非聚集索引使用的是行號,如果此時你又添加了聚集索引,那麼所有的非聚集索引引用的RID都要改為聚集索引鍵。這對效能的消耗是非常大的,因此最好先建立聚集索引,在建立非聚集索引。
關於索引的幾個要點:
- 群集索引通常比非群集索引快(書籤)。
- 僅在將得到高級別選擇性的列(90%以上)上放置非群集索引。
- 所有的資料操作語言(DML:INSERT、UPDATE、DELETE、SELECT)語句可以通過索引獲益,但是插入、刪除和更新會因為索引而變慢。
- 索引會佔用空間。
- 僅當索引中的第一列和查詢相關時才使用索引。
- 索引的負面影響和它的正面影響一樣多 - 因此只建立需要的索引。
- 索引可為非結構化XML資料提供結構化的資料效能,但是要記住,和其他索引一樣,會涉及到系統開銷。
在SQL Server中,非聚集索引其實可以看做是一個含有聚集索引的表,但相對實際的表來說,非聚集索引中所儲存的表的列數要少得多,一般就是索引列,聚集鍵(或RID)。非聚集索引僅僅包含源表中的非聚集索引的列和指向實際物理表的指標。
二、非聚集索引之INCLUDE
非聚集索引其實可以看做一個含有聚集索引的列表,當這個非聚集索引中包含了查詢所需要的所有資訊的時候,則就不再需要去查基本表,僅僅做非聚集索引就能夠得到所需要的資料。INCLUDE實際上也能稱為覆蓋索引,但它不影響索引鍵的大小。
先來看下面一張表:
此表大約是15萬資料左右。聚集索引列是Id,我們先來在Name列建立一個非聚集索引。
CREATE NONCLUSTERED INDEX Index_Name ON Person(Name)
然後執行查詢:
SELECT Name,Age FROM Person where Name = '歐琳琳'
執行計劃如下:
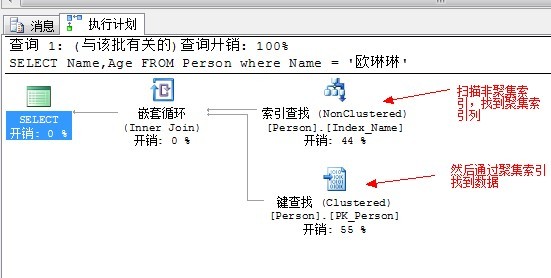
上面的執行過程是,先掃描非聚集索引列,找到聚集索引,然後在通過聚集索引定位到資料。
下面我們刪除掉剛才那個索引,再建過另外一個。
DROP INDEX Person.Index_Name --刪除非聚集索引Index_Name CREATE NONCLUSTERED --再重新建過一次,這次我們INCLUDE Age列 INDEX Index_Name ON Person(Name) INCLUDE (Age)
現在我們再來看看剛才的查詢的執行計劃:
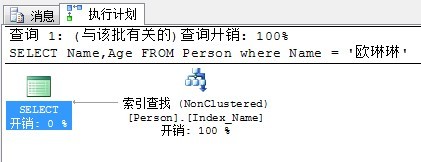
由於Age列也被INCLUDE進了非聚集索引INDEX_Name中,因此這次僅僅通過查詢非聚集索引就能夠得到所需的全部資料。不需要再掃描聚集索引了。明顯這次查詢要比剛才快。
要注意的是INCLUDE進來的列,並不作為索引使用,能當索引掃描的,只是索引列。
INCLUDE最好在以下情況中使用:
- 你不希望增加索引鍵的大小,但是仍然希望有一個覆蓋索引;
- 你打算索引一種不能被索引的資料型別(除了文字、ntext和影象);
- 你已經超過了一個索引的關鍵字列的最大數量(但是最好避免這個問題);
二、非聚集索引之覆蓋
索引覆蓋指的是:建立的索引使得-SQL查詢不用到達基本表僅僅通過索引查詢就得到了所需資料。
如果查詢遇到一個索引並且完全不需要引用資料表就得到了所需資料,那麼這個索引就可以稱為覆蓋索引。覆蓋索引對於減少查詢的邏輯讀是一種有用的技術。
下面刪除之前建立的索引,在來看看索引的覆蓋。
CREATE NONCLUSTERED INDEX INDEX_NAME ON Person(Name,Age) SELECT Name,Age FROM Person WHERE Name = '歐琳琳'
看看執行計劃:

可以看到,也是僅僅查找了非聚集索引就得到了結果。效率非常快。
下面來看看覆蓋和前面的INCLUDE有什麼區別呢?我們將搜尋條件改為Age。
覆蓋索引:

INCLUDE:
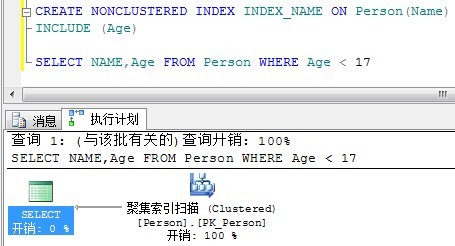
留意一下,INCLUDE是聚集表掃描了,而覆蓋索引依然使用非聚集索引就找到了結果。
因此可以得出結論,INCLUDE列並不能當索引鍵使用。
為了利用覆蓋索引,要注意SELECT語句的清單,應儘可能使用較少的列來保持小的覆蓋索引的尺寸,使用INCLUDE語句來新增的列這時候才有意義。
在建立許多覆蓋索引之前,考慮SQL Server如何有效和自動地使用索引交叉來為查詢即時建立覆蓋索引。
三、非聚集索引的交叉
如果一個表有多個索引,那麼SQL Server可以使用多個索引來執行一個查詢。SQL Server可以利用多個索引,根據每個索引選擇小的資料子集,然後執行兩個子集的一個交叉(即只返回滿足所有條件的那些行)。SQL Server可以在一個表上開發多個索引,然後使用一個演算法來在兩個子集中得到交叉(可以理解為求交集)。
我們先刪除掉前面建立的索引,再來新建過:
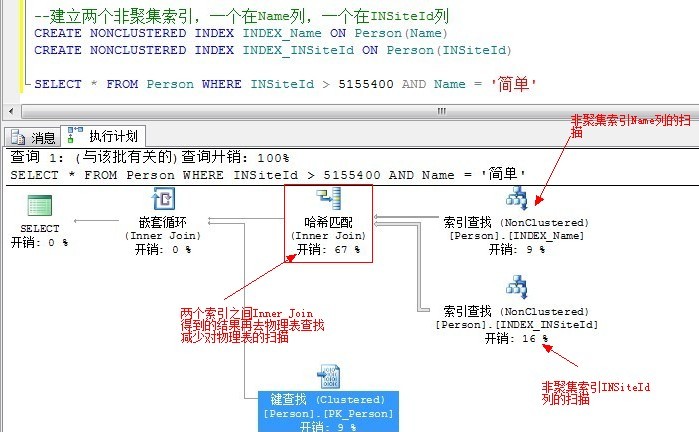
非聚集索引的本質是表,通過額外建立表使得幾個非聚集索引之間進行像表一樣的Join,從而使非聚集索引之間可以進行Join來在不訪問基本表的情況下給查詢優化器提供所需要的資料。
為了增進一個查詢的效能,SQL Server可以在表上使用多個索引。因此,考慮建立多個窄索引來代替寬的索引鍵。SQL Server能夠在需要的時候一起使用它們,當不需要時,查詢可以從窄索引中獲益。在建立一個覆蓋索引時,需要確定索引的寬度是否可以接受,使用包含列是否可以完成任務。如果不行則確定現有的包含大部分覆蓋索引所需要的列的非聚集索引。如果有可能,適當重新安排現有非聚集索引的列順序,使優化器能夠考慮兩個非聚集索引之間的的一個索引交叉。
有時候,可能必須為一下原因建立一個單獨的非聚集索引:
- 重新排列現有索引中的列不被允許;
- 覆蓋索引所需要的一些列不能被包含在現有的非聚集索引中;
- 兩個現有非聚集索引中的總列數可能多於覆蓋索引所需要的列數;
在這些情況下,可以在剩下的列上建立非聚集索引。如果新索引符合和現有索引符合覆蓋索引的要求,優化器將能夠使用索引交叉。在為新確定列及其順序時,也要注意其他查詢,以嘗試使其最大化。
四、非聚集索引的連線
索引連線是索引交叉的特例,它將覆蓋索引技術應用到索引交叉。如果沒有單個覆蓋查詢的索引而存在多個索引一起可以覆蓋該查詢,SQL Server可以使用索引連線來完全滿足查詢而不需要轉到基本表。
非聚集索引的連線實際上是非聚集索引的交叉的一種特例。使得多個非聚集索引交叉後可以覆蓋所要查詢的資料,從而使得從減少查詢基本表變成了完全不用查詢基本表。

--建立兩個非聚集索引,一個在Name列,一個在INSiteId列 CREATE NONCLUSTERED INDEX INDEX_Name ON Person(Name) INCLUDE(Age) --索引還是剛才的索引,但是包含多一列 CREATE NONCLUSTERED INDEX INDEX_INSiteId ON Person(INSiteId) INCLUDE(Height) --同上 SELECT Name,Age,Height,INSiteId FROM Person WHERE INSiteId > 5155400 AND Name = '簡單' --注意條件,索引連線剛好能覆蓋所需資料,從而避免查詢基本表
檢視結果:
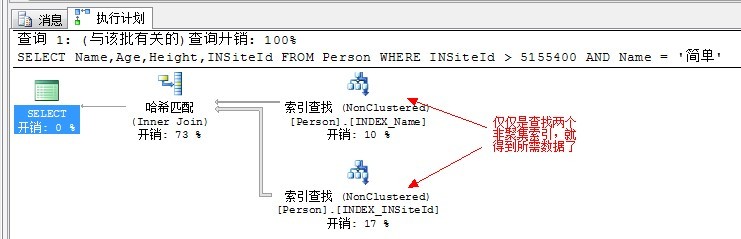
索引交叉和索引連線有什麼區別呢?前面說到果,索引連線是索引交叉的特例。索引連線在交叉了之後,不用再轉到基本表,少了一步書籤查詢。而索引交叉之後,還有一步書籤查詢轉到基本表獲得資料,因為索引交叉的返回列並不能完全符合SELECT的列。
五、非聚集索引的過濾
過濾索引是使用過濾器的非聚集索引,這個過濾器基本上是一個WHERE子句,用來在可能沒有很好選擇性的一個或多個列上建立一個高選擇性的關鍵字組。
例如,一個具有大量NULL值的列可能被儲存為稀疏列來降低這些null值的開銷。在這個列新增一個過濾索引將使你擁有在不是null的資料上的索引。
在下面的所使用的Person表中,Name列有超過50%是NULL值,執行查詢:
SELECT Name,Age FROM Person WHERE Name IS NOT NULL

這是一個聚集表掃描,並沒有有效地使用索引。
當我們建立非聚集索引,且加上過濾後:INCLUDE()是為了形成覆蓋索引。
CREATE NONCLUSTERED INDEX INDEX_Name ON Person(Name) INCLUDE(Age) WHERE Name IS NOT NULL --過濾的索引上過濾掉NULL值的行

在我的資料庫當中,建立索引,加不加過濾沒太大區別(因為很遺憾,Name列基本上沒有NULL的),但是當過濾條件IS NOT NULL能夠過濾很多條資料的時候,這時過濾的作用才能夠展示出來。如果過濾條件,能夠篩選掉很多條資料,那麼效能無疑會大有提升。
過濾索引再許多方面帶來回報:
- 減少索引尺寸從而增進查詢效率;
- 建立更小的索引降低儲存開銷;
- 因為尺寸減小,降低了索引維護的成本;
實際上,索引的維護主要包括以下兩個方面:
- 頁拆分
- 碎片
這兩個問題都和頁密度有關,雖然兩者的表現形式在本質上有所區別,但是故障排除工具是一樣的,因為處理是相同的。
對於非常小的表(比64KB小得多),一個區中的頁面可能屬於多餘一個的索引或表---這被稱為混合區。如果資料庫中有太多的小表,混合區幫助SQL Server節約磁碟空間。
隨著表(或索引)增長並且請求超過8個頁面,SQL Server建立專用於該表(或索引)的區並且從該區中分配頁面。這樣一個區被稱為統一區,它可以為多達8個相同表或索引的頁面請求服務。
一、碎片
當資料庫增長,頁拆分,然後刪除資料時,就會產生碎片。從增長的方面看,平衡樹處理得很不錯。但是對於刪除方面,它並沒有太大的作用。最終可能會出現這種情況,一個頁上有一條記錄,而另一個頁上有幾個記錄。在這種情況下,一個頁上儲存的資料量只是它能夠儲存總資料量的一小部分。
1、碎片會造成空間的浪費,SQL Server每次會分配一個區段,如果一個頁上只有一條記錄,則仍然會分配整個區段。
2、散佈在各處的資料會造成資料檢索時的額外系統開銷。為了獲取需要的10行記錄,SQL Server不是隻載入一個頁,而是可能必須載入10個頁來獲取相同的資訊。並不只是讀取行導致了這一結果,在讀取行前,SQL Server必須先讀取頁。更多的頁意味著更多的工作量。
但是碎片也不只是有壞處,比如一個插入非常頻繁的表就很喜歡碎片,因為在插入資料時幾乎不用擔心頁拆分的問題。所以大量的碎片意味著較差的讀取效能,但也意味著極好的插入效能。
碎片分兩種,外部碎片和內部碎片
外部碎片:
外部碎片指的是頁拆分而產生的碎片。如向表中插入一行,而這一行導致現有的頁空間無法容納新插入的行,則導致頁拆分。

新的頁不斷隨資料的增長而產生,而聚集索引要求行之間連續,所以如果聚集索引不是自增列,頁拆分後和原來的頁在磁碟上並不連續-這就是外部碎片。 由於頁拆分,導致資料在頁之間的移動,所以如果插入更新等操作經常需要分頁,則會大大消耗IO資源,造成效能下降。 對於查詢連說,在有特定搜尋條件,如where子句有很細的限制或者返回無序結果集時,外部碎片並不會對效能產生影響。但如果要返回掃描聚集索引而且查詢連續頁面時,外部碎片就會產生效能上的影響。所以當要讀取相同的數連續的資料時需要掃描更多的頁,更多的區。而且連續資料不能預讀,造成額外的物理讀,增加磁碟IO。通常,外部碎片過多會造成頻繁的區切換。
如果頁面連續排序,預讀功能可以提前讀取頁面而不需要太多的磁頭移動。
內部碎片:
內部碎片是頁拆分後,導致索引頁的資料並不滿,有空行。同樣讀取一個索引頁,卻只能拿到x%的資料。
--新建一張表
CREATE TABLE Person
(
Id int,
Name char(999),
Addr varchar(10)
)
--聚集索引
CREATE CLUSTERED INDEX CIX ON Person(Id)
--插入8條資料
DECLARE @var INT
SET @var=100
WHILE(@var < 900)
BEGIN
INSERT INTO Person(Id,Name,Addr)
VALUES(@var,'xx','')
SET @var = @var+100
END
這個表每個行由int(4位元組),char(999位元組)和varchar(10位元組組成),所以每行為1003個位元組,則8行佔用空間1003*8=8024位元組加上一些內部開銷,可以容納在一個頁面中。(原來這個表和資料搞得還挺巧的)。
執行檢視語句:
SELECT page_count,avg_page_space_used_in_percent,record_count,avg_record_size_in_bytes,avg_fragmentation_in_percent,fragment_count
FROM sys.dm_db_index_physical_stats
(DB_ID('Nx'),object_id('dbo.Person'),NULL,NULL,'sampled')
示例如下:

其中page_count是檢視佔用了多少個頁,而第二個引數表示該頁空間的使用率。因此從以上資訊可以獲得,這8條資料是放在一個頁上,而且該頁的空間使用率已經是百分之百了。
現在將其中一行的Addr改長一點:
UPDATE Person SET Addr = '廣東廣州' where Id = 100
則再執行檢查索引語句:

可以看到,這個表已經有了兩頁,頁面平均使用為50%左右。但是明顯也造成了碎片,在列avg_fragmentation_in_percent上可以看到,碎片大約為50%。
頁拆分後的示意圖如下:

這個時候,繼續插入資料,碎片會上升。在又插入了至達到48條記錄後,碎片程度如下:

這個時候,執行一個查詢計劃,檢視下IO效能:

可以看到I/O下降了不少。
二、元資料函式sys.dm_db_index_physical_stats分析碎片
SQL Server提供了一種特殊的元資料函式sys.dm_db_index_physical_stats,它有助於確定資料庫中的頁和區段有多滿。然後用該資訊作出一些維護資料庫的決策。
該函式語法如下:
sys.dm_db_index_physical_stats(
{<database id> | NULL | 0 | DEFAULT},
{ <object id> | NULL | 0 | DEFAULT },
{ <index id> } | NULL | 0 | -1 | DEFAULT },
{ <partition no> | NULL | 0 | DEFAULT },
{ <mode> | NULL | DEFAULT }
)
下面假設從SmartScan中獲取所有的索引資訊:
DECLARE @db_id SMALLINT; DECLARE @object_id INT; SET @db_id = DB_ID(N'Nx'); SET @object_id = OBJECT_ID(N'Account') SELECT database_id,object_id,index_id,index_depth,avg_fragmentation_in_percent,page_count FROM sys.dm_db_index_physical_stats(@db_id,@object_id,NULL,NULL,NULL);
下面看看統計資訊的說明:
|
列名 |
資料型別 |
說明 |
||
|---|---|---|---|---|
|
database_id |
smallint |
表或檢視的資料庫 ID。 |
||
|
object_id |
int |
索引所在的表或檢視的物件 ID。 |
||
|
index_id |
int |
索引的索引 ID。 0 = 堆。 |
||
|
partition_number |
int |
所屬物件內從 1 開始的分割槽號;表、檢視或索引。 1 = 未分割槽的索引或堆。 |
||
|
index_type_desc |
nvarchar(60) |
索引型別的說明: HEAP CLUSTERED INDEX NONCLUSTERED INDEX PRIMARY XML INDEX SPATIAL INDEX XML INDEX |
||
|
alloc_unit_type_desc |
nvarchar(60) |
對分配單元型別的說明: IN_ROW_DATA LOB_DATA ROW_OVERFLOW_DATA LOB_DATA 分配單元包含型別為text、ntext、image、varchar(max)、nvarchar(max)、varbinary(max) 和 xml 的列中所儲存的資料。 ROW_OVERFLOW_DATA 分配單元包含型別為 varchar(n)、nvarchar(n)、varbinary(n) 和sql_variant 的列(已推送到行外)中所儲存的資料。 |
||
|
index_depth |
tinyint |
索引總級別數。 1 = 堆,或 LOB_DATA 或 ROW_OVERFLOW_DATA 分配單元。 |
||
|
index_level |
tinyint |
索引的當前位於B樹結構中的級別。 0 表示索引葉級別、堆以及 LOB_DATA 或 ROW_OVERFLOW_DATA 分配單元。 大於 0 的值表示非葉索引級別。 index_level 在索引的根級別中屬於最高級別。 僅當 mode = DETAILED 時才處理非葉級別的索引。 |
||
|
avg_fragmentation_in_percent |
float |
索引的邏輯碎片,或 IN_ROW_DATA 分配單元中堆的區碎片。 此值按百分比計算,並將考慮多個檔案。 0 表示 LOB_DATA 和 ROW_OVERFLOW_DATA 分配單元。 如果是堆表且mode模式 為 Sampled 時,為 NULL。如果碎片小於10%~20%,碎片不太可能會成為問題,如果索引碎片在20%~40%,碎片可能成為問題,但是可以通過索引重組來消除索引解決,大規模的碎片(當碎片大於40%),可能要求索引重建。 |
||
|
fragment_count |
bigint |
IN_ROW_DATA 分配單元的葉級別中的碎片數。 對於索引的非葉級別,以及 LOB_DATA 或 ROW_OVERFLOW_DATA 分配單元,為 NULL。 對於堆,當 mode 為 SAMPLED 時,為 NULL。 |
||
|
avg_fragment_size_in_pages |
float |
IN_ROW_DATA 分配單元的葉級別中的一個碎片的平均頁數。 對於索引的非葉級別,以及 LOB_DATA 或 ROW_OVERFLOW_DATA 分配單元,為 NULL。 對於堆,當 mode 為 SAMPLED 時,為 NULL。 |
||
|
page_count |
bigint |
索引或資料頁的總數。 對於索引,表示 IN_ROW_DATA 分配單元中 b 樹的當前級別中的索引頁總數。 對於堆,表示 IN_ROW_DATA 分配單元中的資料頁總數。 對於 LOB_DATA 或 ROW_OVERFLOW_DATA 分配單元,表示該分配單元中的總頁數。 |
||
|
avg_page_space_used_in_percent |
float |
所有頁中使用的可用資料儲存空間的平均百分比。 對於索引,平均百分比應用於 IN_ROW_DATA 分配單元中 b 樹的當前級別。 對於堆,表示 IN_ROW_DATA 分配單元中所有資料頁的平均百分比。 對於 LOB_DATA 或 ROW_OVERFLOW DATA 分配單元,表示該分配單元中所有頁的平均百分比。 當 mode 為 LIMITED 時,為 NULL。 |
||
|
record_count |
bigint |
總記錄數。 對於索引,記錄的總數應用於 IN_ROW_DATA 分配單元中 b 樹(包括非葉子資料頁的數量)的當前級別。 對於堆,表示 IN_ROW_DATA 分配單元中的總記錄數。
對於 LOB_DATA 或 ROW_OVERFLOW_DATA 分配單元,表示整個分配單元中總記錄數。 當 mode 為 LIMITED 時,為 NULL。 |
||
|
ghost_record_count |
bigint |
分配單元中將被虛影清除任務刪除的虛影記錄數。 對於 IN_ROW_DATA 分配單元中索引的非葉級別,為 0。 當 mode 為 LIMITED 時,為 NULL。 |
||
|
version_ghost_record_count |
bigint |
由分配單元中未完成的快照隔離事務保留的虛影記錄數。 對於 IN_ROW_DATA 分配單元中索引的非葉級別,為 0。 當 mode 為 LIMITED 時,為 NULL。 |
||
|
min_record_size_in_bytes |
int |
最小記錄大小(位元組)。 對於索引,最小記錄大小應用於 IN_ROW_DATA 分配單元中 b 樹的當前級別。 對於堆,表示 IN_ROW_DATA 分配單元中的最小記錄大小。 對於 LOB_DATA 或 ROW_OVERFLOW_DATA 分配單元,表示整個分配單元中的最小記錄大小。 當 mode 為 LIMITED 時,為 NULL。 |
||
|
max_record_size_in_bytes |
int |
最大記錄大小(位元組)。 對於索引,最大記錄的大小應用於 IN_ROW_DATA 分配單元中 b 樹的當前級別。 對於堆,表示 IN_ROW_DATA 分配單元中的最大記錄大小。 對於 LOB_DATA 或 ROW_OVERFLOW_DATA 分配單元,表示整個分配單元中的最大記錄大小。 當 mode 為 LIMITED 時,為 NULL。 |
||
|
avg_record_size_in_bytes |
float |
平均記錄大小(位元組)。 對於索引,平均記錄大小應用於 IN_ROW_DATA 分配單元中 b 樹的當前級別。 對於堆,表示 IN_ROW_DATA 分配單元中的平均記錄大小。 對於 LOB_DATA 或 ROW_OVERFLOW_DATA 分配單元,表示整個分配單元中的平均記錄大小。 當 mode 為 LIMITED 時,為 NULL。 |
||
|
forwarded_record_count |
bigint |
堆中具有指向另一個數據位置的轉向指標的記錄數。 (在更新過程中,如果在原始位置儲存新行的空間不足,將會出現此狀態。) 除 IN_ROW_DATA 分配單元外,對於堆的其他所有分配單元都為 NULL。 當 mode = LIMITED 時,對於堆為 NULL。 |
||
|
compressed_page_count |
bigint |
壓縮頁的數目。
|
通常返回多行的時候,有個index_level列,這個列表示改行屬於B樹結構的第幾層。
分析小表的碎片
不要過分關注小表的sys.dm_db_index_physical_stats輸出。對於少於8個頁面的小表或者索引,SQL Server使用混合區。例如,如果一個表僅包含兩個頁面,SQL Server從一個混合區中分配兩個頁面,二不是分配一個區給該表。混合區也可以包含其他小表或索引的頁面。
跨越多個混合區的頁面分佈可能導致你相信在表或索引中有大量的外部碎片,而實際上這是SQL Server的設計,因而是可接受的。
先來建一張表如下,3個int欄位,1個char(2000)欄位。平均尺寸為4+4+4+2000=2012位元組,8KB的頁面最多包含4行。在添加了28行之後,建立一個聚集索引來從屋裡上排列行並將碎片減少到最低限度。

咋一看,好像碎片非常厲害。實際上並不是這麼回事。
分析如下:
- avg_fragmentation_in_percent:儘管這個索引可能跨越多個區,這裡看到碎片的情況並不是外部碎片的跡象,因為該索引儲存在混合區上。
- avg_page_space_used_in_percent:這說明所有或大部分縣市在page_count中的7個頁面中的資料儲存狀況良好。幾乎滿了,99點幾。這消除了邏輯碎片的可能性。
- fragment_count:這說明資料有碎片並且儲存在多於一個區上,但是因為它的長度小於8個頁面,SQL Server對儲存該資料的地點沒有很多選擇。
儘管有上述引起誤導的數值,一個少於8個頁面的小表(或索引)不可能從去除碎片的工作中獲益,因為它儲存在混合區上。
索引說明:

三、關於碎片的解決方法
1.刪除索引並重建
這種方式有如下缺點:
索引不可用:在刪除索引期間,索引不可用。
阻塞:解除安裝並重建索引會阻塞表上所有的其他請求,也可能被其他請求所阻塞。
對於刪除聚集索引,則會導致對應的非聚集索引重建兩次(刪除時重建,建立時再重建,因為非聚集索引中有指向聚集索引的指標)。
唯一性約束:用於定義主鍵或者唯一性約束的索引不能使用DROP INDEX語句刪除。而且,唯一性約束和主鍵都可能被外來鍵約束引用。在主鍵解除安裝之前,所有引用該主鍵的外來鍵必須首先被刪除。儘管可以這麼做,但這是一種冒險而且費時的碎片整理方法。
基於以上原因,不建議在生產資料庫,尤其是非空閒時間不建議採用這種技術。
2.使用DROP_EXISTING語句重建索引
為了避免重建兩次索引,使用DROP_EXISTING語句重建索引,因為這個語句是原子性的,不會導致非聚集索引重建兩次,但同樣的,這種方式也會造成阻塞。
CREATE UNIQUE CLUSTERED INDEX IX_C1 ON t1(c1) WITH (DROP_EXISTING = ON)
缺點:
阻塞:與解除安裝重建方法類似,這種技術也導致並面臨來自其他訪問該表(或該表的索引)的查詢的阻塞問題。
使用約束的索引:與解除安裝重建不同,具有DROP_EXISTING子句的CREATE INDEX語句可以用於重新建立使用約束的索引。如果該約束是一個主鍵或與外來鍵相關的唯一性約束,在CREATE語句中不能包含UNIQUE。
具有多個碎片化的索引的表:隨著表資料產生碎片,索引常常也碎片化。如果使用這種碎片整理技術,表上所有索引都必須單獨確認和重建。
3.使用ALTER INDEX REBUILD語句重建索引
使用這個語句同樣也是重建索引,但是通過動態重建索引而不需要解除安裝並重建索引.是優於前兩種方法的,但依舊會造成阻塞。可以通過ONLINE關鍵字減少鎖,但會造成重建時間加長。
阻塞:這個依然有阻塞問題。
事務回滾:ALTER INDEX REBUILD完全是一個原子操作,如果它在結束前停止,所有到那時為止進行的碎片整理操作都將丟失,可以通過ONLINE關鍵字減少鎖,但會造成重建時間加長。
4.使用ALTER INDEX REORGANIZE
這種方式不會重建索引,也不會生成新的頁,僅僅是整理葉級資料,不涉及非葉級,當遇到加鎖的頁時跳過,所以不會造成阻塞。但同時,整理效果會差於前三種。
4種索引整理技術比較:
| 特性/問題 | 解除安裝並重建索引 | DROP_EXISTING | ALTER INDEX REBUILD | ALTER INDEX REORGANIZE |
| 在聚集索引碎片整理時,重建非聚集索引 | 兩次 | 無 | 無 | 無 |
| 丟失索引 | 是 | 無 | 無 | 無 |
| 整理具有約束的索引的碎片 | 高度複雜 | 複雜性適中 | 簡單 | 簡單 |
| 同時進行多個索引的碎片整理 | 否 | 否 | 是 | 是 |
| 併發性 | 低 | 低 | 中等,取決於冰法使用者活動 | 高 |
| 中途撤銷 | 因為不使用事務,存在危險 | 程序丟失 | 程序丟失 | 程序被保留 |
| 碎片整理程度 | 高 | 高 | 高 | 中到低 |
| 應用新的填充因子 | 是 | 是 | 是 | 否 |
| 更新統計 | 是 | 是 | 是 | 否 |
四、填充因子FILLFACTOR
重建索引能夠解決碎片的問題,但是重建索引的程式碼一來需要經常操作,二來會造成資料阻塞,影響使用。在資料比較少的情況下,重建索引代價很快,但是當索引比較大的時候,例如超過100M,那麼重建索引的時間會非常長。
填充因子的作用是控制索引葉子頁面中的空閒空間數量。說白了就是預留一些空間給INSERT和UPDATE。如果知道表上有很多的INSERT查詢或者索引鍵列上有足夠的UPDATE查詢,可以預先使用填充因子來增加索引葉子頁面的空閒空間已最小化頁面分割。如果表示只讀的,可以建立一個高填充因子來減少索引頁面的數量。
預設的填充因子為0,這意味著頁面將被100%充滿。

填充因子的概念可以理解為預留一定的空間存放插入和更新新增加的資料,以避免頁拆分:

可以看出,使用填充因子會減少更新或者插入時的分頁次數,但由於需要更多的頁,則會對應的損失查詢效能.
填充因子值的選擇:
如何設定填充因子的值並沒有一個公式或者理念可以準確的設定。使用填充因子雖然可以減少更新或者插入時的分頁,但同時因為需要更多的頁,所以降低了查詢的效能和佔用更多的磁碟空間.如何設定這個值進行trade-off需要根據具體的情況來看.
具體情況要根據對於表的讀寫比例來看,我這裡給出我認為比較合適的值:
- 當讀寫比例大於100:1時,不要設定填充因子,100%填充
- 當寫的次數大於讀的次數時,設定50%-70%填充
- 當讀寫比例位於兩者之間時80%-90%填充