
用次世代2.3訓練自己的字元庫cds小demo
從我前幾天寫的 python 基於次世代驗證碼識別系統的小demo 中大家可以得知,如果有antiVC.dll 和關於特定網站的字元庫cds,我們就能夠讓瀏覽器自動識別驗證碼了。雖然網路有不少視訊關於怎麼訓練cds,我還是總結下吧,哎,備忘。
自己訓練資料相對於去購買什麼超級鷹API啊,de-captcher啊這種驗證碼識別平臺,有2個好處,一是不用考慮網路延遲,二是API都是收費的,小弟我也是Naive得貢獻了10幾刀的,╮(╯▽╰)╭
這裡可以貢獻下怎麼用de-captcher的驗證平臺(前提是你先註冊了de-captcher使用者並且購買了次數):
#驗證碼線上驗證 def getTextFromImg(img_file): data = { 'username': 'your_user', 'password': 'your_pass', 'function': 'picture2', 'pict_to': '0', 'pict_type': '0', 'pict': img_file } keys = 'ResultCode|MajorID|MinorID|Type|Timeout|Text'.split('|') de_captcher_server = "http://poster.de-captcher.com/" try: opener = urllib2.build_opener(urllib2.HTTPCookieProcessor()) result = opener.open(de_captcher_server, urllib.urlencode(data)) data = result.read() #print 'check_code:',data return dict(zip(keys, data.split('|'))) except KeyError,e: print str(e) return result
可以發現它的驗證碼地址是我們最喜歡的固定URL,每次F5都是新的驗證碼。
有些網站驗證碼動態URL,而且還是JS生成,我們需要JS解析器。
那個要自己寫指令碼跑,思路有兩種:
二是通過selenium+PhantomJS,動態解析頁面原始碼下載下來,獲取URL後通過訪問下載圖片,可參考我之前寫的:selenium 操控瀏覽器
有些同學可能發現了,方法二得到的驗證碼是不同於第一次獲得的驗證碼,畢竟每次訪問都會更新,又有什麼關係呢?
我們只要獲得驗證碼圖片用來訓練就行了。
總之上面的情況暫時不考慮,我們現在遇到的是最簡單的情況,同一URL可獲取不同的驗證碼:

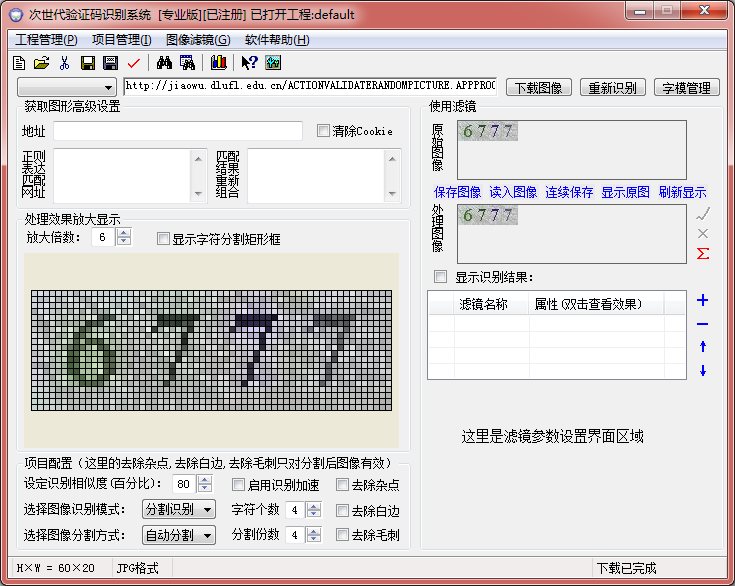
然後依次選擇:分割識別、平均分割(因為看起來四四方方的很規整)、顯示字元分割矩形框、顯示識別結果、點選最右邊的加號選擇影象二值化:
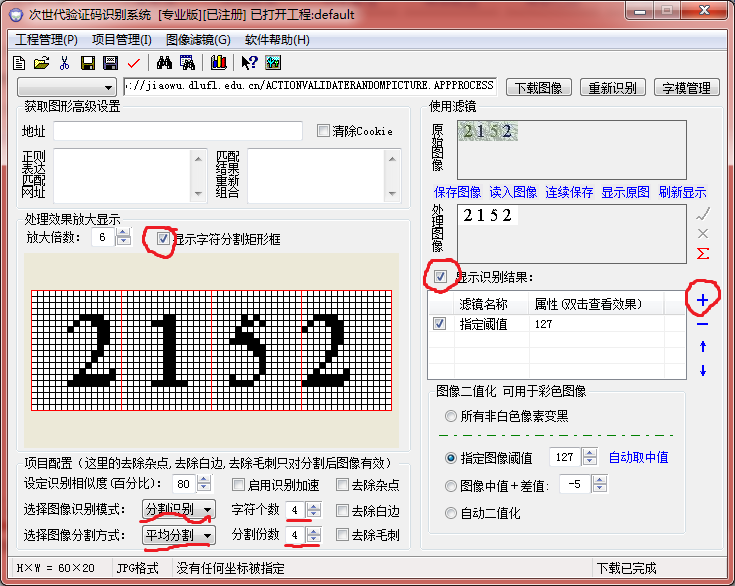
再點選字模管理,選中自動分割影象:
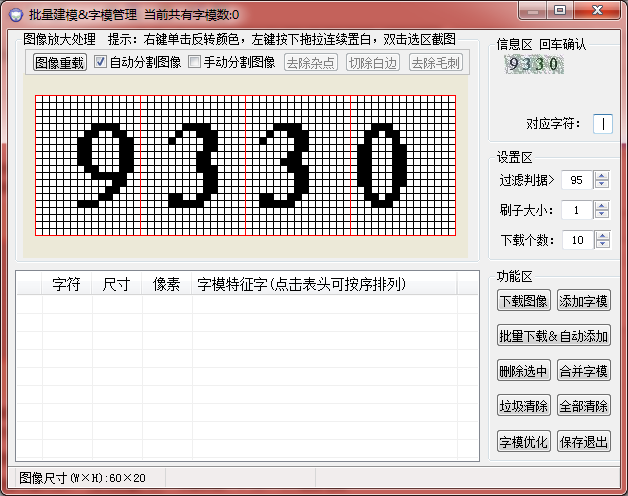
雙擊第一個矩形“9”:
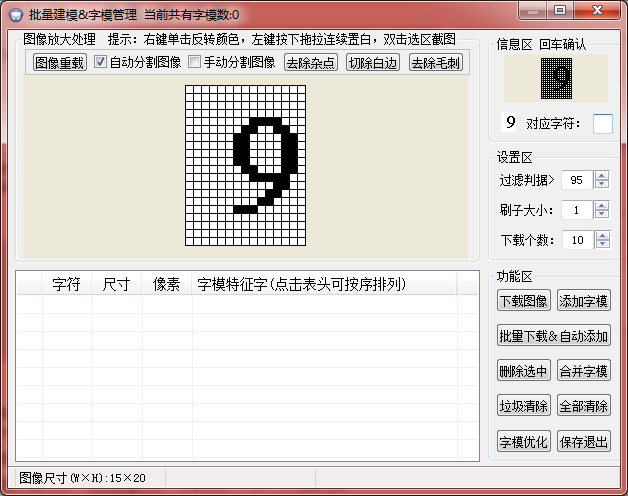
選擇切除白邊(有些雜點多的還要去除雜點),然後在右邊對應字元填下:9,告訴程式,以後遇見這種字元它就是9:
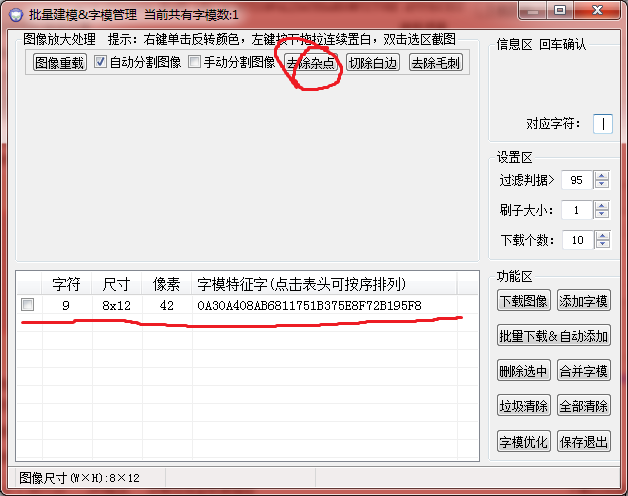
弄完一個後點擊“影象過載”,對第二個矩形3,做同樣的操作:
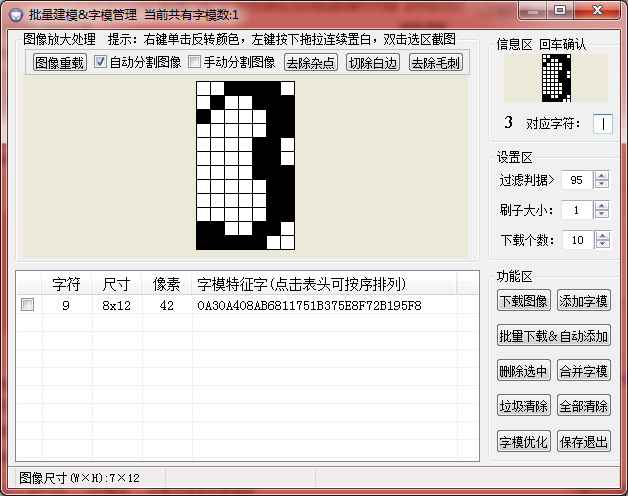
填入3後,我們可以看到已經有兩個字模了,弄完這些就可以儲存退出:
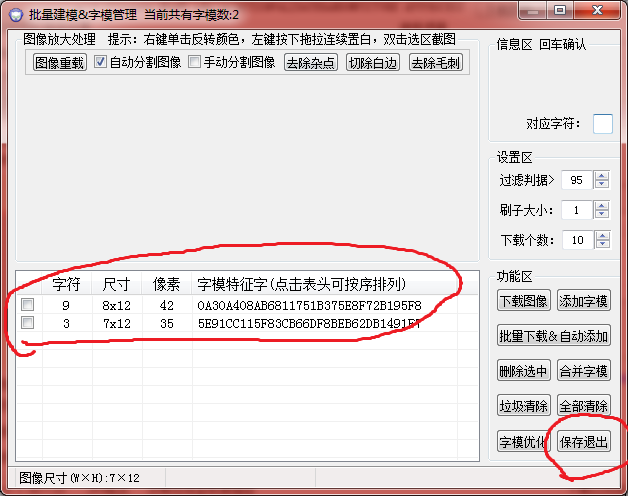
好的回到主介面,我們點選重新識別,可以看到喜人的結果:
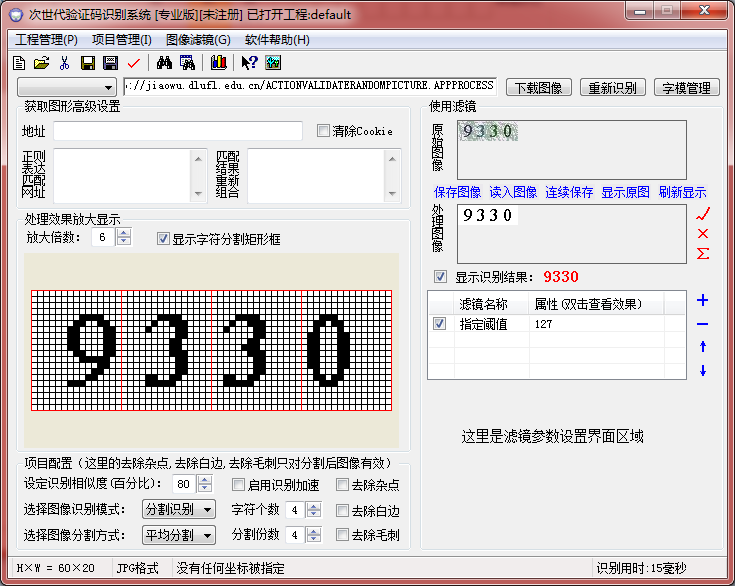
好的,當你識別率很高很高的時候,點選專案管理,釋出識別庫,就能生存可愛的專屬的cds啦,不過正版軟體每次25軟妹幣,你捨得嗎?
吐槽下:
這基本上是我遇到的最最簡單的字模建立了,沒任何雜點,驗證碼超級規整,和我攻克的網站一比較就是被吊打的存在。。
有些難的,2000個字模以下別想識別成功,2k個啊有木有!!
要做足足兩天啊有木有!!!
難怪淘寶特定網站cds售價都是2k,3k軟妹幣啊有木有!!!
不是人幹得的啊有木有!!!
而且你還以為有些網站驗證碼這麼容易獲得嗎?還不是一個個用指令碼去跑的啊有木有!!