
Hadoop與Spark演算法分析(四)——PageRank演算法
PageRank是用於解決網頁重要性排序的關鍵技術之一,其基於網頁之間連結關係構建一個有向圖結構,實現各個網頁級別的劃分。一個網頁的PageRank值(後面簡稱PR值),取決於其他網頁對該網頁的貢獻和,以公式形式表示為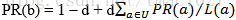
1. 實驗準備
由於Hadoop與Spark對於PageRank演算法的實現過程不同,這裡分別對Hadoop與Spark演算法輸入檔案進行說明。
對於Hadoop輸入檔案,每行的資料資訊包含網頁ID、網頁初始PR值1.0以及該網頁連結的其他網頁ID,以製表符隔開,如
A 1 B,C
B 1 C
C 1 A,D
D 1 B,E
E 1 A對於Spark輸入檔案,以網頁ID以及該網頁連結的每一個網頁ID,作為單獨一行儲存,如
A B
A C
B C
C A
C D
D B
D E
E A2. Hadoop實現
為了完成後續的迭代計算,map過程需要將連結關係圖和對其他網頁的貢獻值分別傳遞給reduce端。
reduce過程根據key將最終計算的PR值與連結關係圖合併輸出,用於下次迭代的map端。
測試以10次為收斂標準迭代進行,具體程式碼實現如下:
package org.hadoop.test;
import 3. Spark實現
Spark實現過程將該網頁的連結網頁RDD與PR值RDD合併為一個RDD執行運算元操作,並將連結關係圖緩存於記憶體,便於後續迭代計算。
具體程式碼實現如下:
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by rose on 16-4-26.
*/
object PageRank {
def main(args:Array[String]): Unit ={
if(args.length != 2){
println("Usage: <in> <out>")
return
}
val conf = new SparkConf().setAppName("PageRank")
val sc = new SparkContext(conf)
val lines = sc.textFile(args(0))
val links = lines.map(line=>{
val parts = line.split("\\s")
(parts(0), parts(1))
}).distinct().groupByKey().cache()
var ranks = links.mapValues(v => 1.00)
for(i <- 1 to 10){
val contrib = links.join(ranks).values.flatMap {
case (urls, rank) => {
val size = urls.size
urls.map(url => (url, rank/size))
}
}
ranks = contrib.reduceByKey(_+_).mapValues(0.15+0.85*_)
}
ranks.saveAsTextFile(args(1))
}
}
4. 執行過程
1)上傳本地檔案到HDFS目錄下
在HDFS上建立輸入資料夾
$hadoop fs -mkdir -p pageRank/input上傳本地測試檔案到叢集的input目錄下
$hadoop fs -put ~/file* pageRank/input檢視叢集檔案目錄
$hadoop fs -ls pageRank/input2)執行程式
將矩陣乘法演算法程式PageRank打包為字尾名為jar的壓縮檔案PageRank.jar,進入到壓縮檔案所在資料夾(這裡以一個file輸入檔案和一個output輸出資料夾為例說明)。
Hadoop程式執行如下命令執行
$hadoop jar ~/hadoop/PageRank.jar org.hadoop.test.PageRank pageRank/input/file pageRank/hadoop/outputSpark程式執行如下命令執行
$spark-submit --master yanr-client --class PageRank ~/spark/PageRank.jar hdfs://master:9000/pageRank/input/file hdfs://master:9000/pageRank/spark/output3)檢視執行結果
檢視Hadoop執行結果
$hadoop fs -ls pageRank/hadoop/output檢視Spark執行結果
$hadoop fs -ls pageRank/spark/output5. 測試對比

如圖所示為PageRank測試對比圖,Hadoop計算需要將每次迭代計算結果儲存在HDFS中,以供下次迭代作為輸入資料進行計算,而Spark只需要每次迭代計算上一次快取在記憶體中的結果資料即可。對比Hadoop平臺,Spark對於迭代式運算有著顯著的優勢,隨著測試集複雜度的上升,優勢更加明顯。