
jdk8的新特性總結(三):序列流與並行流
在上一篇文章中我們知道通過parallelStream方法可以獲得一個並行流,那麼什麼是並行流呢?並行流就是把內容分割成多個數據塊,每個資料塊對應一個流,然後用多個執行緒分別處理每個資料塊中的流。
java8中將並行進行了優化,我們可以很容易的對資料進行並行操作,Stream API可以宣告式的通過paralleleStream和sequential方法在並行流和順序流之間進行切換。
一、Fork/Join框架
在必要的條件下,將一個大任務進行拆分Fork,拆分成若干個小任務(拆到不可再拆時),再將若干個小任務的計算結果進行Join彙總。
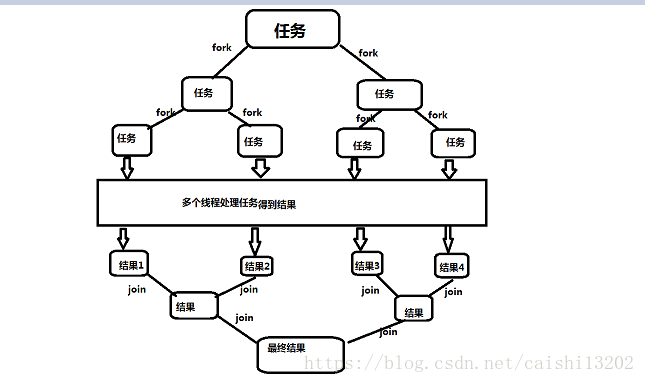
二、Fork/Join框架與傳統執行緒池的區別?
ForkJoin框架採用的是“工作竊取模式”,傳統執行緒在處理任務時,假設有一個大任務被分解成了20個小任務,並由四個執行緒A,B,C,D處理,理論上來講一個執行緒處理5個任務,每個執行緒的任務都放在一個佇列中,當B,C,D的任務都處理完了,而A因為某些原因阻塞在了第二個小任務上,那麼B,C,D都需要等待A處理完成,此時A處理完第二個任務後還有三個任務需要處理,可想而知,這樣CPU的利用率很低。而ForkJoin採取的模式是,當B,C,D都處理完了,而A還阻塞在第二個任務時,B會從A的任務佇列的末尾偷取一個任務過來自己處理,C和D也會從A的任務佇列的末尾偷一個任務,這樣就相當於B,C,D額外幫A分擔了一些任務,提高了CPU的利用率。
三、Fork/Join框架程式碼示例:
首先要編寫一個ForkJoin的計算類繼承RecursiveTask<T> 並重寫 T compute() 方法
/** * forkjoin框架使用示例: 利用ForkJoin框架求一個區間段的和 */ public class ForkJoinTest extends RecursiveTask<Long> { private static final long serialVersionUID = 123134564L; //計算的起始值 private Long start; //計算的終止值 private Long end; //做任務拆分時的臨界值 private static final Long THRESHOLD = 10000L; public ForkJoinTest(Long start, Long end) { this.start = start; this.end = end; } /** * 計算程式碼,當計算區間的長度大於臨界值時,繼續拆分,當小於臨界值時,進行計算 * * @return */ @Override protected Long compute() { Long length = this.end - this.start; if (length > THRESHOLD) { long middle = (start + end) / 2; ForkJoinTest left = new ForkJoinTest(start, middle); left.fork(); ForkJoinTest right = new ForkJoinTest(middle + 1, this.end); right.fork(); return left.join() + right.join(); } else { long sum = 0; for (long i = start; i <= end; i++) { sum += i; } return sum; } } }
然後我們寫一個測試類,來測試一下ForkJoin框架
public class TestForkJoin {
@Test
public void test1(){
long start = System.currentTimeMillis();
//1.ForkJoin框架也需要一個ForkJoin池來啟動
ForkJoinPool pool = new ForkJoinPool();
//2.建立一個ForkJoinTask,RecursiveTask也是繼承自ForkJoinTask,所以我們new自己寫的那個計算類
ForkJoinTask<Long> task = new ForkJoinTest(0L, 100000000000L);
//3.執行計算
long sum = pool.invoke(task);
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("耗費的時間為: " + (end - start)); //5463
}
/**
* 測試用for迴圈計算0到1一億的和
*/
@Test
public void test2(){
long start = System.currentTimeMillis();
long sum = 0L;
for (long i = 0L; i <= 10000000000L; i++) {
sum += i;
}
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("耗費的時間為: " + (end - start)); //7610
}
/**
* 測試用並行流計算0到1一億的和
*/
@Test
public void test3(){
long start = System.currentTimeMillis();
Long sum = LongStream.rangeClosed(0L, 10000000000L).parallel().sum();
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("耗費的時間為: " + (end - start)); //2813
}
}通過上面的比較,我們發現並行流的處理效率是比較高的,不過並行流底層也是使用的forkjoin框架,只是java8底層已經實現好了,forkjoin拆分合並任務也是需要時間的,對於計算量比較小的任務,拆分合並所花費的時間可能會大於計算時間,這時候用forkjoin拆分任務就會有點得不償失了。
總結:
1、使用parallelStream方法可以得到一個並行流,並行流底層使用的是forkjoin框架,對於一些計算量比較大的任務,使用並行流可能極大的提升效率。
2、ForkJoin框架的使用方式,
- 編寫計算類繼承RecursiveTask<T>介面並重寫T compute方法;
- 使用fork方法拆分任務,join合併計算結果;
- 使用ForkJoinPool呼叫invoke方法來執行一個任務。