
Hadoop2.6.0安裝 — 叢集
這裡寫點 Hadoop2.6.0叢集的安裝和簡單配置,一方面是為自己學習的過程做以記錄,另一方面希望也能幫助到和LZ一樣的Hadoop初學者,去搭建自己的學習和練習操作環境,後期的 MapReduce 開發環境的配置和 MapReduce 程式開發會慢慢更新出來,LZ也是邊學習邊記錄更新部落格,路人如有問題歡迎提出來一起探討解決,不足的地方希望路人多指教,共勉!
目錄
本文主要詳述配置 Hadoop 叢集,預設路人已經掌握了 Hadoop 單機/偽分散式的配置,否則請查閱
環境準備
環境的準備和上篇(Hadoop2.6.0安裝 — 單機/偽分佈)的環境一致,因為LZ也是在一臺電腦上搞的虛擬機器學習的,Virtual Box虛擬機器下Ubuntu14.04 64位系統,Hadoop版本就不用再囉嗦了吧,題目上寫清楚了。此處叢集包含了3個節點(機器),其中一個做 Master 節點(NameNode),其他兩臺機器作為 Slave 節點(DataNode)。
OK,既然叢集有三個節點,需要先將三個虛擬環境準備好,才能開始叢集的配置,整個流程如下:
- 三臺機器都準備好 Linux 環境,分別配置 hadoop 使用者,安裝 SSH server、配置 Java 環境;
- 確定一臺機器作為 Master 節點(虛擬環境隨便指定一個都行啦,但生產環境可要用最牛逼的機器來做哈,畢竟 Master 躺了比較麻煩);
- 在確定的 Master 節點上安裝 Hadoop,並完成叢集配置;
- 將 Master 節點上 Hadoop 的安裝目錄直接 copy 到所有的 Salve 節點即可;
- 在 Master 節點啟動叢集。
VirtualBox需要為三臺機器配置網路,以保證叢集中的所有節點之間可以互相通訊,需要更改網路連線方式為橋接(Bridge)模式,才能實現虛擬機器之間的網路互聯,同時需要確保各節點之間的Mac地址不同。VirtualBox虛擬機器幾種網路連線方式的異同可以去這裡檢視。
為方便區分各個節點,可以去修改下各個節點的主機名(直接改為你能夠辨識的主機名)。
1 $sudo vim /etc/hostname

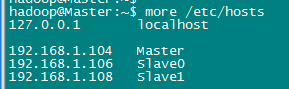
此處使用了一個Master節點,兩個Slave節點,需要在hosts檔案中新增上節點的與IP的對映關係(所有節點都需要修改,節點直接用SSH直接連線的時候可以直接使用主機名連線)。
1 $sudo vi /etc/hosts
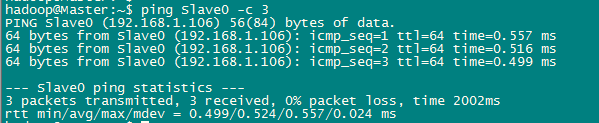
測試網路連線。所有節點之間的連線都需要逐個測試,以保證所有節點直接能夠互聯互通。
1 $ping Slave0 -c 3
配置SSH登陸
這個操作是要讓 Master 節點可以無密碼 SSH 登陸到各個 Slave 節點上。
首先生成 Master 節點的公匙,在 Master 節點的終端中執行(因為改過主機名,所以還需要刪掉原有的再重新生成一次):
$cd ~/.ssh # 如果沒有該目錄,先執行一次ssh localhost,生成.ssh目錄 $rm ./id_rsa* # 刪除之前生成的公匙(如果有) $ssh-keygen -t rsa # 一直按回車就可以 $cat ./id_rsa.pub >> ./authorized_keys
在 Master 節點將上公匙傳輸到 Slave0 和 Slave1 節點:
$scp ~/.ssh/id_rsa.pub [email protected]:/home/hadoop/ $scp ~/.ssh/id_rsa.pub [email protected]:/home/hadoop/
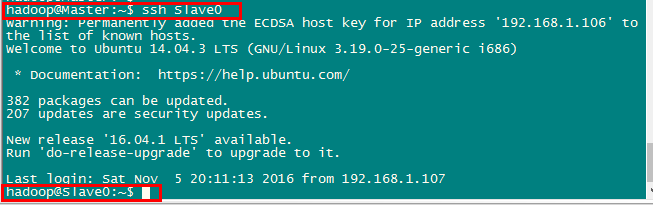
將Master節點的公鑰傳輸到Slave節點後,需要分別在兩個節點上將Master節點傳輸過來的公鑰加入授權。這樣,在 Master 節點上就可以無密碼 SSH 到各個 Slave 節點了,可在 Master 節點上執行如下命令進行檢驗,如下圖所示:
配置環境變數
配置好 Hadoop 相關的所有環境變數,具體配置在這裡,同樣如果為了方便操作 DataNode,可以將 Slave 節點上Hadoop安裝目錄下的 /sbin 和 /bin 都新增到 $PATH 環境變數中。
配置叢集/分散式
叢集/分散式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5個配置檔案,更多設定項可點選檢視官方說明,這裡僅設定了正常啟動所必須的設定項: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。(比偽分佈多了一個slaves檔案)
1. slaves檔案,將作為 DataNode 的主機名寫入該檔案,每行一個,預設為 localhost,所以在偽分散式配置時,節點即作為 NameNode 也作為 DataNode。分散式配置可以保留 localhost,也可以刪掉,讓 Master 節點僅作為 NameNode 使用。LZ直接將 Slave0 和 Slave1 都加入其中。
2. core-site.xml(此處需要主義 fs.defaultFS 屬性,LZ在用window上的eclipse配置開發環境的時候一直配置不成功,但將 Master 改為具體IP地址之後沒問題,這裡將在開發環境配置的時候詳述)

1 <configuration> 2 <property> 3 <name>fs.defaultFS</name> 4 <value>hdfs://Master:9000</value> 5 </property> 6 <property> 7 <name>hadoop.tmp.dir</name> 8 <value>file:/usr/local/hadoop/tmp</value> 9 <description>Abase for other temporary directories.</description> 10 </property> 11 </configuration>
3. hdfs-site.xml,dfs.replication 一般設為 3,但我們只有兩個 Slave 節點,所以 dfs.replication 的值還是設為 2:
1 <configuration> 2 <property> 3 <name>dfs.namenode.secondary.http-address</name> 4 <value>Master:50090</value> 5 </property> 6 <property> 7 <name>dfs.replication</name> 8 <value>1</value> 9 </property> 10 <property> 11 <name>dfs.namenode.name.dir</name> 12 <value>file:/usr/local/hadoop/tmp/dfs/name</value> 13 </property> 14 <property> 15 <name>dfs.datanode.data.dir</name> 16 <value>file:/usr/local/hadoop/tmp/dfs/data</value> 17 </property> 18 </configuration>
4. mapred-site.xml(需要先重新命名,預設檔名為 mapred-site.xml.template,因為預設情況只配置HDFS),然後配置修改如下:
1 <configuration> 2 <property> 3 <name>mapreduce.framework.name</name> 4 <value>yarn</value> 5 </property> 6 <property> 7 <name>mapreduce.jobhistory.address</name> 8 <value>Master:10020</value> 9 </property> 10 <property> 11 <name>mapreduce.jobhistory.webapp.address</name> 12 <value>Master:19888</value> 13 </property> 14 </configuration>
5. yarn-site.xml
1 <configuration> 2 <property> 3 <name>yarn.resourcemanager.hostname</name> 4 <value>Master</value> 5 </property> 6 <property> 7 <name>yarn.nodemanager.aux-services</name> 8 <value>mapreduce_shuffle</value> 9 </property> 10 </configuration>
配置好後,將 Master 上的 /usr/local/hadoop 資料夾複製到各個節點上。
注:如果之前在Master節點上啟動過Hadoop,需要在copy之前先刪除hadoop目錄下的 tmp 檔案和 logs下的檔案。在 Master 節點上執行:
1 $cd /usr/local 2 $sudo rm -r ./hadoop/tmp # 刪除 Hadoop 臨時檔案 3 $sudo rm -r ./hadoop/logs/* # 刪除日誌檔案 4 $tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先壓縮再複製 5 $cd ~ 6 $scp ./hadoop.master.tar.gz Slave0:/home/hadoop
copy結束後,在Slave0和Slave1節點上直接將copy過來的目錄解壓即可(Master節點需要和Slave節點有相同的配置)。
1 $sudo rm -r /usr/local/hadoop # 刪掉舊的(如果存在) 2 $sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local 3 $sudo chown -R hadoop /usr/local/hadoop
啟動叢集/分散式
首次啟動需要先在 Master 節點執行 NameNode 的格式化,之後的啟動不需要再去進行:
1 $hdfs namenode -format
逐個啟動所有守護程序,並在各個節點通過jps檢視所有守護程序啟動情況。
1 $start-dfs.sh 2 $start-yarn.sh 3 $mr-jobhistory-daemon.sh start historyserve
Master節點

Slave0節點
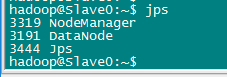
Slave節點
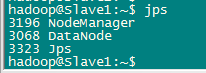
要確保所有的守護程序都能夠正常啟動。另外還需要在 Master 節點上通過命令 hdfs dfsadmin -report 檢視 DataNode 是否正常啟動,如果 Live datanodes 不為 0 ,則說明叢集啟動成功。例如我這邊一共有 2 個 Datanodes:

關閉叢集同樣也是在Master節點上執行
1 $stop-yarn.sh 2 $stop-dfs.sh 3 $mr-jobhistory-daemon.sh stop historyserver