
分散式爬蟲原理之分散式爬蟲原理
我們在前面已經實現了Scrapy微博爬蟲,雖然爬蟲是非同步加多執行緒的,但是我們只能在一臺主機上執行,所以爬取效率還是有限的,分散式爬蟲則是將多臺主機組合起來,共同完成一個爬取任務,這將大大提高爬取的效率。
一、分散式爬蟲架構
在瞭解分散式爬蟲架構之前,首先回顧一下Scrapy的架構,如下圖所示。
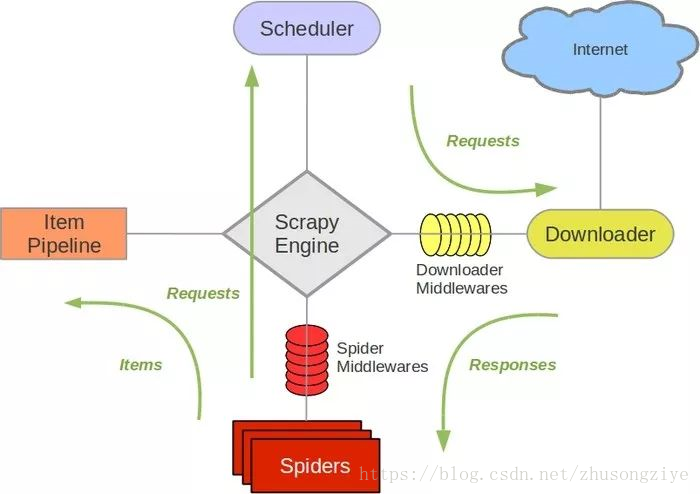
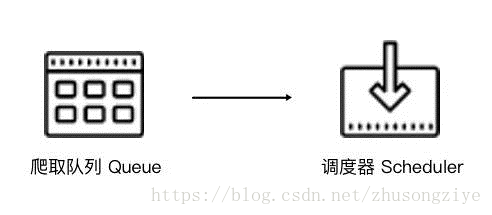
Scrapy單機爬蟲中有一個本地爬取佇列Queue,這個佇列是利用deque模組實現的。如果新的Request生成就會放到佇列裡面,隨後Request被Scheduler排程。之後,Request交給Downloader執行爬取,簡單的排程架構如下圖所示。
如果兩個Scheduler同時從佇列裡面取Request,每個Scheduler都有其對應的Downloader,那麼在頻寬足夠、正常爬取且不考慮佇列存取壓力的情況下,爬取效率會有什麼變化?沒錯,爬取效率會翻倍。
這樣,Scheduler可以擴充套件多個,Downloader也可以擴充套件多個。而爬取佇列Queue必須始終為一個,也就是所謂的共享爬取佇列。這樣才能保證Scheduer從佇列裡排程某個Request之後,其他Scheduler不會重複排程此Request,就可以做到多個Schduler同步爬取。這就是分散式爬蟲的基本雛形,簡單排程架構如下圖所示。
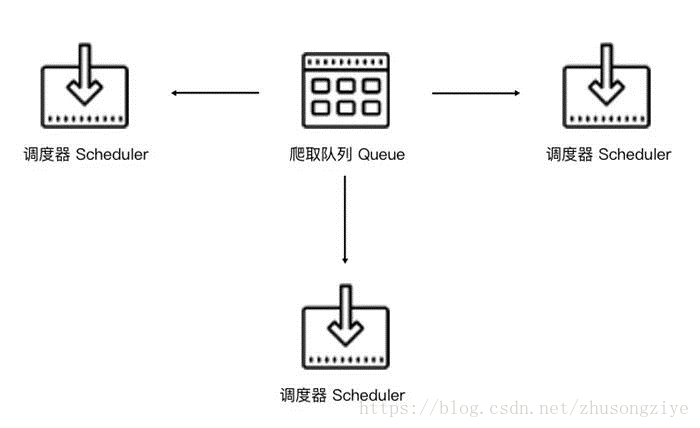
我們需要做的就是在多臺主機上同時執行爬蟲任務協同爬取,而協同爬取的前提就是共享爬取佇列。這樣各臺主機就不需要各自維護爬取佇列,而是從共享爬取佇列存取Request。但是各臺主機還是有各自的Scheduler和Downloader,所以排程和下載功能分別完成。如果不考慮佇列存取效能消耗,爬取效率還是會成倍提高。
二、維護爬取佇列
那麼這個佇列用什麼來維護?首先需要考慮的就是效能問題。我們自然想到的是基於記憶體儲存的Redis,它支援多種資料結構,例如列表(List)、集合(Set)、有序集合(Sorted Set)等,存取的操作也非常簡單。
Redis支援的這幾種資料結構儲存各有優點。
列表有
lpush()、lpop()、rpush()、rpop()方法,我們可以用它來實現先進先出式爬取佇列,也可以實現先進後出棧式爬取佇列。集合的元素是無序的且不重複的,這樣我們可以非常方便地實現隨機排序且不重複的爬取佇列。
有序集合帶有分數表示,而Scrapy的Request也有優先順序的控制,我們可以用它來實現帶優先順序排程的佇列。
我們需要根據具體爬蟲的需求來靈活選擇不同的佇列。
三、如何去重
Scrapy有自動去重,它的去重使用了Python中的集合。這個集合記錄了Scrapy中每個Request的指紋,這個指紋實際上就是Request的雜湊值。我們可以看看Scrapy的原始碼,如下所示:
import hashlib
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
request_fingerprint()就是計算Request指紋的方法,其方法內部使用的是hashlib的sha1()方法。計算的欄位包括Request的Method、URL、Body、Headers這幾部分內容,這裡只要有一點不同,那麼計算的結果就不同。計算得到的結果是加密後的字串,也就是指紋。每個Request都有獨有的指紋,指紋就是一個字串,判定字串是否重複比判定Request物件是否重複容易得多,所以指紋可以作為判定Request是否重複的依據。
那麼我們如何判定重複呢?Scrapy是這樣實現的,如下所示:
def __init__(self):
self.fingerprints = set()
def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
在去重的類RFPDupeFilter中,有一個request_seen()方法,這個方法有一個引數request,它的作用就是檢測該Request物件是否重複。這個方法呼叫request_fingerprint()獲取該Request的指紋,檢測這個指紋是否存在於fingerprints變數中,而fingerprints是一個集合,集合的元素都是不重複的。如果指紋存在,那麼就返回True,說明該Request是重複的,否則這個指紋加入到集合中。如果下次還有相同的Request傳遞過來,指紋也是相同的,那麼這時指紋就已經存在於集合中,Request物件就會直接判定為重複。這樣去重的目的就實現了。
Scrapy的去重過程就是,利用集合元素的不重複特性來實現Request的去重。
對於分散式爬蟲來說,我們肯定不能再用每個爬蟲各自的集合來去重了。因為這樣還是每個主機單獨維護自己的集合,不能做到共享。多臺主機如果生成了相同的Request,只能各自去重,各個主機之間就無法做到去重了。
那麼要實現去重,這個指紋集合也需要是共享的,Redis正好有集合的儲存資料結構,我們可以利用Redis的集合作為指紋集合,那麼這樣去重集合也是利用Redis共享的。每臺主機新生成Request之後,把該Request的指紋與集合比對,如果指紋已經存在,說明該Request是重複的,否則將Request的指紋加入到這個集合中即可。利用同樣的原理不同的儲存結構我們也實現了分散式Reqeust的去重。
四、防止中斷
在Scrapy中,爬蟲執行時的Request佇列放在記憶體中。爬蟲執行中斷後,這個佇列的空間就被釋放,此佇列就被銷燬了。所以一旦爬蟲執行中斷,爬蟲再次執行就相當於全新的爬取過程。
要做到中斷後繼續爬取,我們可以將佇列中的Request儲存起來,下次爬取直接讀取儲存資料即可獲取上次爬取的佇列。我們在Scrapy中指定一個爬取佇列的儲存路徑即可,這個路徑使用JOB_DIR變數來標識,我們可以用如下命令來實現:
scrapy crawl spider -s JOB_DIR=crawls/spider
更加詳細的使用方法可以參見官方文件,連結為:https://doc.scrapy.org/en/latest/topics/jobs.html。
在Scrapy中,我們實際是把爬取佇列儲存到本地,第二次爬取直接讀取並恢復佇列即可。那麼在分散式架構中我們還用擔心這個問題嗎?不需要。因為爬取佇列本身就是用資料庫儲存的,如果爬蟲中斷了,資料庫中的Request依然是存在的,下次啟動就會接著上次中斷的地方繼續爬取。
所以,當Redis的佇列為空時,爬蟲會重新爬取;當Redis的佇列不為空時,爬蟲便會接著上次中斷之處繼續爬取。
五、架構實現
我們接下來就需要在程式中實現這個架構了。首先實現一個共享的爬取佇列,還要實現去重的功能。另外,重寫一個Scheduer的實現,使之可以從共享的爬取佇列存取Request。
幸運的是,已經有人實現了這些邏輯和架構,併發布成叫Scrapy-Redis的Python包。接下來,我們看看Scrapy-Redis的原始碼實現,以及它的詳細工作原理。