
使用者畫像分析相關整理
阿新 • • 發佈:2019-01-07
前期做了一些使用者畫像的資料支援工作,都是哪裡需要往哪搬,沒有進行過系統的總結,總歸不是自己的東西,只知道要這麼做,卻不知為何要這麼做,所以在這裡進行一個歸納總結。
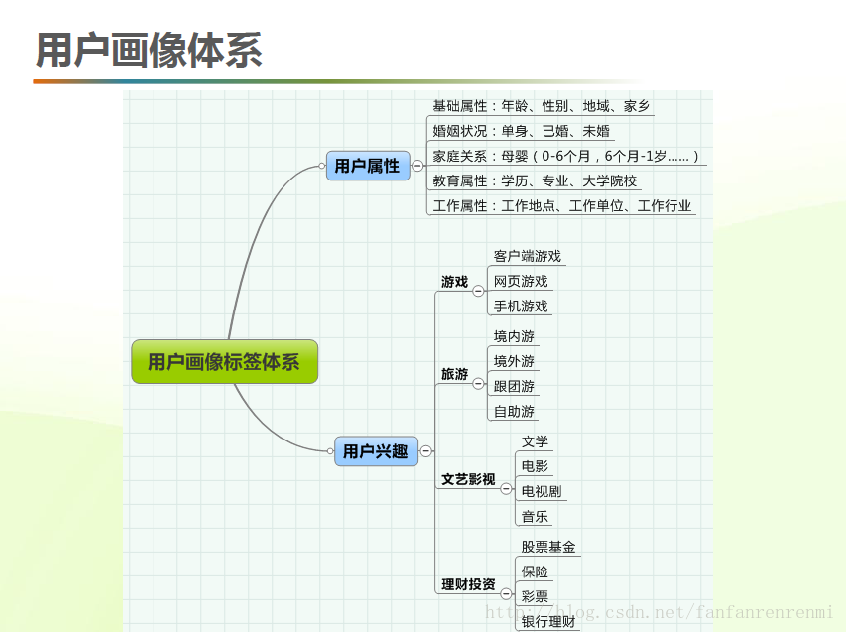
使用者畫像一般用於研究當前客戶需求以及挖掘潛在客戶,使用者畫像需要結合具體的場景進行分析,不同場景下分析也是存在差異的,自己工作中接觸的資料主要為目標客群的消費流水資料,畫像分析的內容主要是對當前分析客群基本屬性如性別、年齡段、家庭結構,行為屬性如消費水平、購物偏好時間、偏好品類等賦予客群標籤,其他涉及到客群價值發現,以及消費偏好間的關聯分析,只是使用者畫像的冰山一角,利用近期時間相對輕鬆好好整理一下,主要側重於使用者畫像探索的模型演算法的選擇。
使用者畫像說明
- 分析方向
使用者畫像一般用於刻畫使用者是什麼人,在什麼時間,做什麼事,對客戶進行使用者畫像包括兩個方面,對現存客戶與潛在客戶的刻畫:現存客戶是誰,客戶偏好,哪類客戶的價值最高等,進而對如何維繫客戶,提高客戶粘性與交易轉化率提供參考;潛在客戶是誰,客戶偏好,通過何種渠道可以找到他們,獲客成本等,瞭解如何挖掘潛在客戶。 - 資料維度
資料維度越多,聯結的場景越豐富,畫像的質量自然越高,關鍵在於對資料本身的理解,以及對客戶意圖的揣摩,一般包括如下幾個維度:
人口屬性:地域、年齡、性別、教育程度、職業、收入、生活習慣、消費習慣等;
產品行為:產品類別、活躍頻率、產品喜好、產品驅動、使用習慣、產品消費等;
這些維度是依託不同場景靈活可變的,例如做商圈客群分析中,產品指代就是包含各類品牌的商場,產品行為可以是品牌偏好,消費頻次,消費時間段、消費金額等;
網上找的一個案例圖:
- 資料來源
從使用者畫像的分析方向可以看出資料來源可分為三塊:使用者資料、產品資料、連線使用者與產品的渠道資料,以商場為例,分別對應為商場消費客戶、商場內商戶品牌,對於渠道資料在這個場景下似乎不太重要…
使用者資料包括兩塊,靜態資訊資料是指使用者的基本屬性資訊,如性別、年齡、教育水平等等,是使用者自身的自然屬性,這塊的資料根據實際資料來源的不同,若可直接獲取則只涉及資料清洗的工作,若不可直接獲取則需要針對資料建立適當的規則或模型推測基本屬性;動態資訊資料是指是指使用者的行為資料產生的標籤,如從消費行為流水中獲取的消費水平,消費偏好等;
產品資料也包括兩塊,產品自身的客觀屬性指產品價格、功能等,以及產品主觀屬性指產品風格、定位等;
渠道資料包括使用者通過什麼途徑接觸產品,資訊渠道和交易渠道;
實際資料需要結合分析場景與可觸資料來決定。

使用者畫像相關模型選擇思路
- 使用者行為標籤生成
對使用者行為進行模型構建的依據一般是基於使用者什麼時間,在什麼地點做了什麼事來進行標籤評定,一個使用者可能有多個標籤,但各個程度可能不同,使用者行為標籤的粗略公式如下
- 客戶分群
通過使用者的多維度資料分析,對客戶進行分群可以發掘不同群體的行為特徵,對不同特徵標籤的使用者進行鍼對性策略制定,例如尋找高價值客戶時,由其消費行為進行分類,針對高價值人群進行偏好針對性策略制定,則可以很好的增加該類客群的粘度及交易成功率,在知乎上檢視的一個作者寫的模型選擇的一個回答,覺得寫的很好,提供了一個客戶分群選擇演算法的一個思路:
- 基本屬性標籤
基本屬性標籤並非可以直接獲取的,尤其是當前人們對於隱私保護的關注度提升,使用者基本屬性資訊很多情況下是不可直接獲取的,想要獲取準確的使用者的年齡、性別、教育程度、家庭結構等基本都需要通過模型對其行為資料進行處理,推測使用者基本屬性。這塊方法的選擇在很多時候沒有訓練資料的情況下,會採用指定規則來進行判定,類似於使用者分群的普通分群通過使用者歷史行為特徵資料來進行推斷,也可採用聚類的方式探索。


模型及原理說明 ##–未完待續
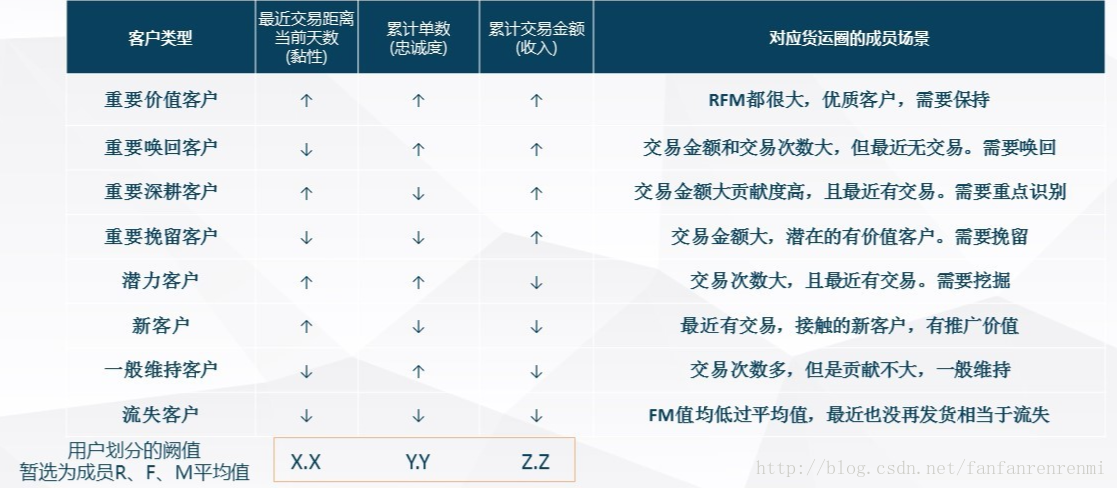
- 經典RFM模型
RFM是一個簡潔、有效的使用者分類方法,具有可解釋性強等優點。
指標說明
R(Recency):表示客戶最近一次消費時間距離當前時間間隔;
F(Frequency):表示客戶指定時間段內消費頻次;
M(Monentary):表示客戶指定時間段內消費總金額;
資料處理
資料指標梳理完之後,按照後續處理方式的不同,需要對資料進行標準化處理;
使用者分類及客群解釋
使用者分類有兩種方式,閾值劃分或者採用聚類的方式,下圖中為閾值劃分的方法,採用三個指標總體均值作為閾值,對客群進行分類:
對客群價值的劃分,有時候需要結合具體場景,對模型指標進行加權處理,進行排秩,獲取相對價值重要性。 - 基於rfm模型的客群價值分類
在1中rfm模型的基礎上,指標不變,在客戶分類中,可以採用多種聚類演算法實現客戶分類,如k-means、svm、自組織對映模型(som)等,這裡的方法應該是多樣的,這裡主要想把som搞懂。 - 標籤權重定義
- 演算法實現學習
xgboost
參考文章的連結
最後吐槽一下csdn,太不靠譜了,是因為改版嗎,我這篇內容已經梳理了兩個周了,竟然回到了最開始的樣子了,把自己已經寫過70%的內容重寫一遍有點難過,就(只)當(能)是幫助加深自己理解吧