
遊戲伺服器需要什麼樣的引擎?
彈指一揮間從事遊戲相關的開發工作已經十多年。在開發了六年多幾經波折差點放棄的
starrydb.com專案也迎來了1.0版本的上線。雖然演示版本以及叢集功能早在17年1月份就
開發完畢但修改和完善計劃目前仍然排的滿滿當當,導致1.0上線一推再推至今仍然不甚滿
意。
說起最初開發這個專案的初衷就像那盞迷霧中的綠光讓人興奮不已,在此也希望因為我
的執著而被傷害的人幸福。以下引至《thegreat gatsby》
“Gatsby believed in the green light, the orgastic future that year byyear
recedes before us.It eluded us then, but that's no matter--tomorrow we will run
faster, stretch outour arms farther.... And one fine morning---- So we beat on,
boats against thecurrent, borne back ceaselessly into the past.”
或許人們還沒有意識到,遊戲伺服器將是繼計算機作業系統之後,現代軟體工程中最復
雜的計算系統。經過wow和無數遊戲公司的崛起讓這個系統得到了飛速發展。最初的遊戲服
務器引擎可以追述到1992年的mudos。這是一個簡單的文字對話系統,但可以多人線上。
因為互動簡單對效能要求不高,普通的伺服器就可以支援上千人同時線上。在接下來的很多
年時間內,mudos代表著遊戲伺服器引擎的經典原形。我們可以把這類伺服器引擎統稱為經
典遊戲伺服器引擎。
經典的遊戲伺服器引擎的核心構建就邏輯伺服器,所謂邏輯伺服器就是對使用者的輸入數
據進行處理,產生輸出資料返回給使用者。見圖1
因為遊戲邏輯伺服器的崩潰問題和記憶體使用量不穩定,出現伺服器不穩定進而導致資料
丟失。伺服器急需一個穩定的硬碟儲存服務。Mysql出現在了邏輯伺服器後面替代邏輯服務
器的硬碟。見下圖2

因為mysql資料庫寫入和讀取得速度不快,資料操作需要等待時間的過長,在硬碟資料
庫之前又加入了記憶體資料庫作為快速讀取的快取伺服器。
也許你看出了其中的問題,為了解決邏輯伺服器不穩定丟失資料的問題,引入了快取服
務器和資料儲存伺服器,但增加了系統的複雜性,導致開發難度增加進而導致邏輯伺服器更
加複雜更加容易崩潰。人們花了很長的時間和想了很多的辦法提高邏輯伺服器的穩定性。見
下圖3

因為伺服器崩潰的主要原因是記憶體指標的洩漏,為了解決崩潰的問題產生了各種指令碼語
言替代指標型語言。可伺服器功能越來越多,越來越複雜,崩潰,卡死,記憶體洩漏像邏輯
伺服器上空的陰雲揮之不去。
伺服器第一要求是穩定,但仍然不能阻止人們對伺服器功能無盡的渴求。於是產生了新
的想法拆分邏輯伺服器擴充套件伺服器承載能力。見下圖4

到這裡經典遊戲伺服器發展到了巔峰,其資料處理的複雜度遠高於同期的任何伺服器系
統。
為何說其處理資料的複雜度高於同期的任何伺服器系統,因為同期的伺服器系統都是服
務於現實生活,而遊戲伺服器是服務於純粹的虛擬世界。例如說郵寄物品這個事情,在遊戲
伺服器就是一個指令,也許在聊天過程,也許在戰鬥過程。沒有現實中郵寄的等待過程,需
要遊戲伺服器立刻就返回。並且可以發生在任何功能伺服器上。例如聊天的過程中給對方一
個物品,這在現實中是絕對不可能發生的。
因為功能和功能之間不是絕對的獨立,經典的伺服器系統隨著功能的劃分越來越細,每
個伺服器之間的通訊就越來越複雜。這樣讓人聯想到了複雜低效的官僚系統。有大量的請求
都浪費在了通訊和複雜的溝通上,而且每個開發人員要小心奕奕,不知道哪個邏輯會搭錯崩
潰掉。
在六年前的一個夜晚,看著眼前這越來越龐大複雜的怪獸,我像極了唐吉坷德向著風車
揮舞著長矛。在某一瞬間一個想法進入大腦,為什麼不能一個伺服器就把一個玩家的所有請
求都處理好呢?這樣就像給每個玩家配備了一個專職的祕書,任何需求都交給祕書去做,涉
及和其他玩家溝通的事情,祕書會找到其他玩家的祕書進行溝通。見下圖5
到這裡經典遊戲伺服器發展到了巔峰,其資料處理的複雜度遠高於同期的任何伺服器系
統。
為何說其處理資料的複雜度高於同期的任何伺服器系統,因為同期的伺服器系統都是服
務於現實生活,而遊戲伺服器是服務於純粹的虛擬世界。例如說郵寄物品這個事情,在遊戲
伺服器就是一個指令,也許在聊天過程,也許在戰鬥過程。沒有現實中郵寄的等待過程,需
要遊戲伺服器立刻就返回。並且可以發生在任何功能伺服器上。例如聊天的過程中給對方一
個物品,這在現實中是絕對不可能發生的。
因為功能和功能之間不是絕對的獨立,經典的伺服器系統隨著功能的劃分越來越細,每
個伺服器之間的通訊就越來越複雜。這樣讓人聯想到了複雜低效的官僚系統。有大量的請求
都浪費在了通訊和複雜的溝通上,而且每個開發人員要小心奕奕,不知道哪個邏輯會搭錯崩
潰掉。
在六年前的一個夜晚,看著眼前這越來越龐大複雜的怪獸,我像極了唐吉坷德向著風車
揮舞著長矛。在某一瞬間一個想法進入大腦,為什麼不能一個伺服器就把一個玩家的所有請
求都處理好呢?這樣就像給每個玩家配備了一個專職的祕書,任何需求都交給祕書去做,涉
及和其他玩家溝通的事情,祕書會找到其他玩家的祕書進行溝通。見下圖5
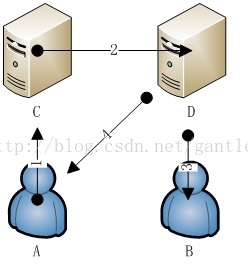
以購買物品為例
1, 玩家A向伺服器C傳送購買物品的請求,伺服器C扣除玩家A的貨幣;
2, 伺服器C將購買的請求傳送給伺服器D;
3, 伺服器D扣除玩家B的物品並新增貨幣並返回結果給玩家B;
4, 返回交易結果給玩A;
這個設計模式稱為“one objectdo something”,這個設計模式第一個好處就是降低了軟體開發的難度。在按功能分割的伺服器中,每個伺服器上都是不同功能的程式碼。每個功能之間的聯絡是一種耦合關係。存在耦合關係的程式碼就存在不確定性的風險,每個功能看似單獨修改都沒有問題,但在一起互相配合就會出現各種不確定性。Starrydb的“one object do something”的模式中伺服器C和伺服器D使用程式碼是一樣的。這種買賣關係無論是A向B購買還是B向A購買過程都是一樣的。這樣高內聚的工程在開發除錯的過程中不容易出現錯誤。提高了開發速度和軟體質量,降低了軟體工程的不確定性。
Starrydb的“one objectdo something”的模式的另一個好處就是極大的方便伺服器的擴充套件。因為每個伺服器的配置都是一樣的,當用戶增加的時候只要新增新的伺服器,就可以滿足資料處理的需求。傳統的經典伺服器架構,按功能劃分伺服器結構的方式就會出現瓶頸,功能不能一直不斷細分。見下圖6
人類是社會動物,我們每個人都維繫的著自己的社交圈子。每個星期給媽媽打電話,每年一次的家族聚會,晚上去酒吧認識新朋友,和老朋友去海邊度假,在公司與客戶談判等等。如今社交的方式更是多種多樣,通過網路和視訊連結,我們更可以不受地域的限制。對於我們每個人來說,社交可以用如下幾個方面來度量,聯絡人的總數量,每人的總次數,每次的時長,這三方面的乘積得到我們社交所投入總時間。假設我們在單位時間內投入的熱情不變。那麼我們在一定時間內投入到社交活動的熱情是,人數*次數*時長*熱情。
遊戲伺服器引擎也是一個小的虛擬社會,每個玩家都是這個社會的一份子。分散式的遊戲伺服器引擎的物件的效能也可以套用這個公式。某個物件訪問其他物件(或被其他物件訪問)的物件數量,每個物件的訪問次數,每次訪問的時常和cpu單位時間的運算能力。就可以推算出這個物件在叢集中消耗的cpu運算能力。如果再乘以這個物件平均佔用的記憶體數量就可以推算出一個物件在叢集中總的消耗。
假定伺服器每次處理的時長非常小並較為平均,cpu單位時間的運算能力也相對固定。那麼每個物件的與其它物件的通訊次數和通訊物件的數量就成為決定服務叢集承載能力的關鍵。
在不限制物件間通訊的範圍和每個物件通訊的次數的極端情況下叢集承載。伺服器內玩家的數量為x,假設每個玩家都和剩餘的所有玩家有社交關係,那麼伺服器每秒鐘處理的訊息數量為x²。假設伺服器處理訊息數量的上限為n,那麼需要的伺服器數量y=x²/n,承載的人數x=√(ny)。見下圖7:

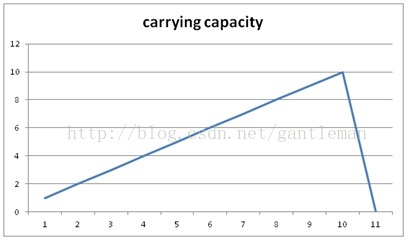
限制使用者社交頻率的情況下承載能力與cpu數量成正相關,直到到達單個cpu處理上
限。假設單個cpu處理上限是10人,伺服器到10之後處理能力會陡然下降出現拒絕服務。
見下圖8:
在對每個使用者的單位時間內的社交關係上限和頻率做適當的限制之後系統承載可以隨
著cpu的增加無限擴充套件下去。見下圖9:

在經典的遊戲伺服器引擎中,按功能劃分的模組分別執行在不同的伺服器上。這雖然也
可以稱呼為分散式,但我們知道拆分不同功能到不同的硬體上執行,需要對原有軟體系統進
行很大的改動。這種擴充套件不是線性的而是階梯性的。見下圖10:
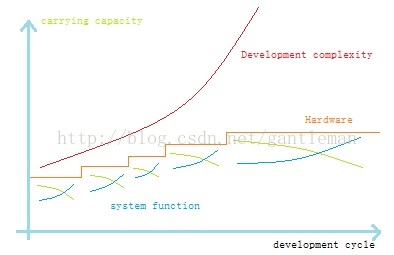
系統承載能力的上限是硬體限制,隨著系統功能的增加承載能力逐步下降。但每次提高
硬體上限就是拆分功能,都會讓承載能力得到提高。隨著硬體數量越來越多開發複雜度也越
來越高。
“Donot , for one repulse , give up the purpose that you resolved to
effect .(WilliamShakespeare , British dramatist)”
我們看到想要通過新增伺服器達到無限擴充套件必須要遵循基本的數學準則。限制單位時間
處理的人數或者減少資料交換的頻次。這個結果雖然讓人沮喪,但從另一個方面也讓我們
看到分散式伺服器無限擴充套件的可能性。到這裡我們有了一個評價遊戲伺服器引擎的數學標準。
那麼只要遵循這個標準寫出一個穩定,高效能,可擴充套件的遊戲伺服器引擎就成為可能。
見下圖11:
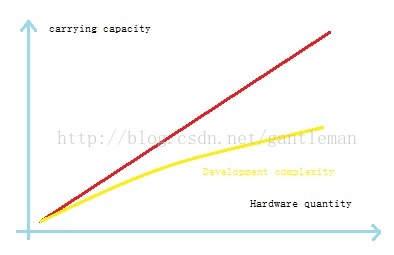
理想的遊戲伺服器引擎的承載能力和硬體效能成正相關,開發難度趨於平行。要達到這
樣理想的狀態,降低開發複雜度需要在三個層次上的保證。從下到上分別是穩定,高效能,
可擴充套件。見下圖12

穩定是遊戲伺服器引擎的基石。這個穩定的含義也是儘可能的減少耦合性,讓計算執行
在最簡單可靠的環境內。只有儘可能把資料的計算儲存都放在同一臺計算機上。減少每個計
算機節點間的資料交換。用最快的時間處理完每條資料請求。這就是資料和計算越近效率越
高系統越穩定。經典的遊戲伺服器引擎的資料被儲存有三份。邏輯伺服器一份,資料快取一
份,硬碟資料庫一份。在系統執行過程中確認資料一致性和完整性的工作就消耗了大半。而
且出現斷線和宕機,很容易破壞資料的一致性和完整性。是潛在破壞伺服器穩定性的因素。
高效能是伺服器穩定之後追求的第二個目標。為了無限的接近硬體處理的上限,不浪費
硬體資源。這似乎和分散式系統是相互矛盾的,因為分散式系統就是要把資料和任務分配給
叢集內的每臺伺服器,分配的過程必然帶來損耗。但也不能轉頭把高效能寄託在優化開發庫
上。因為我們知道伺服器受限於cpu的處理能力。開發庫中新增功能就會影響軟體執行效率,
開發庫分割功能就會增加資料複製成本。減少軟體開發難度的根本還是加強內聚減少耦合,
減少工程的複雜度。
擴充套件性是遊戲伺服器引擎追求的最高目標,雖然數學準則告訴我們這樣的追求對於分佈
式系統有限制。但建立線上人數和功能的擴充套件與伺服器硬體數量的線性關係還是非常的必要。
經典的遊戲伺服器引擎對地圖伺服器的擴充套件不能準確地稱為建立了線性關係。因為玩家未必
會按開發者的意願平均分配到每臺地圖伺服器上。
在一個如此龐大的系統裡對於資料的安全性又是如何保障的呢?見下圖13

能保障資料安全的並不是starrydb,starrydb只是一個系統功能的實現,對於資料安全
我認為任何系統都是不可靠的。Node可以宕機,link可斷線只要假設硬體是不可靠的,那
麼系統就是不可靠的。我們就要想辦法用系統可靠的一方面去彌補不可靠的一方面。就目前
看真正能可靠的就是明確假定不可靠的前提下,在資料邏輯上做到互相檢查互相校驗。實現
操作資料邏輯的任務可重入可檢查。
任務的可重入是檢查資料完整性一致性的一種安全寫法,可重入的意思是任務的相關資料是記錄式的,例如存入1塊錢,那麼銀行的記錄是存入1塊錢,當前餘額為2塊錢。對應就是兩條記錄,當前存入的資料,累加的資料。累加資料是為了方便讀取。那麼對應key-value就應當是3條資料。
Key: 任務號 ,value: 順序id;
任務號是客戶端生成順序id是伺服器生成的由小到大的順序號,方便查詢最後的任務。
Key :順序id ,value: 加減值;
當前順序id加減的數值。
Key :順序id ,value :加減之後的總值;
根據上一個id計算出的總值方便查詢。
可重入的意識是可以拿客戶端的任務號重新檢查當前任務是否已經產生順序id是否已經寫入正確的加減值,是否已經產生正確的總值,如果沒有就重新產生記錄。這樣只要客戶端的任務號不變同一個任務不會產生多次重複操作,保證資料的一致性和完整性。
如果任何情況斷線導致任務中斷,這個交易也會記錄在冊。
在使用者介面就會顯示這條交易失敗。可以由發起方重新手動繼續交易,直到交易完成。一個正常的交易有中斷,失敗,成功3種狀態。
這個系統對崩潰的應對措施,如同是雙向交易扣錢的同時獲得物品,或則扣物品的同時獲得錢。假設兩個物件的資料都同一臺計算機,這個計算機出現回滾。那麼兩個物件的交易資料同時消失,這筆交易就不存在。即不損失錢也不會被扣除物品。如果兩個物件的資料分別在不同的計算機,其中一個計算機的執行失敗。每個使用者都是扣掉錢獲得物品,或則扣掉物品得到錢,相當收支平衡。
對於單向交易的A物件扣錢,B物件獲得錢。如果A所在伺服器回滾到沒有扣錢,那麼B將憑空獲得一筆錢。那麼A在扣款之後要等待一段時間,伺服器寫入硬碟成功之後,這段時間估計10秒到30秒。然後再發起給B物件獲得金錢的操作。這樣如果A沒有將資料寫入硬碟時,伺服器宕機回滾資料,B也不會獲得金錢。A可以重新發起流程完成匯款。
到這裡我們有了一個分散式的,扁平開發複雜度的,可重入資料的,可線形擴充套件的遊戲
伺服器引擎。歡迎您關注starrydb.com及其未來無限可能的發展。有建議和合作意向可以