
Lucene全文檢索入門使用
一、 什麼是全文檢索
全文檢索是計算機程式通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置。當用戶查詢時根據建立的索引查詢,類似於通過字典的檢索字表查字的過程
全文檢索(Full-Text Retrieval)以文字作為檢索物件,找出含有指定詞彙的文字。全面、準確和快速是衡量全文檢索系統的關鍵指標。
關於全文檢索,我們要知道:
1、只處理文字。
2,不處理語義。
3,搜尋時英文不區分大小寫。
4,結果列表有相關度排序。
二、 全文檢索與資料庫檢索的區別
全文檢索不同於資料庫的SQL查詢。(他們所解決的問題不一樣,解決的方案也不一樣,所以不應進行對比)。在資料庫中的搜尋就是使用SQL,如:SELECT * FROM t WHERE content like ‘%ant%’。這樣會有如下問題:
1、匹配效果:如搜尋ant會搜尋出planting。這樣就會搜出很多無關的資訊。
2、相關度排序:查出的結果沒有相關度排序,不知道我想要的結果在哪一頁。我們在使用百度搜索時,一般不需要翻頁,為什麼?因為百度做了相關度排序:為每一條結果打一個分數,這條結果越符合搜尋條件,得分就越高,叫做相關度得分,結果列表會按照這個分數由高到低排列,所以第1頁的結果就是我們最想要的結果。
3、全文檢索的速度大大快於SQL的like搜尋的速度。這是因為查詢方式不同造成的,以查字典舉例:資料庫的like就是一頁一頁的翻,一行一行的找,而全文檢索是先查目錄,得到結果所在的頁碼,再直接翻到這一頁。
三、 全文檢索的使用場景
我們使用Lucene,主要是做站內搜尋,即對一個系統內的資源進行搜尋。如BBS論壇、BLOG(部落格)中的文章搜尋,網上商店中的商品搜尋等。使用Lucene的專案有Eclipse,智聯招聘,天貓,京東等。一般不做網際網路中資源的搜尋,因為不易獲取與管理海量資源(專業搜尋方向的公司除外)
入門使用
Java環境下
匯入Lucene核心jar包
<!--lucene-core --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>4.4.0</version> </dependency> <!--lucene-analyzers-common分詞器相關 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>4.4.0</version> </dependency> <!-- ikanalyzer分詞器 --> <dependency> <groupId>com.janeluo</groupId> <artifactId>ikanalyzer</artifactId> <version>2012_u6</version> </dependency> <!-- lucene-queryparser使用MultiFieldQueryParser必須匯入 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>4.4.0</version> </dependency> <!-- lucene-highlighter 高亮依賴--> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-highlighter</artifactId> <version>4.4.0</version> </dependency>
建立索引庫
public class TestCreateIndex {
public static void main(String[] args) throws IOException {
//構建索引庫
Directory dir = FSDirectory.open(new File("F:/index"));
//索引寫入相關配置 args:version,分詞器
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_44);
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_44,analyzer);
//索引寫入器
IndexWriter indexWriter = new IndexWriter(dir,config);
//為文字建立document
Document document = new Document();
//StringField---DoubleField....
document.add(new StringField("id","1",Field.Store.YES));
document.add(new StringField("title","帶秀TV",Field.Store.YES)); //YES,資料在元資料區也存在
document.add(new StringField("author","張肖",Field.Store.YES));
document.add(new TextField("content","今晚,是我最開心,也最難過的晚上。開心是因為小梅,難過也是!",Field.Store.YES));
document.add(new StringField("date","2019-1-2",Field.Store.YES));
indexWriter.addDocument(document);
indexWriter.commit();
indexWriter.close();
}
}此時,就在物件目錄下建立了這一篇文章的索引庫。
建立搜尋索引
public class TestCreateSearch {
public static void main(String[] args) throws IOException {
//索引讀入流
Directory directory = FSDirectory.open(new File("D:/index"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(reader);
//引數1:搜尋條件 Query抽象類,引數2:查詢的條數
Query query = new TermQuery(new Term("author", "張")); //詞查詢,BooleanQuery、 Term引數:field指定索引屬性,keyword
TopDocs topDocs = indexSearcher.search(query, 100); //相關度排序
/* TopDocs屬性
public int totalHits;
public ScoreDoc[] scoreDocs;
private float maxScore;
*/
ScoreDoc[] scoreDocs = topDocs.scoreDocs; //scoreDocs屬性返回陣列,相關度排序doc陣列
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc; //其中一個拿到的doc的索引編號,該編號由文件進入索引庫時生成
Document document = indexSearcher.doc(doc);
System.out.println(scoreDoc.score);
System.out.println(document.get("id"));
System.out.println(document.get("title"));
System.out.println(document.get("content"));
System.out.println(document.get("date"));
}
}
}注意:8中基本型別+String不分詞,text型別分詞,當使用StandardAnalyzer分詞器,預設每一個詞分詞,如,你,我,這,....全部被拆分稱為單個詞建立索引,所以測試搜尋時只能以單個字查詢,後面會解決這個問題。
四、Lucene的建立索引以及搜尋的原理
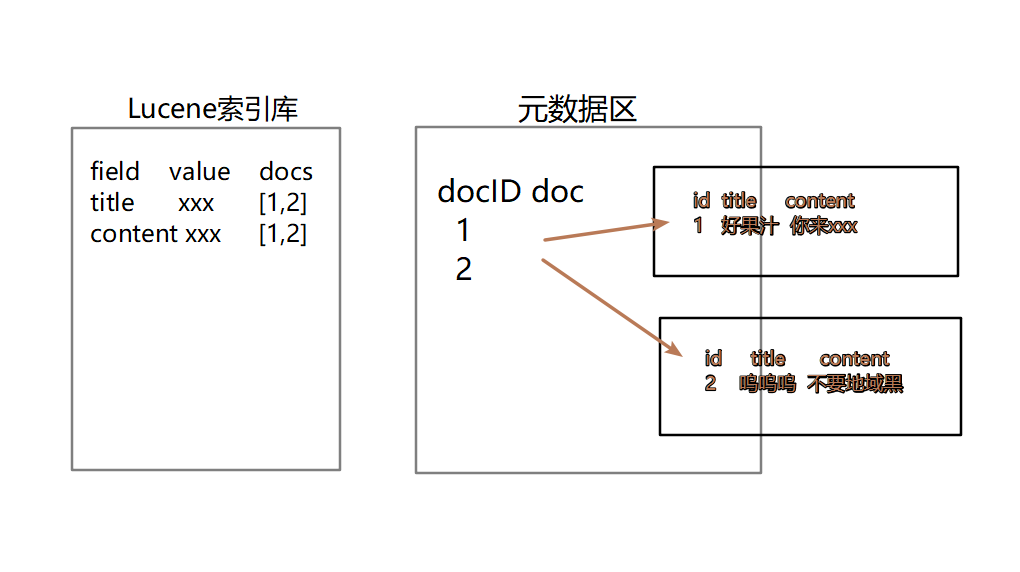
五、 Lucene的增刪改查
封裝工具類
public class LuceneUtil {
private static Directory directory;
private static final Version version = Version.LUCENE_44;
private static Analyzer analyzer;
private static IndexWriterConfig indexWriterConfig;
static {
try {
//version = Version.LUCENE_44;
analyzer = new IKAnalyzer();
directory = FSDirectory.open(new File("F:/index"));
indexWriterConfig = new IndexWriterConfig(version, analyzer);
} catch (IOException e) {
e.printStackTrace();
}
}
public static IndexWriter getIndexWriter() {
IndexWriter indexWriter = null;
try {
indexWriter = new IndexWriter(directory, indexWriterConfig);
} catch (IOException e) {
e.printStackTrace();
}
return indexWriter;
}
public static IndexSearcher getIndexSearcher() {
IndexSearcher indexSearcher = null;
try {
IndexReader reader = DirectoryReader.open(directory);
indexSearcher = new IndexSearcher(reader);
} catch (IOException e) {
e.printStackTrace();
}
return indexSearcher;
}
public static void commit(IndexWriter indexWriter) {
try {
indexWriter.commit();
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void rollback(IndexWriter indexWriter) {
try {
indexWriter.rollback();
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}增刪改查測試
public class TestIndexCreateAndSearch {
@Test
public void testCreateIndex() {
IndexWriter indexWriter = LuceneUtil.getIndexWriter();
try {
for (int i = 0; i < 10; i++) {
Document document = new Document();
document.add(new IntField("id",i, Field.Store.YES));
document.add(new StringField("title", "帶秀TV四大門派圍攻光明頂", Field.Store.YES));
document.add(new TextField("content", "今晚,是我最開心,也最難過的晚上。開心是因為小梅,難過也是", Field.Store.YES));
document.add(new StringField("date", "2019-1-2", Field.Store.YES));
indexWriter.addDocument(document);
}
} catch (IOException e) {
e.printStackTrace();
LuceneUtil.rollback(indexWriter);
}
LuceneUtil.commit(indexWriter);
}
@Test
public void testSearchIndex() {
IndexSearcher indexSearcher = LuceneUtil.getIndexSearcher();
try {
TopDocs topDocs = indexSearcher.search(new TermQuery(new Term("content", "我")), 100);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (int i = 0; i < scoreDocs.length; i++) {
ScoreDoc scoreDoc = scoreDocs[i];
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
System.out.println("this is 分數======>" + scoreDoc.score);
System.out.println("this is 編號======>" + document.get("id"));
System.out.println("this is 標題======>" + document.get("title"));
System.out.println("this is 內容======>" + document.get("content"));
System.out.println("this is 日期======>" + document.get("date"));
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~");
}
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testDelete() {
IndexWriter indexWriter = LuceneUtil.getIndexWriter();
//indexWriter.deleteAll(); //刪除所有
try {
indexWriter.deleteDocuments(new Term("id", "0"));
LuceneUtil.commit(indexWriter);
} catch (IOException e) {
e.printStackTrace();
LuceneUtil.rollback(indexWriter);
}
}
//修改 是先刪除再新增
@Test
public void testUpdate() {
IndexWriter indexWriter = LuceneUtil.getIndexWriter();
Document document = new Document();
document.add(new StringField("id", String.valueOf(0), Field.Store.YES));
document.add(new StringField("title", "瘸子", Field.Store.YES));
document.add(new TextField("content", "與隊長的博弈第二季", Field.Store.YES));
document.add(new StringField("date", "2019-1-2", Field.Store.YES));
try {
indexWriter.updateDocument(new Term("id", "1"), document);
LuceneUtil.commit(indexWriter);
} catch (IOException e) {
e.printStackTrace();
LuceneUtil.rollback(indexWriter);
}
}
}六、Lucene的分詞器
a) 分詞器作用
Analyzer分詞器的作用是把一段文字中的詞按照一定的規則取出所包含的所有詞,對應的類為 “Analyzer”,這是一個抽象類,切分詞的具體規則由子類實現,因此不同的語言,需要使用不同的分詞器
b) 切分詞原理
我是中國人---切分後:中國,中國人
切分關鍵詞
去除停用詞
對於英文要把所用字母轉化為大/小寫搜尋,不區分大小寫
有的分詞器還對英文進行了形態還原,就是去除單詞詞尾的形態變化,將其還原為詞的原型,這樣可以搜尋出更有意義的結果 如: 搜尋student時,出現students,也是很有意義的.
注意:
**如果是同一種語言資料,在建立索引,以及搜尋時,一定要使用同一個分詞器,否則可能會搜尋不到結果**測試分詞器
分詞器有很多,StandardAnalyzer,ChineseAnalyzer都不適用,直接測試IKAnalyzer分詞器,引入停詞詞典與擴充套件詞典;
停詞詞典:那些詞不建立索引,在詞典內寫出
擴充套件詞典:那些特殊的話需要保留
配置檔案引入:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 擴充套件配置</comment>
<!--使用者可以在這裡配置自己的擴充套件字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--使用者可以在這裡配置自己的擴充套件停止詞字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>測試程式
public class TestAnalyzer {
String text = "今晚,是我最開心,也最難過的晚上。開心是因為小梅,難過也是";
@Test
public void testIKanalyzer() { //IK可以自定義停詞,關鍵詞
test(new IKAnalyzer(), text);
//ChineseAnalyzer,StandardAnalyzer SmartCn 不再使用
}
public void test(Analyzer analyzer, String text) {
System.out.println("當前分詞器:--->" + analyzer.getClass().getName());
try {
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(text));
tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while (tokenStream.incrementToken()) {
CharTermAttribute attribute = tokenStream.getAttribute(CharTermAttribute.class);
System.out.println(attribute.toString());
}
tokenStream.end();
} catch (IOException e) {
e.printStackTrace();
}
}
}結果:
當前分詞器:--->org.wltea.analyzer.lucene.IKAnalyzer
載入擴充套件詞典:ext.dic
載入擴充套件停止詞典:stopword.dic
今晚
是
我
最
開心
也
最難
難過
的
晚上
開心
是因為
因為
小
梅
難過
也是
七、Lucene的全文檢索的得分/熱度
相關度得分是在查詢時根據查詢條件實進計算出來的,如果索引庫據不變,查詢條件不變,查出的文件得分也不變
這個相關度的得分我們是可以手動的干預的:
TextField field = new TextField("content","xxxxxx",Store.YES);
field.setBootst(10f); //引數型別float八、索引庫優化
一、Lucene4.0後自動優化
二、排除停用詞,被分詞器過濾掉,建立索引時,就不會建立停用詞,減少索引的大小
三、索引分割槽存放
四、索引放在內容中
psvm{
FSDirectory dir = FSDirectory.open(new File("D:/index"));
IOContext context = new IOContext();
Directory dir2 = new RAMDirectory(dir,context);
}九、查詢擴充套件
使用不同的查詢器得到的結果就不同,常用的查詢器有TermQuery,MultiFieldQueryParser,MatchAllDocsQuery,NumericRangeQuery....
測試程式對查詢結果分頁,查詢關鍵詞高亮顯示
public class TestQuery {
@Test
public void termQuery(){
testQuery(new TermQuery(new Term("content","要飯")));
}
//多屬性查詢 使用MultiFieldQueryParser:1.分詞器一致 2.匯入jar包
@Test
public void testMultiParser() throws ParseException {
String[] field = {"title","brief"};
IKAnalyzer analyzer = new IKAnalyzer();
MultiFieldQueryParser multiFieldQueryParser = new MultiFieldQueryParser(Version.LUCENE_44,field,analyzer);
testQuery(multiFieldQueryParser.parse("今"));
}
//查詢所有文件 --使用場景少
@Test
public void testMacthAll(){
MatchAllDocsQuery matchAllDocsQuery = new MatchAllDocsQuery();
testQuery(matchAllDocsQuery);
}
// 區間查詢
@Test
public void testNumericRangeQuery(){
NumericRangeQuery<Integer> query = NumericRangeQuery.newIntRange("id", 5, 7, true, true);
testQuery(query);
}
//匹配查詢
@Test
public void testWildQuery(){
WildcardQuery query = new WildcardQuery(new Term("content", "北?"));
testQuery(query);
}
//模糊查詢
@Test
public void testFuzzQuery(){
FuzzyQuery fuzzyQuery = new FuzzyQuery(new Term("content", "白京"));
testQuery(fuzzyQuery);
}
//布林查詢
@Test
public void testBooleanQuery(){
BooleanQuery booleanClauses = new BooleanQuery();
NumericRangeQuery<Integer> query = NumericRangeQuery.newIntRange("id", 1, 7, true, true);
NumericRangeQuery<Integer> query2 = NumericRangeQuery.newIntRange("id", 3, 5, true, true);
booleanClauses.add(query,BooleanClause.Occur.MUST);
booleanClauses.add(query2,BooleanClause.Occur.SHOULD);
testQuery(booleanClauses);
}
public void testQuery(Query query){
//查詢結果分頁
int pageNum = 1;
int pageSize = 3;
Formatter formatter = new SimpleHTMLFormatter("<font color='red'>","</font>");
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter, scorer);
//索引讀入流
IndexSearcher indexSearcher = LuceneUtil.getIndexSearcher();
try {
TopDocs topDocs = indexSearcher.search(query, pageNum*pageSize); //相關度排序
ScoreDoc[] scoreDocs = topDocs.scoreDocs; //scoreDocs屬性返回陣列,相關度排序doc陣列
for (int i = (pageNum-1)*pageSize; i < scoreDocs.length; i++) {
ScoreDoc scoreDoc = scoreDocs[i];
int doc = scoreDoc.doc; //其中一個拿到的doc的索引編號,該編號由文件進入索引庫時生成
Document document = indexSearcher.doc(doc);
System.out.println("this is 分數======>" + scoreDoc.score);
System.out.println("this is 編號======>" + document.get("id"));
System.out.println("this is 標題======>" + document.get("title"));
System.out.println("this is 內容======>" + document.get("brief"));
System.out.println("this is 日期======>" + document.get("date"));
System.out.println("~~~~~~~~~~~~~~~~after highlight~~~~~~~~~~~~~~~~~~~~~~~~~~");
try {//高亮區域
//當前查詢的關鍵詞 id屬性中不存在導致空
String bestFragment = highlighter.getBestFragment(new IKAnalyzer(), "id", document.get("id"));
if(bestFragment == null){
System.out.println("this is 編號======>" + document.get("id"));
}else{
System.out.println("this is 編號======>" + bestFragment);
}
System.out.println("this is 內容======>" + highlighter.getBestFragment(new IKAnalyzer(),"content",document.get("content")));
} catch (InvalidTokenOffsetsException e) {
e.printStackTrace();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}高亮原理:對查詢的關鍵詞使用font標籤包圍
Formatter formatter = new SimpleHTMLFormatter("<font color='red'>","</font>");
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter, scorer);