
word2vec——高效word特徵求取
繼上次分享了經典統計語言模型,最近公眾號中有很多做NLP朋友問到了關於word2vec的相關內容, 本文就在這裡整理一下做以分享。 本文分為
- 概括word2vec
- 相關工作
- 模型結構
- Count-based方法 vs. Directly predict
幾部分,暫時沒有加實驗章節,但其實感覺word2vec一文中實驗還是做了很多工作的,希望大家有空最好還是看一下~
概括word2vec
要解決的問題: 在神經網路中學習將word對映成連續(高維)向量, 其實就是個詞語特徵求取。
特點:
1. 不同於之前的計算cooccurrence次數方法,減少計算量
2. 高效
3. 可以輕鬆將一個新句子/新詞加入語料庫
主要思想:神經網路語言模型可以用兩步進行訓練:1. 簡單模型求取word vector; 在求取特徵向量時,預測每個詞周圍的詞作為cost 2. 在word vector之上搭建N-gram NNLM,以輸出詞語的概率為輸出進行訓練。
相關工作
在傳統求取word的空間向量表徵時, LSA 將詞和文件對映到潛在語義空間,從而去除了原始向量空間中的一些“噪音”,但它無法儲存詞與詞之間的linear regularities; LDA 是一個三層貝葉斯概率模型,包含詞、主題和文件三層結構。文件到主題服從Dirichlet分佈,主題到詞服從多項式分佈, 但是隻要訓練資料大了, 計算量就一下飈了。
基於神經網路的詞語向量表徵方法在[Y. Bengio, R. Ducharme, P. Vincent. A neural probabilistic language model, JMLR 2003]中就有提出, 名為NNLM, 它是一個前向網路, 同時學習詞語表徵和一個統計語言模型(後面具體講)。
在Mikolov的碩士論文[1]和他在ICASSP 2009上發表的文章[2]中, 用一個單隱層網路訓練詞語表徵, 然後將這個表徵作為NNLM的輸入進行訓練。 Word2vec是訓練詞語表徵工作的一個拓展。
模型結構
首先回顧NNLM,RNNLM,然後來看Word2Vec中提出的網路——CBOW,skip-gram Model。
1 . NNLM[3]
NNLM的目標是在一個NN裡,求第t個詞的概率, 即
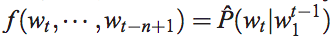
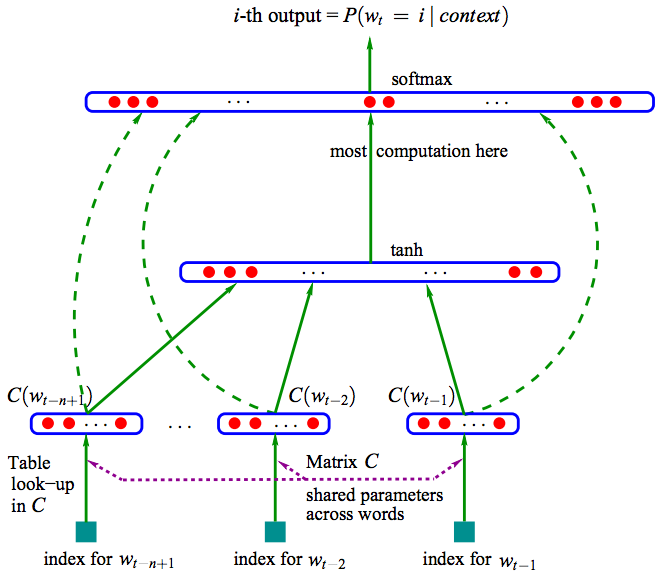
其中f是這個神經網路, 包括 input,projection, hidden和output。將其分解為兩個對映:C和g,C是word到word vector的特徵對映(通過一個|V|*D的對映矩陣實現),也稱作look-up table, g是以word特徵為輸入,輸出|V|個詞語概率的對映:
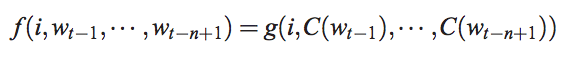
如下圖所示:
輸入: n個之前的word(其實是他們的在詞庫V中的index)
對映: 通過|V|*D的矩陣C對映到D維
隱層: 對映層連線大小為H的隱層
輸出: 輸出層大小為|V|,表示|V|個詞語的概率
用parameter個數度量網路複雜度, 則這個網路的複雜度為:
其中複雜度最高的部分為H*V, 但通常可以通過hierarchical softmax或binary化詞庫編碼將|V|降至
2 . RNNLM
RNN在語言模型上優於其他神經網路,因為不用像上面NNLM中的輸入要定死前N個詞的N。(具體RNN的結構我會在下篇中講)簡單地說, RNN就是一個隱層自我相連的網路, 隱層同時接收來自t時刻輸入和t-1時刻的輸出作為輸入, 這使得RNN具有短期記憶能力, 所以RNNLM的複雜度為:
同樣地,其中
由於複雜度最大的部分都在hidden layer, 而且我們的中級目標是提特徵(而不是生成語言模型),文中就想能不能犧牲hidden layer的非線性部分, 從而高效訓練。 這也是Word2vec中速度提升最多的部分。 這也就是一個Log linear model。所以本質上, word2vec並不是一個深度模型。文中提出了兩種log linear model,如下面所述。
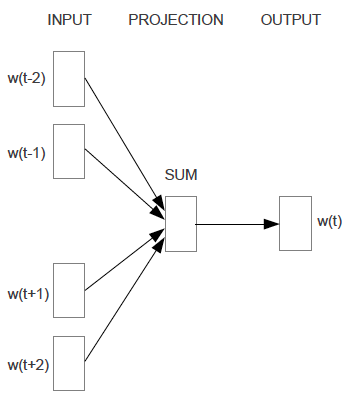
3 . Proposed Method 1 - Continuous Bag-of-Words(CBOW) Model
CBOW的網路結構和NNLM類似,變化:
- CBOW去掉了NNLM的非線性部分
- CBOW不考慮word之間的先後順序, 一起放進bag,也就是在上面NNLM的projection層將對映後的結果求和/求平均(而非按照先後順序連線起來)
- 輸入不止用了歷史詞語,還用了未來詞語。 即, 用t-n+1…t-1,t+1,…t+n-1的word作為輸入,目標是正確分類得到第t個word。
PS: 實驗中得到的best n=4
CBOW的複雜度為:
CBOW結構圖:
3 . Proposed Method 2 - Continuous Skip-gram Model
與CBOW相反,Continuous Skip-gram Model不利用上下文。 其輸入為當前word,經過projection的特徵提取去預測該word周圍的c個詞,其cost function為:
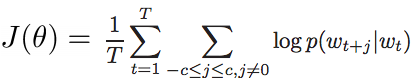
如下圖所示。這裡c增大有利於模型的完備性, 但過大的c可能造成很多無關詞語相關聯, 因此用隨機取樣方法,遠的詞少採, 近的多采。
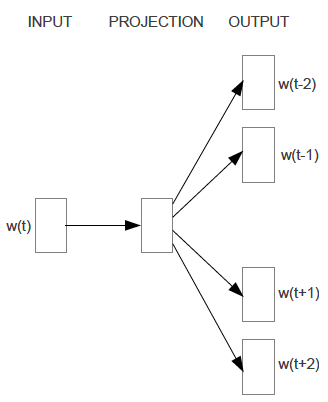
比如定義最大周圍距離為C,則對於每個詞w(t),就選擇距離為R=range(1,C), 選前後各R個詞作為預測結果。
所以,Continuous Skip-gram Model的複雜度為:
具體來說,最簡單的情況下,
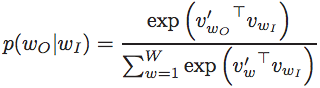
其中v和v’分別為輸入和輸出中的word特徵向量。所以說, word2vec方法本質上是一個動態的邏輯迴歸。
Count-based方法 vs. Directly predict
最後我們看一下之前我們講過的幾個基於統計的傳統語言模型與word2vec這種直接預測的方法的比較:

圖片摘自Stanford CS244。
參考文獻:
- NNLM: Y. Bengio, R. Ducharme, P. Vincent. A neural probabilistic language model, JMLR 2003
- 類似工作:T. Mikolov. Language Modeling for Speech Recognition in Czech, Masters thesis
- 類似工作:T. Mikolov, J. Kopecky´, L. Burget, O. Glembek and J. Cˇ ernocky´. Neural network based language models for higly inflective languages, In: Proc. ICASSP 2009.]
- 類似工作:Pennington J, Socher R, Manning C D. Glove: Global vectors for word representation[J]. Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014), 2014, 12.