
spark叢集搭建(Hadoop、Scala)
1.從官網下載hadoop、spark、scala
我的版本:
hadoop-2.7.3.tar.gz
scala-2.11.8.tgz
spark-2.1.0-bin-hadoop2.7.tgz
(注意:spark版本要與scala 版本相互對應)
2.配置host檔案
vim/etc/hosts
加入引數(域名加主機名字)

10.20.30.91 wx-k5-30-9110.20.30.92 wx-k5-30-9210.20.30.94 wx-k5-30-94
3.增加使用者

groupadd hadoop 新增一個組useradd hadoop -g hadoop 新增使用者su hadoop //切換到hadoop使用者中

4.配置SSH免密碼連入
4.1 輸入命令,產生公匙,密匙
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
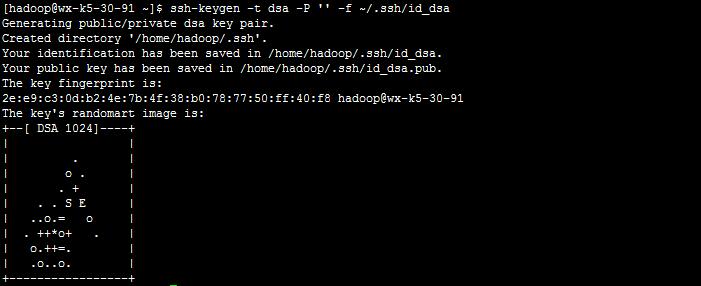
4.2 產生在使用者下的 .ssh目錄下面
Id_rsa.pub為公鑰,id_rsa為私鑰,緊接著將公鑰檔案複製成authorized_keys檔案
cd .ssh/
cp id_rsa.pub authorized_keys

原理:
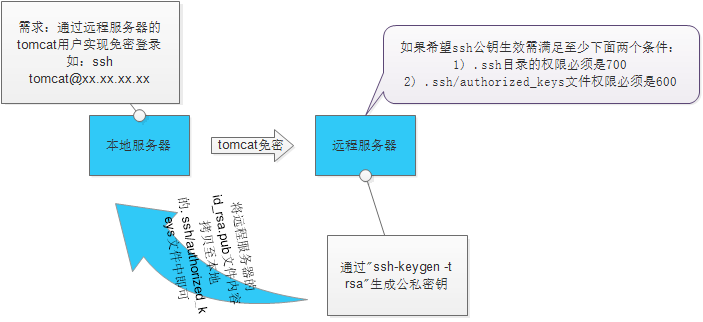
與之相反,將本地的id_rsa.pub內容拷貝到遠端伺服器的authorized_keys中
在10.20.30.91 上訪問10.20.30.92 無密登入,第一次登入按提示輸入yes
ssh 10.20.30.9
5.安裝hadoop
5.1 解壓安裝包
tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz
tar -zxvf hadoop-2.7.3 hadoop.tar.gz
tar -zxvf scala-2.11.8 scala.tgzln -s spark-2.1.0-bin-hadoop2.7 spark
ln -s hadoop-2.7.3 hadoop
ln -s scala-2.11.8 scala
5.3 配置環境變數
vim /etc/profile
export HADOOP_HOME=/opt/sparkgroup/hadoop export SCALA_HOME=/opt/sparkgroup/scala export SPARK_HOME=/opt/sparkgroup/spark export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin::$HADOOP_HOME/bin:$HADOOP_HOME/sbin export JAVA_HOME=/opt/jdk1.7.0_75 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

使配置生效
source /etc/profile5.4配置hadoop
cd $HADOOP_HOME/etc/hadoop
vim slaves將slave的主機名加入,每行一個主機名

vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://wx-k5-30-91:8020</value>
<description>The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.
</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>360</value>
<description>Number of minutes between trash checkpoints.If zero, the trash feature is disabled.
</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/sparkgroup/hadoop/tmp_${user.name}</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description> 每一個檔案的每一個切塊,在hdfs叢集中都可以儲存多個備份(預設3份),在hdfs-site.xml中,dfs.replication的value的數量就是備份的數量. </description>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/sparkgroup/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/sparkgroup/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>wx-k5-30-91</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>建立對應的目錄
mkdir -p /opt/sparkgroup/hadoop/hdfs/{data,name}
mkdir /opt/sparkgroup/hadoop/tmp配置hadoop-env.sh
vim hadoop-env.sh加入:
export JAVA_HOME=/opt/jdk1.7.0_75hadoop namenode -format
如圖中的status為0,說明初始化成功,若為1,則失敗
啟動hadoop:
$HADOOP_HOME/sbin/start-all.sh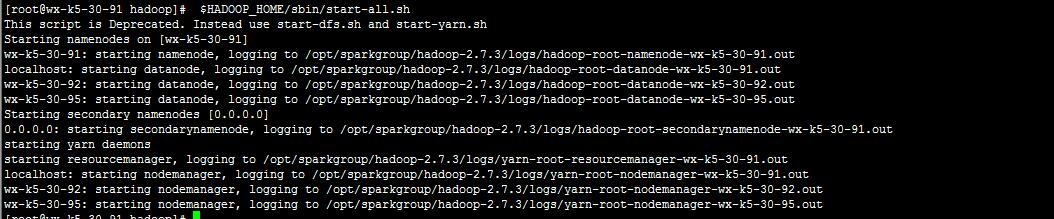
三個伺服器全部啟動
這裡可能出現一個錯誤:
這個錯誤解決辦法:
(1).系統位數不一樣,centos 是32位,你安裝hadoop為64位
用ldd命令檢視依賴庫
ldd libhadoop.so.1.0.0
(2).替換hadoop目錄下 lib/native/ 下的檔案
下載hadoop-native-64-2.7.0.tar
http://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.7.0.tar
下載完以後,解壓到hadoop的native目錄下,覆蓋原有檔案即可。操作如下:

tar -x hadoop-native-64-2.4.0.tar -C hadoop/lib/native/
(3).glibc庫是2.12版本,而hadoop期望是2.14版本,所以列印警告資訊
檢視glibc版本
ldd --version
(4).直接在log4j日誌中去除告警資訊。在/opt/sparkgroup/hadoop/etc/hadoop/log4j.properties檔案中新增
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
使用jps命令檢視程序
jps -l
在master
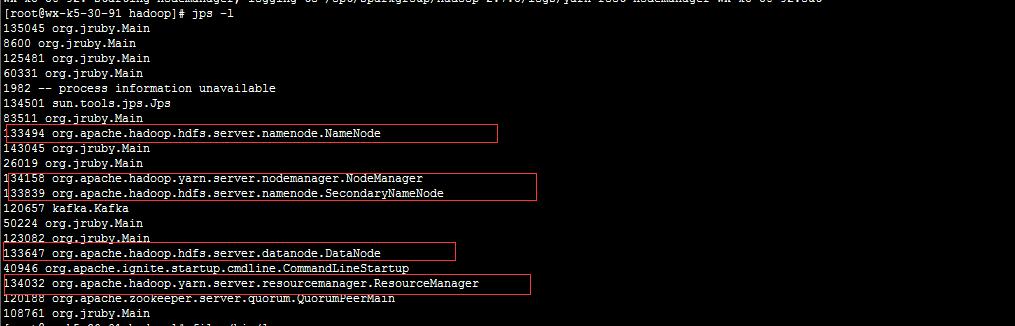
在 slaves

注意:
初次使用Hadoop,執行後怎麼沒有NameNode節點?
解決方法:
1、先執行stop-all.sh
2、格式化namdenode,不過在這之前要先刪除原目錄,即core-site.xml下配置的<name>hadoop.tmp.dir</name>所指向的目錄,刪除後切記要重新建立配置的空目錄,然後執行hadoop namenode -form
在叢集中每一臺機器都要一樣配置
在此hadoop叢集已經配置完畢
6. 配置scala
之前已經將scala 包解壓並且配置了環境變數 scala 也配置完成
scala -version
可以看到Scala版本

7.安裝spark
上面已經將環境變數配好在這裡直接配置spark
cd $SPARK_HOME/confcp spark-env.sh.template spark-env.sh
cp slaves.template slaves
vim slaves
加入叢集伺服器ip或者主機名
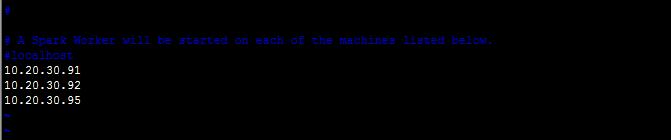
vim spark-env.sh 加入
export JAVA_HOME=/opt/jdk1.7.0_75
export SCALA_HOME=/opt/sparkgroup/scala
export SPARK_MASTER_IP=10.20.30.91
export SPARK_LOCAL_IP=10.20.30.91
export SPARK_WORKER_MEMORY=2g
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
圈住部分注意:叢集中每臺機器寫各自的 local_ip
SPARK_MASTER_IP=10.20.30.91
這個叢集中的每一臺都寫master的ip
配置spark-defaults.conf,該檔案為spark提交任務時預設讀取的配置檔案
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/sparkHistoryLogs
spark.eventLog.compress true
spark.history.updateInterval 5
spark.history.ui.port 7777
spark.history.fs.logDirectory hdfs://master:9000/sparkHistoryLogs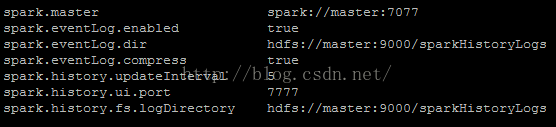
啟動Spark程序:
$SPARK_HOME/sbin/start-all.sh

jps 檢視程序
jps
master:
slaves
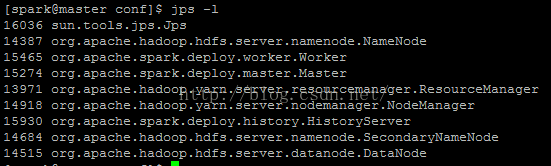
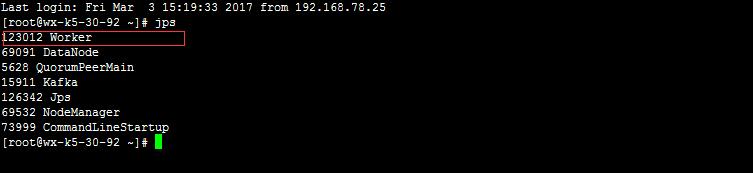
至此 spark 環境全部配置完成
執行shell 並測試
$SPARK_HOME/bin/spark-shell --master spark://master:707
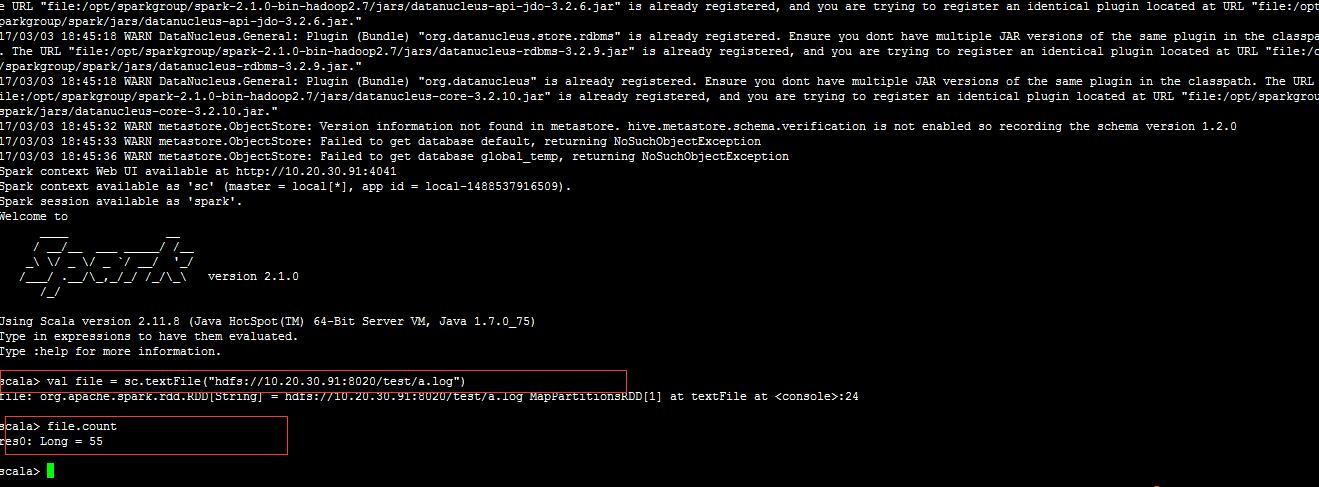
在瀏覽器中輸入:10.20.30.91:8020 就可以訪問了, 沒錯的的話會顯示三臺worker
adoop 叢集資訊:
10.20.30.91:50070
10.20.30.91:8088
注意:zeppelin教程連結:http://blog.csdn.net/qq_28767763/article/details/54409245
附錄:
部分hdfs命令:
hdfs命令
1、建立test資料夾
hadoop fs -mk /test
bin/hdfs dfs -mkdir /test
2、檢視資料夾
hadoop fs -ls /test
3、刪除資料夾 rmr 刪除檔案rm
4、檢視磁碟空間
bin/hdfs dfs -df -h /
5、檢視檔案尾部
bin/hdfs dfs -tail
6、直接存取檔案
存檔案:
./hdfs dfs -put /home/admin1/桌面/test.txt hdfs://localhost:9000/
取檔案:
./hdfs dfs -get hdfs://localhost:9000/test.txt
7、顯示檔案內容
hadoop fs -cat /hello.txt
8、從本地檔案系統中拷貝檔案到hdfs路徑去
hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
9、從hdfs拷貝到本地
hadoop fs -copyToLocal /aaa/jdk.tar.gz
具體安裝jdk教程
1. 修改/etc/profile檔案
如果你的計算機僅僅作為開發使用時推薦使用這種方法,因為所有使用者的shell都有權使用這些環境變數,可能會給系統帶來安全性問題。
·用文字編輯器開啟/etc/profile
·在profile檔案末尾加入:
export JAVA_HOME=/usr/share/jdk1.6.0_14
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
a. 你要將 /usr/share/jdk1.6.0_14改為你的jdk安裝目錄
b. linux下用冒號“:”來分隔路徑
c. $PATH / $CLASSPATH / $JAVA_HOME 是用來引用原來的環境變數的值
在設定環境變數時特別要注意不能把原來的值給覆蓋掉了,這是一種
常見的錯誤。
d. CLASSPATH中當前目錄“.”不能丟,把當前目錄丟掉也是常見的錯誤。
e. export是把這三個變數匯出為全域性變數。
f. 大小寫必須嚴格區分。
2. 修改.bash_profile檔案
這種方法更為安全,它可以把使用這些環境變數的許可權控制到使用者級別,如果你需要給某個使用者許可權使用這些環境變數,你只需要修改其個人使用者主目錄下的.bash_profile檔案就可以了。
·用文字編輯器開啟使用者目錄下的.bash_profile檔案
·在.bash_profile檔案末尾加入:
export JAVA_HOME=/usr/share/jdk1.6.0_14
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
·重新登入
3. 直接在shell下設定變數
不贊成使用這種方法,因為換個shell,你的設定就無效了,因此這種方法僅僅是臨時使用,以後要使用的時候又要重新設定,比較麻煩。
只需在shell終端執行下列命令:
export JAVA_HOME=/usr/share/jdk1.6.0_14
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
參考連結:
hadoop:
http://blog.csdn.net/dai451954706/article/details/46966165
http://www.linuxidc.com/Linux/2015-08/120947.htm
jdk: http://www.cnblogs.com/samcn/archive/2011/03/16/1986248.html