
Hive調優(語法與引數層面優化)
一、簡介
作為企業Hadoop應用的核心產品,Hive承載著FaceBook、淘寶等大佬 95%以上的離線統計,很多企業裡的離線統計甚至全由Hive完成,如我所在的電商。Hive在企業雲端計算平臺發揮的作用和影響愈來愈大,如何優化提速已經顯得至關重要。
好的架構勝過任何優化,好的Hql同樣會效率大增,修改Hive引數,有時也能起到很好的效果。
有了瓶頸才需要優化
1、Hadoop的主要效能瓶頸是IO負載,降IO負載是優化的重頭戲。
2、對中間結果的壓縮
3、合理設定分割槽,靜態分割槽和動態分割槽
二、Hive Sql語法層面和Properties引數層面優化
優化方法
合併小檔案
避免資料傾斜,解決資料傾斜
減少job資料(合併job,大job的拆分…)
優化手段
2.1 合理控制Map和Reduce數
(一)map數
1、Map數過大
Map階段輸出檔案太小,產生大量小檔案(下一個階段就需要進行小檔案合併,或者到reduce階段就會浪費很多reduce數)。
初始化和建立map的開銷很大。
2、Map數過小
檔案處理或查詢併發度小,Job執行空間過長。
大量作業時,容易堵塞叢集。
通常情況下,作業會通過input檔案產生一個或者多個map數
主要的決定因素有:input檔案數,input檔案大小。
舉例
a)假設input目錄下有1個檔案a,大小為800M,那麼hadoop會將該檔案a分隔成7個塊(6個128M的塊和1個32M的塊,Block是128M),從而產生7個map數。
b)假設input目錄下有3個檔案a,b,c,大小分別為30M,60M,130M,
那麼hadoop會分隔成4個塊(30M,60M,128M,2M),從而產生4個map數。
拆分是根據大檔案來分的,而map數是根據檔案數來生成的。
解決方法:
兩種方式控制Map數:即減少map數和增加map數
1、減少map數可以通過合併小檔案來實現,這點是對檔案源。
2、增加map數的可以通過控制上一個job的reduce數來控制(一個sql中join多個表會分解為多個mapreduce)
Map對應引數和預設值:
set hive.merge.mapfiles = true;#在Map-only的任務結束時合併小檔案,map階段Hive自動對小檔案合併。
hive> set hive.merge.mapfiles;
hive.merge.mapfiles=true(預設)set hive.merge.mapredfiles = true;#預設false, true時在MapReduce的任務結束時合併小檔案
set hive.merge.per.task = 256*1000*1000;#合併檔案的大小
set mapred.max.split.size = 256000000;#每個Map最大分割大小(hadoop)
set mapred.min.split.size.per.node = l00000000; #一個節點上split的最小值
set hive.input.format =org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;#執行Map前進行小檔案合併
在開啟了org.apache.hadoop.hive.ql.io.CombineHiveInputFormat後,一個datanode節點上多個小檔案會進行合併,合併檔案數大小由 mapred.max.split.size 限制的大小決定。 mapred.min.split.size.per.node 決定了 多個datanode上的檔案 是否需要合併。
Hive中設定map數:引數mapred.map.tasks set mapred.map.tasks=100; (並不是每次都是有效的,要看大小是否合理)
set的作用域是session級
案例環境如下:
hive.merge.mapredfiles=true (預設是false,可以在hive-site.xml裡配置)
hive.merge.mapfiles=true
hive.merge.per.task=256000000
mapred.map.tasks=2(預設值)因為合併小檔案預設為true,而dfs.block.size與hive.merge.per.task的搭配使得合併後的絕大部分檔案都在256MB左右。
Case1:
現在我們假設有3個300MB大小的檔案,整個JOB**會有**6個map.其牛3個map分別處理256M的資料,還有3個map分別處理44M的資料。
那麼木桶效應就來了,整個Job的map階段的執行時間,不是看最短的1個map的執行時間,而是看最長的1個map的執行時間。雖然有3個map分別只處理44MB的資料,可以很快跑完,但它們還是要等待另外3個處理256MB的map。顯然,處理256MB的3個map拖了整個JOB的後腿。
Case2:
如果我們把mapred.map.tasks設定成6,再來看一下變化:
goalsize=min(900M/6,256M)=150M
整個JOB同樣會分配6個Map來處理,每個map處理150MB,非常均勻,誰都不會拖後腿,最合理地分配了資源,執行時間大約為case1的59%(150/256)。
(二)reduce數
1、Reduce數過大
生成了很多個小檔案(最終輸出檔案由reduce決定,一個reduce一個檔案),那麼如果這些小檔案作為下一個Job輸入,則也會出現小檔案過多需要進行合併(耗費資源)的問題。
啟動和初始化reduce也會消耗大量的時間和資源,有多少個reduce就會有多少個輸出檔案。
2、Reduce數過小
每個檔案很大,執行耗時。
可能出現數據領斜。
reduce個數的決定
預設下,Hive分配reduce數基於以下引數:
引數1:hive.exec.reducers.bytes.per.reducer(預設是1G)
引數2:hive.exec.reducers.max(最大reduce數,預設為999)
計算reduce數的公式:
N=min(引數2,總輸入資料量/引數1),
即預設一個reduce處理1G資料量
什麼情況下只有一個reduce?
很多時候你會發現任務中不管資料量多大,不管你有沒有設定調reduce個數的引數,任務中一直都只有一個reduce任務(會產生資料傾斜)。
原因:
1、資料量小於hive.exec.reducers.bytes.per.reducer引數值(有時,通常情況下設定reduce個數會起作用)
2、沒有group by的彙總
3、用了order by
解決:
設定reduce數
引數mapred.reduce.tasks 預設是1 set mapred.reduce.tasks=10
set的作用域是session級
設定reduce數有時對我們優化非常有幫助。
當某個job的結果被後邊job**多次引用**時,設定該引數,以便增大訪問的map數。Reuduce數決定中間結果或落地檔案數,檔案大小和Block大小無關。
2.2 解決資料傾斜
(一) 什麼是資料領斜?
hadoop框架的特性決定最怕資料傾斜。
由於資料分佈不均勻,造成資料大量的集中到一點,造成資料熱點。
症狀:
map階段快,reduce階段非常慢;
某些map很快,某些map很慢;
某些reduce很快,某些reduce奇慢。
如下情況:
A、資料在節點上分佈不均勻(無法避免)。
B、join 時 on 關鍵詞中個別值量很大(如null值)
C、count(distinct),資料量大的情況下,容易資料傾斜,
因為count(distinct)是按group by欄位分組,按distinct欄位排序。(有時無法避免)
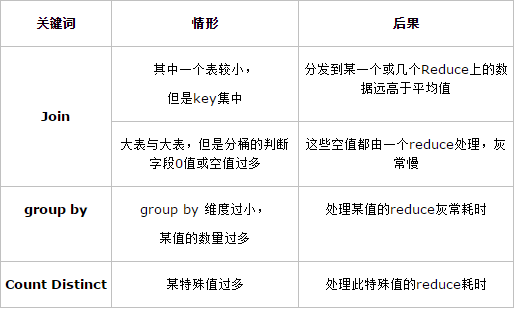
(二)資料傾斜的解決方案
1、引數調節 hive.map.aggr=true
Map 端部分聚合,相當於Combiner
hive.groupby.skewindata=true
有資料傾斜的時候進行負載均衡,當選項設定為true,生成的查詢計劃會有兩個 MR Job。第一個 MR Job 中,Map 的輸出結果集合會隨機分佈到 Reduce 中,每個 Reduce 做部分聚合操作,並輸出結果,這樣處理的結果是相同的 Group By Key 有可能被分發到不同的 Reduce 中,從而達到負載均衡的目的;第二個 MR Job 再根據預處理的資料結果按照 Group By Key 分佈到 Reduce 中(這個過程可以保證相同的 Group By Key 被分佈到同一個 Reduce 中),最後完成最終的聚合操作。
2、SQL語句調節
Join:
關於驅動表的選取:選用join key分佈最均勻的表作為驅動表
做好列裁剪和filter操作,以達到兩表做join的時候,資料量相對變小的效果。
大表與小表Join
使用map join讓小的維度表(1000條以下的記錄條數)先進記憶體。在map端完成reduce。
大表與大表Join:
把空值的key變成一個字串加上隨機數,把傾斜的資料分到不同的reduce上,由於null值關聯不上,處理後並不影響最終結果。
count distinct大量相同特殊值:
count distinct時,將值為空的情況單獨處理,如果是計算count distinct,可以不用處理,直接過濾,在最後結果中加1。如果還有其他計算,需要進行group by,可以先將值為空的記錄單獨處理,再和其他計算結果進行union。
group by維度過小:
採用sum() 與group by的方式來替換count(distinct)完成計算。
特殊情況特殊處理:
在業務邏輯優化效果的不大情況下,有些時候是可以將傾斜的資料單獨拿出來處理,最後union回去。
3、應用場景
(一)空值產生的資料傾斜
場景:
如日誌中,常會有資訊丟失的問題,比如日誌中的user_id,如果取其中的user_id和使用者表中的user_id 關聯,會碰到資料傾斜的問題。
解決方法1: user_id為空的不參與關聯
select * from log a
join users b
on a.user_id is not null
and a.user_id = b.user_id
union all
select * from log a
where a.user_id is null;解決方法2 :賦與空值新的key值
select * from log a left outer join users b on case when a.user_id is null then concat('hive',rand() )
else a.user_id end = b.user_id;結論:
方法2比方法1效率更好,不但io少了,而且作業數也少了。
解決方法1中 log讀取兩次,job是2。
解決方法2中 job數是1 。這個優化適合無效 id (比如 -99 , ”, null 等) 產生的傾斜問題。把空值的key變成一個字串加上隨機數,就能把傾斜的資料分到不同的reduce上,解決資料傾斜問題。
(二)不同資料型別關聯產生資料傾斜
場景:使用者表中user_id欄位為int,log表中user_id欄位既有string型別也有int型別。當按照user_id進行兩個表的Join操作時,預設的Hash操作會按int型的id來進行分配,這樣會導致所有string型別id的記錄都分配到一個Reducer中。
解決方法:把數字型別轉換成字串型別
select * from users a
left outer join logs b
on a.usr_id = cast(b.user_id as string);(三)小表不小不大,怎麼用 map join 解決傾斜問題
使用 map join 解決小表(記錄數少)關聯大表的資料傾斜問題,這個方法使用的頻率非常高,但如果小表很大,大到map join會出現bug或異常,這時就需要特別的處理。
解決如下:
select * from log a
left outer join users b
on a.user_id = b.user_id;users 表有 600w+ 的記錄,把 users 分發到所有的 map 上也是個不小的開銷,而且 map join 不支援這麼大的小表。如果用普通的 join,又會碰到資料傾斜的問題。
解決方法:
select /*+mapjoin(x)*/* from log a
left outer join (
select /*+mapjoin(c)*/d.*
from ( select distinct user_id from log ) c
join users d
on c.user_id = d.user_id
) x
on a.user_id = b.user_id;假如,log裡user_id有上百萬個,這就又回到原來map join問題。所幸,每日的會員uv不會太多,有交易的會員不會太多,有點選的會員不會太多,有佣金的會員不會太多等等。所以這個方法能解決很多場景下的資料傾斜問題。