
資料結構-演算法-時間複雜度計算
演算法的時間複雜度定義為:
在進行演算法分析時,語句總的執行次數T(n)是關於問題規模n的函式,進而分析T(n)隨n的變化情況並確定T(n)的數量級。演算法的時間複雜度,也就是演算法的時間量度,記作:T(n}=0(f(n))。它表示隨問題規模n的增大,演算法執行時間的埔長率和 f(n)的埔長率相同,稱作演算法的漸近時間複雜度,簡稱為時間複雜度。其中f( n)是問題規橫n的某個函式。
根據定義,求解演算法的時間複雜度的具體步驟是:
⑴ 找出演算法中的基本語句;
演算法中執行次數最多的那條語句就是基本語句,通常是最內層迴圈的迴圈體。
⑵ 計算基本語句的執行次數的數量級;
只需計算基本語句執行次數的數量級,這就意味著只要保證基本語句執行次數的函式中的最高次冪正確即可,可以忽略所有低次冪和最高次冪的係數。這樣能夠簡化演算法分析,並且使注意力集中在最重要的一點上:增長率。
⑶ 用大Ο記號表示演算法的時間效能。
將基本語句執行次數的數量級放入大Ο記號中。
如何推導大o階呢?我們給出了下面 的推導方法:
1.用常數1取代執行時間中的所有加法常數。
2.在修改後的執行次數函式中,只保留最髙階項。
3.如果最高階項存在且不是1,則去除與這個項相乘的常數。
簡單的說,就是保留求出次數的最高次冪,並且把係數去掉。 如T(n)=2n^2+n+1 =O(n^2)
舉個例子。
#include "stdio.h" int main() { int i, j, x = 0, sum = 0, n = 100; /* 執行1次 */ for( i = 1; i <= n; i++) /* 執行n+1次 */ { sum = sum + i; /* 執行n次 */ for( j = 1; j <= n; j++) /* 執行n*(n+1)次 */ { x++; /* 執行n*n次 */ sum = sum + x; /* 執行n*n次 */ } } printf("%d", sum); /* 執行1次 */ }
按照上面推導“大O階”的步驟,我們來看
第一步:“用常數 1 取代執行時間中的所有加法常數”,
則上面的算式變為:執行總次數 =3n^2 + 3n + 1
(直接相加的話,應該是T(n) = 1 + n+1 + n + n*(n+1) + n*n + n*n + 1 = 3n^2 + 3n + 3。現在用常數 1 取代執行時間中的所有加法常數,就是把T(n) = 3n^2 + 3n + 3中的最後一個3改為1. 就得到了 T(n) = 3n^2 + 3n + 1)
第二步:“在修改後的執行次數函式中,只保留最高階項”。
這裡的最高階是 n 的二次方,所以算式變為:執行總次數 = 3n^2
第三步:“如果最高階項存在且不是 1 ,則去除與這個項相乘的常數”。
這裡 n 的二次方不是 1 所以要去除這個項的相乘常數,算式變為:執行總次數 = n^2
因此最後我們得到上面那段程式碼的演算法時間複雜度表示為: O( n^2 )
下面我把常見的演算法時間複雜度以及他們在效率上的高低順序記錄在這裡,使大家對演算法的效率有個直觀的認識。
O(1) 常數階 < O(logn) 對數階 < O(n) 線性階 < O(nlogn) < O(n^2) 平方階 < O(n^3) < { O(2^n) < O(n!) < O(n^n) }
最後三項用大括號把他們括起來是想要告訴大家,如果日後大家設計的演算法推匯出的“大O階”是大括號中的這幾位,那麼趁早放棄這個演算法,在去研究新的演算法出來吧。因為大括號中的這幾位即便是在 n 的規模比較小的情況下仍然要耗費大量的時間,演算法的時間複雜度大的離譜,基本上就是“不可用狀態”。
好了,原理就介紹到這裡了。下面通過幾個例子具體分析下時間複雜度計算過程。
一。計算 1 + 2 + 3 + 4 + ...... + 100。
常規演算法,程式碼如下:
#include "stdio.h"
int main()
{
int i, sum = 0, n = 100; /* 執行1次 */
for( i = 1; i <= n; i++) /* 執行 n+1 次 */
{
sum = sum + i; /* 執行n次 */
//printf("%d \n", sum);
}
printf("%d", sum); /* 執行1次 */
}從程式碼附加的註釋可以看到所有程式碼都執行了多少次。那麼這寫程式碼語句執行次數的總和就可以理解為是該演算法計算出結果所需要的時間。該演算法所用的時間(演算法語句執行的總次數)為: 1 + ( n + 1 ) + n + 1 = 2n + 3
而當 n 不斷增大,比如我們這次所要計算的不是 1 + 2 + 3 + 4 + ...... + 100 = ? 而是 1 + 2 + 3 + 4 + ...... + n = ?其中 n 是一個十分大的數字,那麼由此可見,上述演算法的執行總次數(所需時間)會隨著 n 的增大而增加,但是在 for 迴圈以外的語句並不受 n 的規模影響(永遠都只執行一次)。所以我們可以將上述演算法的執行總次數簡單的記做: 2n 或者簡記 n
這樣我們就得到了我們設計的演算法的時間複雜度,我們把它記作: O(n)
再來看看高斯的演算法,程式碼如下:
#include "stdio.h"
int main()
{
int sum = 0, n = 100; /* 執行1次 */
sum = (1 + n) * n/2; /* 執行1次 */
printf("%d", sum); /* 執行1次 */
}這個演算法的時間複雜度: O(3),但一般記作 O(1)。
從感官上我們就不難看出,從演算法的效率上看,O(1) < O(n) 的,所以高斯的演算法更快,更優秀。
這也就難怪為什麼每本演算法書開篇都是拿高斯的這個例子來舉例了(至少我看的都是)...人家也確實有那個資本。
二。求兩個n階方陣C=A*B的乘積其演算法如下:
//右邊列為語句執行的頻度
void MatrixMultiply(int A[n][n],int B [n][n],int C[n][n])
{
(1) for(int i=0; i <n; i++) //n+1
{
(2) for (j=0;j < n; j++) //n*(n+1)
{
(3) C[i][j]=0; //n^2
(4) for (k=0; k<n; k++) //n^2*(n+1)
{
(5) C[i][j]=C[i][j]+A[i][k]*B[k][j]; //n^3
}
}
}
}
T(n) = 2n^3+3n^2+2n+1; 利用大O表示法,該演算法的時間複雜度為O(n^3)。
三。分析下列時間複雜度
void test_(int n)
{
i = 1, k = 100;
while (i<n)
{
k = k + 1;
i += 2;
}
}設for迴圈語句執行次數為T(n),則 i = 2T(n) + 1 <= n - 1, 即T(n) <= n/2 - 1 = O(n)
四。分析下列時間複雜度
void test_2(int b[], int n)
{
int i, j, k;
for (i=0; i<n-1; i++)
{
k = i;
for (j=i+1; j<n; j++)
{
if (b[k] > b[j])
{
k = j;
}
}
x = b[i];
b[i] = b[k];
b[k] = x;
}
}其中,演算法的基本運算語句是
if (b[k] > b[j])
{
k = j;
}
其執行次數T(n)為:
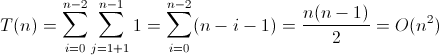
五。分析下列時間複雜度
void test_3(int n)
{
int i = 0, s = 0;
while (s<n)
{
i++;
s = s + i;
}
}其中,演算法的基本運算語句即while迴圈內部分,
設while迴圈語句執行次數為T(n),則
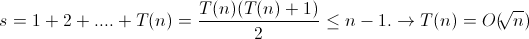
六。Hanoi(遞迴演算法)時間複雜度分析
void hanoi(int n, char a, char b, char c)
{
if (n==1)
{
printf("move %d disk from %c to %c \n", n, a, c); //執行一次
}
else
{
hanoi(n-1, a, c, b); //遞迴n-1次
printf("move %d disk from %c to %c \n", n, a, c); //執行一次
hanoi(n-1, b, a, c); //遞迴n-1次
}
}對於遞迴函式的分析,跟設計遞迴函式一樣,要先考慮基情況(比如hanoi中n==1時候),這樣把一個大問題劃分為多個子問題的求解。
故此上述演算法的時間複雜度的遞迴關係如下:
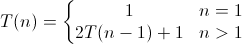
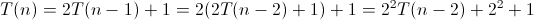
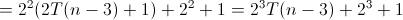

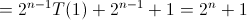
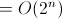
好吧,對於演算法的時間複雜度分析就講到這裡了..
今天是10月7號了。 馬上又要開課了, 大二學習真苦逼阿。
就扯到這裡,希望對大家有所幫助。
學習的路上,與君共勉。