
c++漢字字元處理
問題:實現Apriori演算法時的資料集為中文,所以需要用到漢字字元處理。現蒐集整合如下。
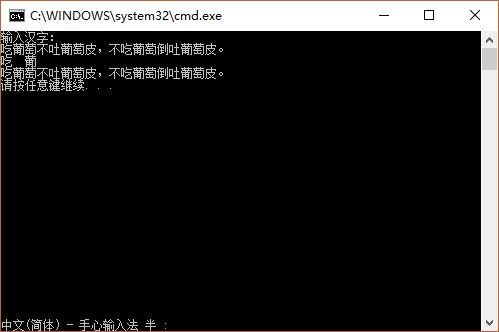
#include <stdio.h>
void main(void){
char str[100];
printf("輸入漢字:\n");
scanf("%s",str);
printf("%c%c %c%c\n", str[0],str[1],str[2],str[3]);
printf("%s\n",str);
}測試結果:
一 引入問題
程式碼 wchar_t a3=L”中國”,編譯時出錯,出錯資訊為:陣列越界。但wchar_t 是一個寬位元組型別,陣列a的大小應為6個位元組,而兩個漢字的的unicode碼佔4個位元組,再加上一個結束符,最多6個位元組,所以應該不會越界。難道是編譯器出問題了?
二 解決引入問題所需的知識
主要需兩方面的知識
1. 字元尤其是漢字的編碼,以及語言和工具的支援情況
2. vc/c++中MutiByte Charater Set 和 Wide Character Set有關記憶體分配的情況.
三 漢字的編碼方式及在vc/c++中的處理
1.漢字編碼方式的介紹
對英文字元的處理,7位ASCII碼字符集中的字元即可滿足使用需求,且英文字元在計算機上的輸入及輸出也非常簡單,因此,英文字元的輸入、儲存、內部處理和輸出都可以只用同一個編碼(如ASCII碼)。
而漢字是一種象形文字,字數極多(現代漢字中僅常用字就有六、七千個,總字數高達5萬個以上),且字形複雜,每一個漢字都有”音、形、義”三要素,同音字、異體字也很多,這些都給漢字的的計算機處理帶來了很大的困難。要在計算機中處理漢字,必須解決以下幾個問題:首先是漢字的輸入,即如何把結構複雜的方塊漢字輸入到計算機中去,這是漢字處理的關鍵;其次,漢字在計算機內如何表示和儲存?如何與西文相容?最後,如何將漢字的處理結果從計算機內輸出?
為此,必須將漢字程式碼化,即對漢字進行編碼。對應於上述漢字處理過程中的輸入、內部處理及輸出這三個主要環節,流程如下:
(1) 輸入碼
作用是,利用它和現有的標準西文鍵盤結合來輸入漢字。輸入碼也稱為外碼。主要歸為四類:
數字編碼
數字編碼是用等長的數字串為漢字逐一編號,以這個編號作為漢字的輸入碼。例如,區位碼、電報碼等都屬於數字編碼。拼音碼
拼音碼是以漢字的讀音為基礎的輸入辦法。字形碼
字形碼是以漢字的字形結構為基礎的輸入編碼。例如,五筆字型碼(王碼)。音形碼
音形碼是兼顧漢字的讀音和字形的輸入編碼。
(2) 交換碼
用於漢字外碼和內部碼的交換。交換碼的國家標準代號為GB2312-8090。
(3) 內部碼
內部碼是漢字在計算機內的基本表示形式,是計算機對漢字進行識別、儲存、處理和傳輸所用的編碼。內部碼也是雙位元組編碼,將國標碼兩個位元組的最高位都置為”1”,即轉換成漢字的內部碼。
(4) 字形碼
字形碼是表示漢字字形資訊(漢字的結構、形狀、筆劃等)的編碼,用來實現計算機對漢字的輸出(顯示、列印)。
2.vc中漢字的編碼方式
vc/c++正是採用了GB2312內部碼作為漢字的編碼方式,因此vc/c++中的各種輸入輸出方法,如cin/wcin,cout/wcout,scanf/wsanf,printf/wprintf…都是基於GB2312的,如果漢字的內碼不是這種編碼方式,那麼利用上述各種方法就不會正確的解析漢字。
| ASCII值 | 控制字元 | ASCII值 | 控制字元 | ASCII值 | 控制字元 | ASCII值 | 控制字元 |
|---|---|---|---|---|---|---|---|
| 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | “ | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | , | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | |
| 9 | HT | 41 | ) | 73 | I | 105 | |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | / | 124 | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ` |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
| NUL空 | VT 垂直製表 | SYN 空轉同步 |
|---|---|---|
| STX 正文開始 | CR 回車 | CAN 作廢 |
| ETX 正文結束 | SO 移位輸出 | EM 紙盡 |
| EOY 傳輸結束 | SI 移位輸入 | SUB 換置 |
| ENQ 詢問字元 | DLE 空格 | ESC 換碼 |
| ACK 承認 | DC1 裝置控制1 | FS 文字分隔符 |
| BEL 報警 | DC2 裝置控制2 | GS 組分隔符 |
| BS 退一格 | DC3 裝置控制3 | RS 記錄分隔符 |
| HT 橫向列表 | DC4 裝置控制4 | US 單元分隔符 |
| LF 換行 | NAK 否定 | DEL 刪除 |
仔細觀察ASCII字元表,從第161個字元開始,後面的字元並不經常為使用者所使用,負值也未使用。GB2312編碼方式充分利用這一特性,將161-255(-95~-1)之間的數值空間作為漢字的標識碼。既然255-161 = 94不能滿足漢字容量的要求,就將每兩個字元並在一塊(即一個漢字佔兩個位元組),顯然,94* 94 =8836基本上已經滿足了常用漢字個數的要求。計算機處理字元時,當連續處理到兩個大與160(或-95~-1)的位元組時,就認為這兩個位元組存放了一個漢字字元。可以用下面的Demo程式來模擬vc/c++中輸出漢字字元的過程。
unsigned char input[50];
cin>>input;
int flag=0;
for(int i =0 ;i < 50 ;i++)
{
if(input[i] > 0xa0 && input[i] != 0)
{
if(flag == 1)
{
cout<<"chinese character"<
flag = 0;
}
else
{
flag++;//一位元組,前四位識別,後四位確定並輸出,見上一段if程式
}
}
else if(input[i] == 0)
{
break;
}
else
{
cout<<"english character"<
flag=0;
}
}輸入:Hello中國 (“中國”對應的GB2312內碼為:214 208,185 250)
輸出:english character
english character
english character
english character
english character
chinese character
chinese character
vc/c++中的英文字元仍然採用ASCII編碼方式。可以設想,其他國家程式設計師利用vc/c++編寫程式輸入本國字元時,vc/c++則會採用該國的字元編碼方式來處理這些字元。
問題又產生了,韓國的vc/c++程式在中國的vc/c++上執行時,如果沒有相應的內碼庫,則對韓語字元的顯示有可能出現亂碼。我個人猜測,vc安裝程式中應該帶有不同國家的內碼庫,這樣一來肯定會佔用很大的空間。如果所有的國家使用統一的編碼方式,且所有的程式設計語言和開發工具都支援這種編碼方式該多好!而現實中,確實已經有這種編碼方式了,且許多新的語言也都支援這種編碼方式,如Java、C#等,它就是下面的Unicode編碼
3.新的內碼標準—Unicode
Unicode(統一碼、萬國碼、單一碼)是一種在計算機上使用的字元編碼。它為每種語言中的每個字元設定了統一併且唯一的二進位制編碼,以滿足跨語言、跨平臺進行文字轉換、處理的要求。
在Unicode 5.0.0版本中,已定義的碼位只有238605個,分佈在平面0、平面1、平面2、平面14、平面15、平面16。其中平面15和平面16上只是定義了兩個各佔65534個碼位的專用區(Private Use Area),分別是0xF0000-0xFFFFD和0x100000-0x10FFFD。所謂專用區,就是保留給大家放自定義字元的區域,可以簡寫為PUA。
平面0也有一個專用區:0xE000-0xF8FF,有6400個碼位。平面0的0xD800-0xDFFF,共2048個碼位,是一個被稱作代理區(Surrogate)的特殊區域。代理區的目的用兩個UTF-16字元表示BMP以外的字元。在介紹UTF-16編碼時會介紹。
如前所述在Unicode 5.0.0版本中,238605-65534*2-6400-2048=99089。餘下的99089個已定義碼位分佈在平面0、平面1、平面2和平面14上,它們對應著Unicode定義的99089個字元,其中包括71226個漢字。平面0、平面1、平面2和平面14上分別定義了52080、3419、43253和337個字元。平面2的43253個字元都是漢字。平面0上定義了27973個漢字。
在Unicode中:漢字“字”對應的數字是23383(十進位制),十六進位制表示為5B57。在Unicode中,我們有很多方式將數字23383表示成程式中的資料,包括:UTF-8、UTF-16、UTF-32。UTF是“Unicode Transformation Format”的縮寫,可以翻譯成Unicode字符集轉換格式,即怎樣將Unicode定義的數字轉換成程式資料。
例如,“漢字”對應的數字是0x6c49和0x5b57,而編碼的程式資料是:
char data_utf8[]={0xE6,0xB1,0x89,0xE5,0xAD,0x97};//UTF-8編碼
char16_t data_utf16[]={0x6C49,0x5B57}; //UTF-16編碼
char32_t data_utf32[]={0x00006C49,0x00005B57};//UTF-32編碼這裡用char、char16_t、char32_t分別表示無符號8位整數,無符號16位整數和無符號32位整數。UTF-8、UTF-16、UTF-32分別以char、char16_t、char32_t作為編碼單位。(注: char16_t 和 char32_t 是 C++ 11 標準新增的關鍵字。如果你的編譯器不支援 C++ 11 標準,請改用 unsigned short 和 unsigned long。)“漢字”的UTF-8編碼需要6個位元組。“漢字”的UTF-16編碼需要兩個char16_t,大小是4個位元組。“漢字”的UTF-32編碼需要兩個char32_t,大小是8個位元組。
Unicode 編碼系統可分為編碼方式和實現方式兩個層次。
編碼方式(此文作於08年)
Unicode 的編碼方式與 ISO 10646 的通用字符集(Universal Character Set,UCS)概念相對應,目前的用於實用的 Unicode 版本對應於 UCS-2,使用16位的編碼空間。也就是每個字元佔用2個位元組。這樣理論上一共最多可以表示 216 個字元。基本滿足各種語言的使用。實際上目前版本的 Unicode 尚未填充滿這16位編碼,保留了大量空間作為特殊使用或將來擴充套件。實現方式
Unicode 的實現方式不同於編碼方式。
目前的Unicode字元分為17組編排,0x0000 至 0x10FFFF,每組稱為平面(Plane),而每平面擁有65536個碼位,共1114112個。
一個字元的 Unicode 編碼是確定的。但是在實際傳輸過程中,由於不同系統平臺的設計不一定一致,以及出於節省空間的目的,對 Unicode 編碼的實現方式有所不同。
Unicode 的實現方式稱為Unicode轉換格式(Unicode Translation Format,簡稱為 UTF)。如,UTF-8 編碼,這是一種變長編碼,它將基本7位ASCII字元仍用7位編碼表示,佔用一個位元組(首位補0)。而遇到與其他 Unicode 字元混合的情況,將按一定演算法轉換,每個字元使用1-3個位元組編碼,並利用首位為0或1進行識別。
Java與C#語言都是採用Unicode編碼方式,在這兩種語言中定義一個字元,在記憶體中存放的就是這個字元的兩位元組Unicode碼。如下所示:
char a=’我’; => 記憶體中存放的Unicode碼為:25105
4.內碼的相互轉換
(1) vc中的實現方法
利用Windows系統提供的API:::MultiByteToWideChar和::WideCharToMultiByte
::MultiByteToWideChar:實現當前碼到Unicode碼的轉換;
::WideCharToMultiByte:實現Unicode碼到當前碼的轉換;
(2) Java中的實現方法
String vcString=new String(javaString.getBytes(“UTF-8”),”gb2312”);
java的編碼應該是UTF-8
(3) C#中的實現方法
??
四 vc中的MutiByte Charater Set 和 Wide Character Set
1.MultiByte Charater Set方式
這種方式以按位元組為單位存放字元,即如果一個字元碼為兩位元組,則在記憶體中佔兩位元組,字元碼為一位元組,就佔一位元組。例如,字串“中國abc”的編碼為:中(0xd6、0xd0)、國(0xb9、0xfa)、a(0x61)、b(0x62)、c(0x63)、\0(0x00),就存為如下方式:
對應的型別,方法有:char、scanf、printf、cin、cout …
2.Wide Character Set
這種方式是以兩位元組為單位存放字元,即如果一個字元碼為兩位元組,則在記憶體中佔四位元組,字元碼為一位元組,就佔兩位元組。例如,字串“中國abc”就存為如下方式:
對應的型別,方法有:wchar_t、wscanf、wprintf、wcin、wcout …
造成上面儲存方式的根本原因在於,wchar_t型別其實是一個unsigned short 型別。如,儲存上面字串的陣列的定義為:wchar_t buffer[8] 等價於unsigned short buffer[8].而所有以字母w開頭的方法也都是以unsigned short型別,即兩位元組為單位來處理字元,因此,儲存在wchar_t型別陣列中的字串無法用cout顯示,只能用wcout方法來顯示。
由於Unicode碼也是採用兩個位元組,因此Wide Character Set方式能夠很好的支援Unicode碼的儲存,但是在vc的環境下要將一個Unicode碼存入兩位元組而不是四位元組記憶體中,必須通過上面的API函式::MultiByteToWideChar。首先,將當前的編碼轉換為Unicode碼,然後,將每個字元的Unicode碼放入每一個wchar_t型別的變數中。以下是一個例項程式碼:
char input[50];
cin>>input;
int size;
size=::MultiByteToWideChar(CP_ACP,0,input,strlen(input)+1,NULL,0);
if(size==0)
return -1;
wchar_t *widebuff=new wchar_t[size];
::MultiByteToWideChar(CP_ACP,0,input,strlen(input)+1,widebuff,size);輸入:中國abc
Debug斷點除錯:
size==6
陣列widebuff[0-size]佔12位元組,存放了6個字元的Unicode碼,碼值為:
中(0x4e2d) 國(0x56fd) a(0x0061) b(0x0062) c(0x0063) d(0x0000)
這時,陣列的大小size等於輸入的字元個數加上一個結束符,符合我們的想象。
五 引入問題的錯誤分析
沒有理解編譯器中的編碼方式
雖然vc/c++中漢字的編碼佔兩個位元組,但並不是Unicode碼,是GB2312碼。沒有理解MutiByte Charater Set 和 Wide Character Set的儲存原則;
在vc/c++中,“中國”按char5來對待,而wchar_t a3實際上是三個unsigned short型別的變數,因此賦值時會越界。
2010年上傳的文章,但是真的深入淺出,推薦。