
倒排檔案索引(Inverted File Index)
倒排檔案是一種在各大搜索引擎中被主要使用的索引的方式,並且它也是搜尋引擎中一個核心的技術。
一個典型的倒排索引主要由詞彙表(也叫索引項)和事件表(也叫檔案連結串列)兩部分組成。詞彙表是用來存放分詞詞典的,通常稱存放詞彙表的檔案為索引檔案;事件表是用來存放這個檔案中對應詞彙表中詞彙出現的位置和次數的,通常稱存放出現位置的檔案為位置檔案。yi
一,基本概念:
【Definition】Index is a mechanism for locating a given term in a text.
【Definition】Inverted file contains a list of pointers (e.g. the number of a page) to all occurrences of that term in the text.(
Inverted because it lists for a term, all documents that contain the term)
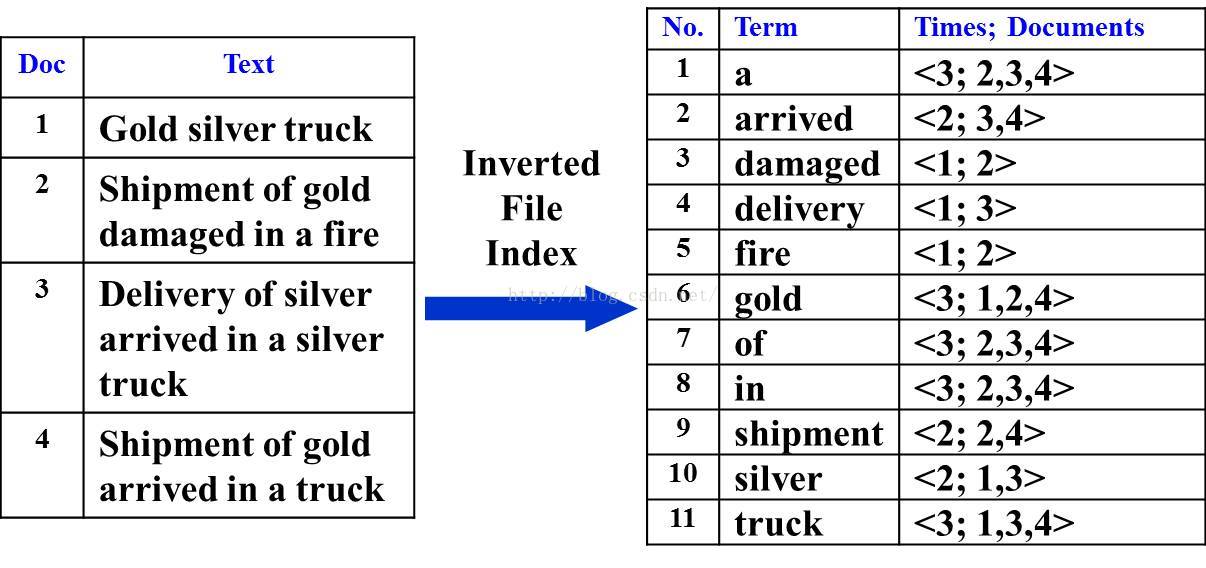

文件(Document):一般搜尋引擎的處理物件是網際網路網頁,而文件這個概念要更寬泛些,代表以文字形式存在的儲存物件,相比網頁來說,涵蓋更多種形式,比如Word,PDF,html,XML等不同格式的檔案都可以稱之為文件。再比如一封郵件,一條簡訊,一條微博也可以稱之為文件。在本書後續內容,很多情況下會使用文件來表徵文字資訊。
文件集合(Document Collection):由若干文件構成的集合稱之為文件集合。比如海量的網際網路網頁或者說大量的電子郵件都是文件集合的具體例子。
文件編號(Document ID):在搜尋引擎內部,會將文件集合內每個文件賦予一個唯一的內部編號,以此編號來作為這個文件的唯一標識,這樣方便內部處理,每個文件的內部編號即稱之為“文件編號”,後文有時會用DocID來便捷地代表文件編號。
單詞編號(Word ID):與文件編號類似,搜尋引擎內部以唯一的編號來表徵某個單詞,單詞編號可以作為某個單詞的唯一表徵。
倒排索引(Inverted Index):倒排索引是實現“單詞-文件矩陣”的一種具體儲存形式,通過倒排索引,可以根據單詞快速獲取包含這個單詞的文件列表。倒排索引主要由兩個部分組成:“單詞詞典”和“倒排檔案”。
單詞詞典:搜尋引擎的通常索引單位是單詞,單詞詞典是由文件集合中出現過的所有單詞構成的字串集合,單詞詞典內每條索引項記載單詞本身的一些資訊以及指向“倒排列表”的指標。
倒排列表(PostingList):倒排列表記載了出現過某個單詞的所有文件的文件列表及單詞在該文件中出現的位置資訊,每條記錄稱為一個倒排項(Posting)。根據倒排列表,即可獲知哪些文件包含某個單詞。
倒排檔案(Inverted File):所有單詞的倒排列表往往順序地儲存在磁碟的某個檔案裡,這個檔案即被稱之為倒排檔案,倒排檔案是儲存倒排索引的物理檔案。
二,單詞詞典的實現方式:
單詞詞典是倒排索引中非常重要的組成部分,它用來維護文件集合中出現過的所有單詞的相關資訊,同時用來記載某個單詞對應的倒排列表在倒排檔案中的位置資訊。在支援搜尋時,根據使用者的查詢詞,去單詞詞典裡查詢,就能夠獲得相應的倒排列表,並以此作為後續排序的基礎。
對於一個規模很大的文件集合來說,可能包含幾十萬甚至上百萬的不同單詞,能否快速定位某個單詞,這直接影響搜尋時的響應速度,所以需要高效的資料結構來對單詞詞典進行構建和查詢,常用的資料結構包括雜湊加連結串列結構和樹形詞典結構。
1 雜湊加連結串列
圖1-7是這種詞典結構的示意圖。這種詞典結構主要由兩個部分構成:
主體部分是雜湊表,每個雜湊表項儲存一個指標,指標指向衝突連結串列,在衝突連結串列裡,相同雜湊值的單詞形成連結串列結構。之所以會有衝突連結串列,是因為兩個不同單詞獲得相同的雜湊值,如果是這樣,在雜湊方法裡被稱做是一次衝突,可以將相同雜湊值的單詞儲存在連結串列裡,以供後續查詢。

圖1-7 雜湊加連結串列詞典結構
在建立索引的過程中,詞典結構也會相應地被構建出來。比如在解析一個新文件的時候,對於某個在文件中出現的單詞T,首先利用雜湊函式獲得其雜湊值,之後根據雜湊值對應的雜湊表項讀取其中儲存的指標,就找到了對應的衝突連結串列。如果衝突連結串列裡已經存在這個單詞,說明單詞在之前解析的文件裡已經出現過。如果在衝突連結串列裡沒有發現這個單詞,說明該單詞是首次碰到,則將其加入衝突連結串列裡。通過這種方式,當文件集合內所有文件解析完畢時,相應的詞典結構也就建立起來了。
在響應使用者查詢請求時,其過程與建立詞典類似,不同點在於即使詞典裡沒出現過某個單詞,也不會新增到詞典內。以圖1-7為例,假設使用者輸入的查詢請求為單詞3,對這個單詞進行雜湊,定位到雜湊表內的2號槽,從其保留的指標可以獲得衝突連結串列,依次將單詞3和衝突連結串列內的單詞比較,發現單詞3在衝突連結串列內,於是找到這個單詞,之後可以讀出這個單詞對應的倒排列表來進行後續的工作,如果沒有找到這個單詞,說明文件集合內沒有任何文件包含單詞,則搜尋結果為空。
2 樹形結構
B樹(或者B+樹)是另外一種高效查詢結構,圖1-8是一個 B樹結構示意圖。B樹與雜湊方式查詢不同,需要字典項能夠按照大小排序(數字或者字元序),而雜湊方式則無須資料滿足此項要求。
B樹形成了層級查詢結構,中間節點用於指出一定順序範圍的詞典專案儲存在哪個子樹中,起到根據詞典項比較大小進行導航的作用,最底層的葉子節點儲存單詞的地址資訊,根據這個地址就可以提取出單詞字串。
圖1-8 B樹查詢結構
三,索引實現過程---Index Generator
<span style="font-size:14px;">while ( <strong>read a document D</strong> ) {
while ( <strong>read a term T in D</strong> ) {//stop filter
if ( <strong>Find( Dictionary, T ) == false </strong>) //vocabulary scanner
<strong>Insert( Dictionary, T )</strong>;//vocabulary insertor
Get T’s posting list;
Insert a node to T’s posting list;
}
}
<strong>Write the inverted index to disk;</strong></span>
注意:while reading a term
1.Process a word so that only itsstem or root form is left.
2.Some words are so common thatalmost every document contains them, such as “a” “the” “it”. It is useless to index them. They are called stopwords. We can eliminate them from the original documents.
四,關於記憶體的Possible problems and solution:
while not having enough memory:
Sol-1:Distributed indexing (for web-scale indexing)--Each node contains index of a subset ofcollection---many computer work together

Sol-2:Dynamic indexing:Docs come in over time - postings updates for terms already in dictionary - new terms added to dictionary

sol-3 improve memory untilizaiton:--compression: 將空格去除,將詞彙表線性儲存,記錄每個單詞首字母位置差序列。

五,效能--Measurement:
Relevance measurement requires 3 elements:
1. A benchmark document collection 2. A benchmark suite of queries 3. A binary assessment of either Relevant or Irrelevant for each query-doc pairRecall and Precision:
先看下面這張圖來理解了,後面再具體分析。下面用P代表Precision,R代表Recall

通俗的講,Precision 就是檢索出來的條目中(比如網頁)有多少是準確的,Recall就是所有準確的條目有多少被檢索出來了。
下面這張圖介紹True Positive,False Negative等常見的概念,P和R也往往和它們聯絡起來。

我們當然希望檢索的結果P越高越好,R也越高越好,但事實上這兩者在某些情況下是矛盾的。比如極端情況下,我們只搜出了一個結果,且是準確的,那麼P就是100%,但是R就很低;而如果我們把所有結果都返回,那麼必然R是100%,但是P很低。
因此在不同的場合中需要自己判斷希望P比較高還是R比較高。如果是做實驗研究,可以繪製Precision-Recall曲線來幫助分析(我應該會在以後介紹)。

F Measure
前面已經講了,P和R指標有的時候是矛盾的,那麼有沒有辦法綜合考慮他們呢?我想方法肯定是有很多的,最常見的方法應該就是F Measure了,有些地方也叫做F Score,都是一樣的。
F Measure 是Precision和Recall加權調和平均:

F1-Measure
當引數β=1時,就是最常見的F1-Measure了:
F1 = 2P*R / (P+R)