
Kubernetes基礎介紹和架構概述
Table of Contents
1 容器編排工具概述
k8s擴充套件docker單個容器的管理功能,實現誇多主機的問題,容器編排要負責網路,儲存,安全等問題。
容器編排系統,完成以下功能:
1.為docker提供私有的Registry
2.提供網路功能
3.提供共享儲存
4.確保容器間的安全
5.TeleMetry
容器編排的三個主要工具
1.docker的三劍客:docker machine+swarm+compose
docker machine,快速構建docker容器,加入叢集。
swarm:把容器加入到叢集中來
compose:面向swarm,實現容器的編排
2.mesos+marathon:系統資源排程框架,可以排程hadoop或者容器,不是專門為容器編排設定的
3.kubernetes:把容器歸類到一起,最小排程單位是容器集(Pod)
本文主要介紹kubernetes的相關內容
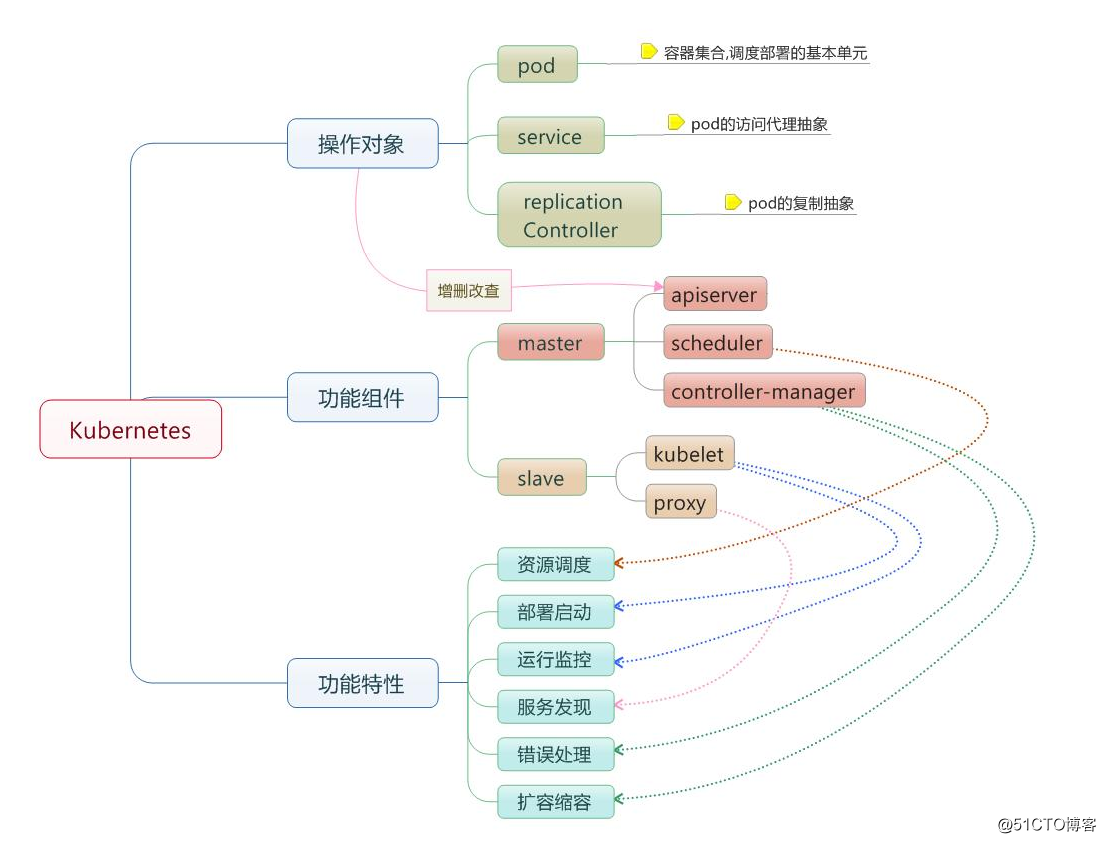
2 k8s整體概述
k8s,可監控系統的資源使用情況,進行容器的自動增加或者收縮,這就是所謂的容器編排
kubernetes:舵手,飛行員,參考谷歌內部的大規模內部容器排程系統Borg實現,使用Go語言開發。程式碼託管在github上,連結:https://github.com/kubernetes/kubernetes
k8s特性如下:
1.自動裝箱,自動容器的部署,不影響可用性
2.自我修復,如容器崩潰後快速重新啟動新的容器
3.自動實現水平擴充套件
4.自動實現服務發現和負載均衡
5.自動釋出和回滾
6.支援金鑰和配置管理,把應用程式的配置資訊通過服務來載入,而不是載入本地的配置。實現配置的統一
7.實現儲存編排
8.任務的批處理執行
k8s的叢集至少有兩個主機組成:master + node ,即為master/node架構,master為叢集的控制面板,master主機需要做冗餘,一般建議為3臺,而node主機不需要,因為node的主要作用是執行pod,貢獻計算能力和儲存能力,而pod控制器會自動管控pod資源,如果資源少,pod控制器會自動建立pod,即pod控制器會嚴格按照使用者指定的副本來管理pod的數量。客戶端的請求下發給master,即把建立和啟動容器的請求發給master,master中的排程器分析各node現有的資源狀態,把請求呼叫到對應的node啟動容器。
可以理解為k8s把容器抽象為pod來管理1到多個彼此間有非常緊密聯絡的容器,但是LAMP的容器主機A,M,P只是有關聯,不能說是非常緊密聯絡,因此A,M,P都要執行在三個不同的pod上。
在k8s中,要執行幾個pod,是需要定義一個配置檔案,在這個配置檔案裡定義用哪個控制器啟動和控制幾個pod,在每個pod裡要定義那幾臺容器,k8s通過這個配置檔案,去建立一個控制器,由此控制器來管控這些pod,如果這些pod的某幾個down掉後,控制器會通過健康監控功能,隨時監控pod,發現pod異常後,根據定義的策略進行操作,即可以進行自愈。
k8s內部需要5套證書,手動建立或者自動生成,分別為,etcd內部通訊需要一套ca和對應證書,etcd與外部通訊也要有一套ca和對應證書。APIserver間通訊需要一套證書,apiserver與node間通訊需要一套證書,node和pod間通訊需要一套ca
目前而言,還不能實現把所有的業務都遷到k8s上,如儲存,因為這個是有狀態應用,出現錯誤排查很麻煩,目前而且,k8s主要是執行無狀態應用。
所以一般而言,負載均衡器執行在K8s之外,nginx或者tomcat這種無狀態的應用運行於k8s叢集內部,而資料庫,如mysql,zabbix,zoopkeeper,有狀態的,一般運行於k8s外部,通過網路連線,實現k8s叢集的pod呼叫這些外部的有狀態應用。
k8s叢集架構如下
總體架構
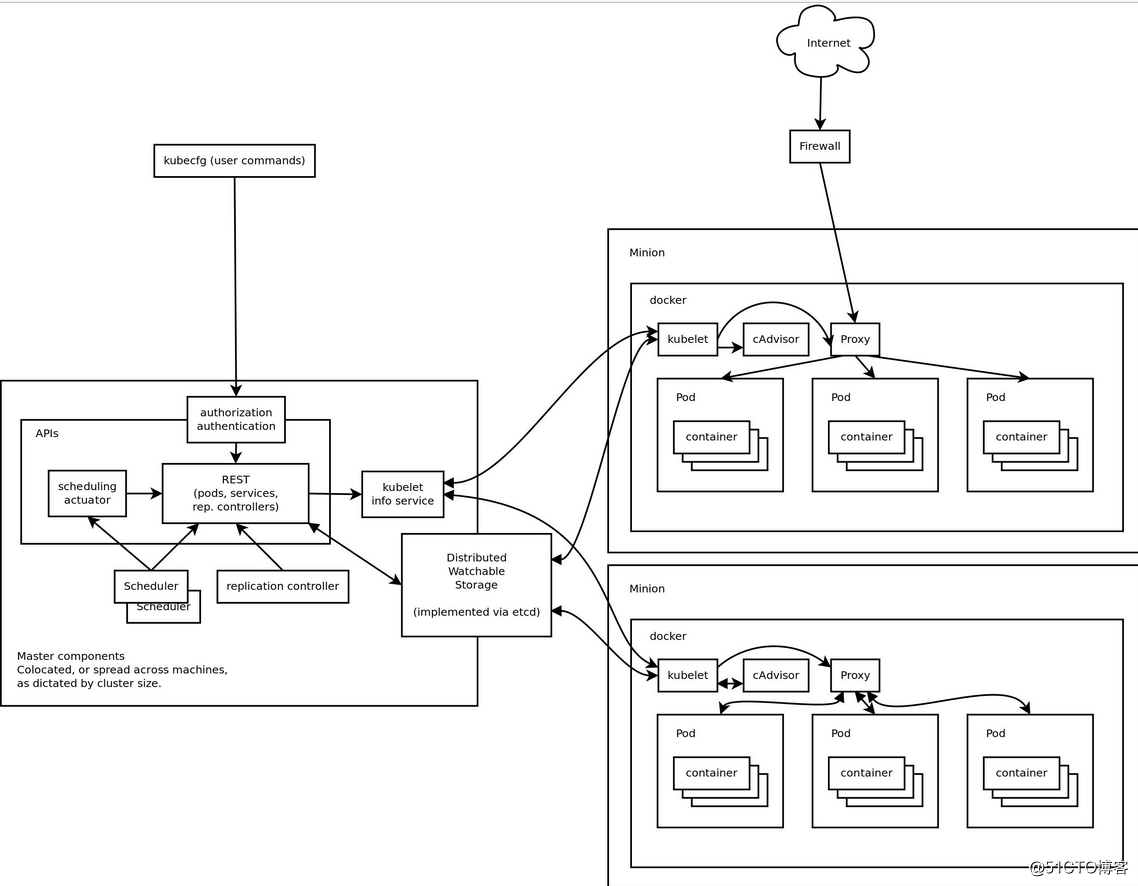

k8s的master和node的詳細架構如下
k8s的叢集元件如下:
master: apiserver,scheduler,controller-manager,etcd
node:kubelet(agent),kube-proxy,docker(container engine)
Registry:harbor,屬於叢集外部的
Addons(附件):kube-dns,UI(如 dashboard)等等。在叢集執行正常後,在叢集上執行pod實現。

k8s部署叢集整體環境架構
注意,下圖的ip可根據實際環境調整

3 master主機
master 有三個最關鍵的元件,apiserver,scheduler,controller-manager,執行為三個守護程序:
apiserver:負責接入請求的入口,解析請求,處理請求,即閘道器,任何到達請求必須經過apiserver
scheduler:請求到達後,由scheduler計算後端node的相關資源,如cpu或者記憶體使用情況後,負責排程到合適的node,並啟動pod,即選定某一節點後,有節點的kubelet負責節點上的操作如啟動pod,即scheduler會先做預選,選擇滿足條件的node,然後再做優選,最合適的node,啟動pod
controller-manager:控制器管理器,統一管控不同型別的資源,監控master上每個控制器的健康性,可以在每個master叢集上做冗餘高可用。其中,控制器用於確保已建立的容器處於健康狀態。
controller:控制器,自動建立pod資源(容器啟動),根據使用者的需求啟動和建立pod,可以在m個節點上執行n個容器,控制器根據label來識別pod。,使得pod能夠按照指定的數量執行。
controller 通過 label selector 來關聯 pod (lable),注意controller只是用來管理pod的健康性,不能進行pod流量導向,即管理pod,確保pod副本數量嚴格符合使用者的定義。
每一組pod都需要獨立的控制器來執行,實現跨節點自愈,管控pod的生命週期。控制器也是通過便籤和便籤選擇器來實現感知自己管控組內的pod
在k8s環境中,推薦使用控制器管理的pod,控制器有如下幾種:
ReplicationController。嚴格控制容器的副本數和滾動更新pod,在更新過程臨時超出副本數。也支援滾動回滾操作。
RelicaSet:宣告更新控制器
Deployment:負責無狀態應用pod控制,支援二級控制器(HPA,HorizontalPodAutoscaler水平pod自動控制器)。
StatefulSet:負責有狀態應用pod控制
DeamonSet:守護程序集,作用是在叢集中每一個node上都啟用一個pod副本,如果pod down了,DeamonSet會自動重啟這個pod,如果新增node,會自動新增。即自動下載映象,在這個node上啟用這個pod。
Job,Ctonjob:週期性pod控制,如臨時任務的job。
不同的控制器,滿足客戶不同型別的pod資源執行。
master 主機其他元件:
label selector ;標籤選擇器,根據標籤來選擇符合條件的資源物件的機制,不僅僅用於pod資源,所有的物件都可以打上標籤。k/v格式的資料。service和controller都是根據標籤和標籤控制器來識別pod資源。
etcd:分散式的高效能的鍵值儲存的資料庫系統,儲存叢集的物件狀態資訊,如apiserver對所有主機的操作結果,如建立pod,刪除pod,排程pod的結果狀態資訊都儲存在etcd中,如果這個外掛異常,則整個叢集執行都將異常,因為etcd異常後,整個叢集的狀態協議都將不能正常工作。因此etcd需要做高可用,防止單點故障。專門的元件,另外一個主機上安裝的元件,建議至少三個節點,為restfull風格的叢集。為https協議。
master示意圖如下
注意,API,UI,CLI都想API Server傳送請求

4 node主機
node節點上主要有三個主鍵,kubelet,kube-proxy,container engine(這裡用docker),介紹如下
kubelet:相當於k8s的節點級的agent,執行當地任務,如當前節點的啟動和當前節點的狀態狀態監測,和apiserver進行互動。
kube-proxy:為當前節點的pod生成iptables或者ipvs規則,實現了將使用者請求排程到後端pod,為service元件服務,負責與apiserver隨時保持通訊,一旦發現某一service後的pod發生改變,需要將改變儲存在apiserver中,而apiserver內容發生改變後,會生成通知事件,使得所有關聯apiserver的元件都能收到,而 kube-proxy可以收到這個通知事件,一旦發現某一service背後的pod資訊發生改變,kube-proxy就會把改變反應在本地的iptables或者ipvs規則上,實現動態的變化。kube-proxy有三個模型,userspace(名稱空間,和docker的名稱空間有區別,),iptables,ipvs,負責實現service的定義
container engine:作用是負責啟動或者執行有kubelete啟動的容器,如docker
此外,node節點上還有addons(附件),如dns,可以動態變動dns解析內容,如service的名稱改了,會自動觸發dns的記錄進行更改。
node示意圖如下

5 邏輯元件介紹
除了master和node上的關鍵元件,還有邏輯元件介紹如下
service:
service 通過 label selector 來關聯 pod (lable) ,提供一個固定端點,使得使用者的請求流量導向後端的pod,service為pod中的應用的客戶端提供一個固定的訪問端點,即clusterIP:ServicePort實現、另外通過DNS Addons實現服務把主機名和clusterIP做解析,使得訪問能夠通過主機名和埠來實現
service是在應用前面加一個代理層,這個代理層的主機名對應的ip不變,手動建立,比如nginx要配置後端的tomcat,那麼配置檔案上寫入的後端tomcat的ip應該是代理層上(service)的主機名(因為ip也可能變化),防止tomcat重建後ip變化。代理層上通過service的後端pod的label來感知後端pod,所以,無論pod的ip地址怎麼變化,只要label不變,service通過便籤選擇器(label selector)來動態關聯後端的pod。同理,由於應用可能被刪掉重新建立,因此,在所有的應用前,都需要有service,相當於是提供其他應用統一訪問的入口。實際上,service,提供穩定的訪問入口和排程功能,根據label來排程,只要pod的label不變,那麼即使pod的ip和埠變化了,都能被service識別,因為service根據label來識別pod物件。可以跨主機實現的,service相當於是由kube-proxy建立的iptables的dnat規則或者ipvs規則。k8s1.11版本中,已經把規則調整為ipvs規則。當一個請求到達service後,service會排程到對應的node上。如果service被誤刪了,那麼ip地址可能會變化,為了防止這種情況發生,k8s有一個附件,dns服務,完成服務發現,動態按需完成資源的遷移和改變,如每次建立一個service,就會把service對應的名稱和ip關係,放入到這個dns的解析庫中,那麼當service被刪掉時,對應解析記錄就會被刪掉,當service重建後,就會在這個解析庫中新建對應的解析記錄。因此只要前端應用配置的是service的主機名,那麼即使service重建,ip變更也不影響請求的排程。如果沒有了service,那麼前後端應用的銜接就不能固定,服務異常。
當客戶端發起請求,請求都先到servcie,service收到請求後,通過本地的iptables或者ipvs規則排程到後端的pod,如果pod不在同一node上,那麼存在一個跨主機排程問題。使用疊加網路(overlay)解決不同主機上網路問題,所有的pod都在同一網段,service才能實現正常排程。當宿主機把請求送出去後,報文封裝了兩個ip,容器ip和宿主機網絡卡的ip,這樣,容器才能實現跨主機間的網路訪問。即k8s要求所有的pod在同一網段,而且可以使用這個網路直接通訊。注意,service的ip和pod的ip不在同一網段,而且service的ip不是真的ip,即不配在某一個網絡卡上,僅僅是iptables上的某一個符號。因此service的ip是不能被ping通,service的ip被稱為cluster ip, pod的ip稱為 pod ip。
service作為k8s的物件有service的名稱,service的名稱,相當於是服務的名稱,而名稱可以被dns解析。service有兩種型別,一種是隻能pod內部訪問,一種是可以供k8s外部訪問。
每個應用的pod都要有專用的service進行排程。
儲存卷,pod級別的卷,pod間存在卷的問題,因此,資料建議使用外部的專用卷,而不要使用掛載的本地容器的卷。當容器重建時,需要載入相同的卷。儲存卷有四級概念,pv(持久卷),pvc(持久卷申請),volume(儲存卷),volume mount(儲存卷掛載)。
pod:
Pod指容器集,原子排程單元,一個Pod的所有容器運行於同一節點。k8s排程的目標是pod,,pod可以理解為容器的外殼,pod是k8s最小的排程單元。一個pod可以包含多個容器。一組聯絡非常緊密的容器組成pod,同一組pod共享networks,uts,storage,volumes,通過ipc機制進行通訊,跨pod的容器,需要藉助於外部網路外掛進行通訊,每一個pod有一個podIP。一個pod相當於是傳統意義上的虛擬機器。儲存卷屬於pod。一般而言,一個pod僅放一個容器。一個pod內的所有容器只能運行於同一node上。
k8s的最核心功能就是為了執行pod,其他元件是為了pod能夠正常執行而執行的。
pod可以分為兩類:
1.自主式pod,
2.控制器管理的pod
一個pod上有兩類元資料,label 和 annotation
label:標籤,對資料型別和程度要求嚴格,
annotation:註解,用於儲存自己定義的複雜元資料,用來描述pod的屬性
外部請求訪問內部的pod,有三級轉發,第一級,先到nodeip(宿主機ip)對應的埠,然後被轉為cluster ip的service 埠,然後轉換為PodIP的containerPort。
注意,在k8s叢集外部還有一個排程器(load blance),這個排程器跟k8s沒有關係,需要手動管理。這個排程器可藉助keepalive實現高可用。
k8s的執行空間需要分割槽,即分成邏輯區域,如用於區分不同專案,每個邏輯區域為一個名詞空間(usersapce),這裡的名稱空間為k8s特有的名稱空間,和docker的名稱空間有區別。用於隔離pod。實現了網路邊界的隔離。提供了管理的邊界。網路策略可以實現不同名稱空間是否可以實現網路訪問。預設情況下,不需要建立namespace。
6 k8s通訊
service地址和pod地址在不同網段,service地址為虛擬地址,不配在pod上或主機上,外部訪問時,先到節點網路,再打service網路,最後代理給pod網路。
同一pod內的多個容器通過lo通訊
各pod間的通訊,pod通過overlay network的隧道轉發實現跨主機間報文轉發,實現直接通訊。
其中,疊加網路
1.一個數據包(或幀)封裝在另一個數據包內;被封裝的包轉發到隧道端點後再被拆裝。
2.疊加網路就是使用這種所謂“包內之包”的技術安全地將一個網路隱藏在另一個 網路中,然後將網路區段進行遷移。
pod和service間的通訊,
CNI:容器網路集介面,網路解決方案,有三種不同ip,ip地址解釋如下
node ip,節點網路,宿主機物理ip
cluster ip,叢集ip,為service 網路,為固定的接入埠,即service元件的ip地址,不會配置在任何網路介面上,clusterIP定義在iptables或ipvs規則中。k8s叢集自己管控和提供
pod ip ,屬於pod網路,為pod提供ip地址,使得pod間直接通訊,但是,叢集間pod通訊要藉助於 cluster ip,pod和叢集外通訊,還要藉助於node ip。pod網路要通過CNI規範藉助於外部的虛擬化網路模型實現,為pod配置ip地址,使得pod間能夠通訊。
其中,虛擬化網路解決方案有如下幾種較為著名的外掛:
flannel:簡單易用,不支援網路策略,配置本地網路協議棧,從而為執行在這個主機上的pod提供ip,但是,不能提供網路策略的功能。
project calico:支援網路策略和網路配置,預設基於BGP構建網路,實現直接通訊,三層隧道網路,目前生產主要使用這個模型
Canel:是flannel+calico的結合,用flannel提供網路,calico實現策略配置
kube-rote
weave network
k8s的網路模型如下
7.我的Kubernetes學習資源
馬哥Kubernetes視訊資源
Kubernetes進階實戰

參考