
#DeepLearningBook#演算法概覽之六:Linear Factor Models
Linear Factor Models的生成模型描述如下:
1) 生成一個explanatory factors
2) 通過這個隱變數
3) 噪聲Noise一般都是服從協方差矩陣是對角陣的高斯分佈。
一、PCA和Factor Analysis
對因子分析:
它的隱先驗變數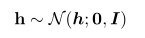
最後它的觀測變數服從的分佈為:
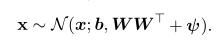
對PCA:
它是在因子分析的基礎上讓噪音的協方差矩陣除了滿足是對角陣的條件外,同時滿足對角位置上的每個元素的值的大小都相等。
二、ICA
ICA主要應用於的場景是多個訊號源經過某種線性疊加後在多個觀測點觀測到了它們的複合值,通過這多個觀測點的值反向退出訊號源處的值。
ICA區別於FA和PCA的一點是,ICA的隱變數(即訊號源變數)不能是高斯分佈。因為高斯分佈是一個高度對稱的分佈,如果使用高斯分佈,那麼係數矩陣W就難以分辨出來。
三、Slow Feature Analysis
SFA通過時間訊號中的資訊學習一些不變的特徵。它的原則是,一個序列中最本質、最重要的特徵往往變化相對比較慢。它主要通過往cost function裡面新增一個表示式來完成相應的功能:
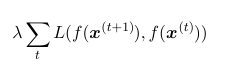
t:時間序列下標
f:特徵提取函式
L:Loss function,計算x在t到t+1時刻的變化大小。
SFA之所以放在Linear Factor Models的類別下是因為它的特徵提取部分
四、Sparse Coding
Sparse coding指的是推導因變數
在因變數到實際觀測變數的過程中,它和其他的linear factor models一樣,用了一個線性解碼器(linear decoder)加噪音的模式來重構x。用公式表達就是:
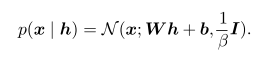
然後個人理解sparse coding的特點就在於隱變數生成的過程。Sparse coding對應了有兩種編碼器(encoder),parametric encoder和non-parametric encoder。
對於parametric encoder,通常將隱變數的分佈設定為一個在0附近有比較突出的峰值的分佈,需要確定的主要是這個分佈的某個引數和權值矩陣W。對於non-parametric encoder,它要做的是是一個優化問題,即給定觀測值,取定最有可能的隱變數的值。
寫在最後:
世界上最可怕的事之一就是寫完了一篇blog一點感想都沒有。個人覺得Chapter13講得真的很general。直接給出結論但是什麼分析都沒有給,和吃白飯一樣,食之無味。