
強化學習之Q-learning簡介
阿新 • • 發佈:2019-01-08
強化學習在alphago中大放異彩,本文將簡要介紹強化學習的一種q-learning。先從最簡單的q-table下手,然後針對state過多的問題引入q-network,最後通過兩個例子加深對q-learning的理解。
強化學習
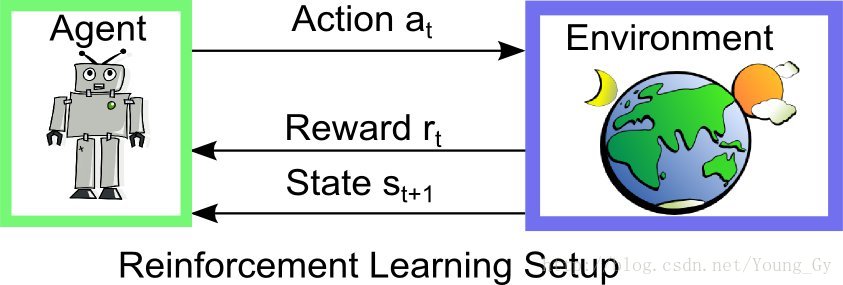
強化學習通常包括兩個實體agent和environment。兩個實體的互動如下,在environment的stateagent採取actionrewardstate
強化學習的問題,通常有如下特點:
- 不同的action產生不同的reward
- reward有延遲性
- 對某個action的reward是基於當前的state的
Q-learning
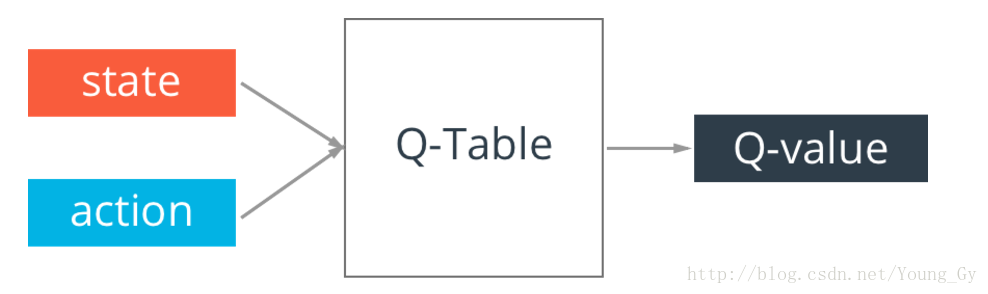
Q-Table
Q-learning的核心是Q-table。Q-table的行和列分別表示state和action的值,Q-table的值s採取actiona到底有多好。
Bellman Equation
在訓練的過程中,我們使用Bellman Equation去更新Q-table。
Bellman Equation解釋如下:
演算法
根據Bellman Equation,學習的最終目的是得到Q-table,演算法如下:
- 外迴圈模擬次數num_episodes
- 內迴圈每次模擬最大步數num_steps
- 根據當前的state和q-table選擇action(可加入隨機性)
- 根據當前的state和action獲得下一步的state和reward
- 更新q-table: Q[s,a] = Q[s,a] + lr*(r + y*np.max(Q[s1,:]) - Q[s,a])
例項
以FrozenLake為例,程式碼如下:
# import lib
import gym
import numpy as np
# Load the environment
env = gym.make('FrozenLake-v0' Deep-Q-learning
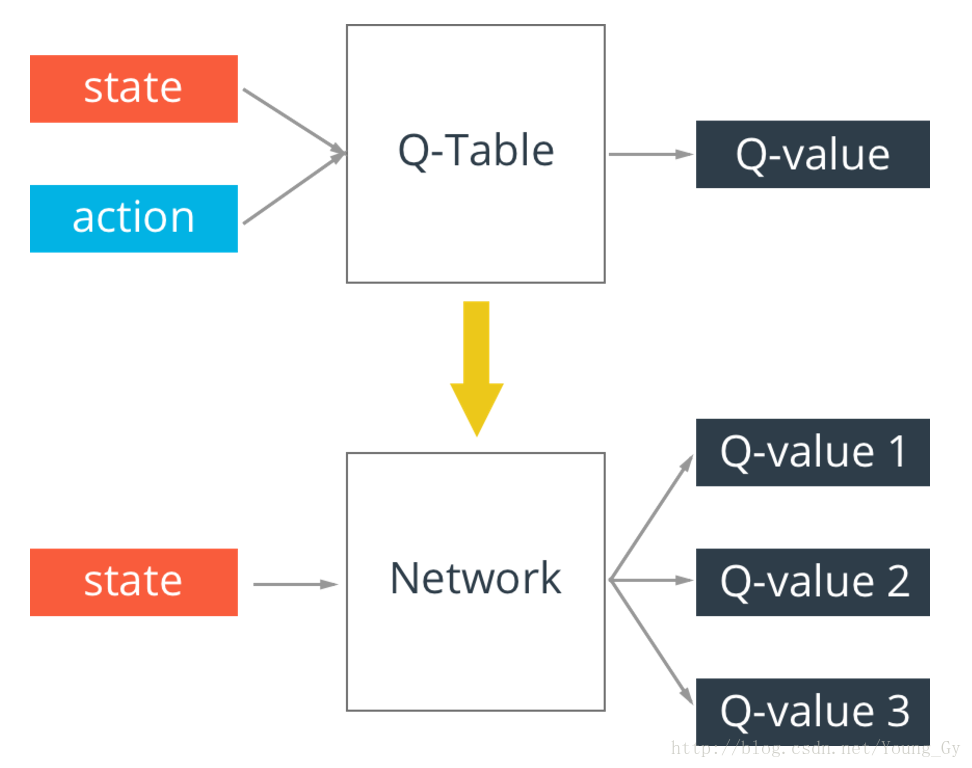
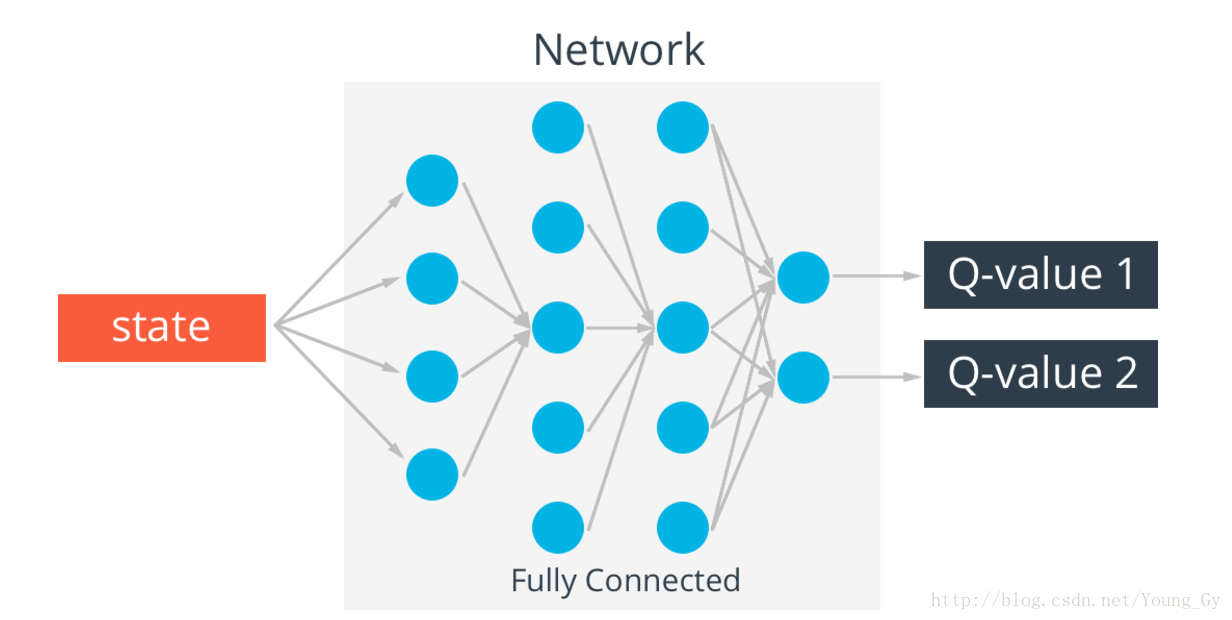
q-table存在一個問題,真實情況的state可能無窮多,這樣q-table就會無限大,解決這個問題的辦法是通過神經網路實現q-table。輸入state,輸出不同action的q-value。
Experience replay
強化學習由於state之間的相關性存在穩定性的問題,解決的辦法是在訓練的時候儲存當前訓練的狀態到記憶體
具體地,
Exploration - Exploitation
- Exploration:在剛開始訓練的時候,為了能夠看到更多可能的情況,需要對action加入一定的隨機性。
- Exploitation:隨著訓練的加深,逐漸降低隨機性,也就是降低隨機action出現的概率。
演算法

例項
CartPole
# import lib
import gym
import tensorflow as tf
import numpy as np
# Create the Cart-Pole game environment
env = gym.make('CartPole-v0')
# Q-network
class QNetwork:
def __init__(self, learning_rate=0.01, state_size=4,
action_size=2, hidden_size=10,
name='QNetwork'):
# state inputs to the Q-network
with tf.variable_scope(name):
self.inputs_ = tf.placeholder(tf.float32, [None, state_size], name='inputs')
# One hot encode the actions to later choose the Q-value for the action
self.actions_ = tf.placeholder(tf.int32, [None], name='actions')
one_hot_actions = tf.one_hot(self.actions_, action_size)
# Target Q values for training
self.targetQs_ = tf.placeholder(tf.float32, [None], name='target')
# ReLU hidden layers
self.fc1 = tf.contrib.layers.fully_connected(self.inputs_, hidden_size)
self.fc2 = tf.contrib.layers.fully_connected(self.fc1, hidden_size)
# Linear output layer
self.output = tf.contrib.layers.fully_connected(self.fc2, action_size,
activation_fn=None)
### Train with loss (targetQ - Q)^2
# output has length 2, for two actions. This next line chooses
# one value from output (per row) according to the one-hot encoded actions.
self.Q = tf.reduce_sum(tf.multiply(self.output, one_hot_actions), axis=1)
self.loss = tf.reduce_mean(tf.square(self.targetQs_ - self.Q))
self.opt = tf.train.AdamOptimizer(learning_rate).minimize(self.loss)
# Experience replay
from collections import deque
class Memory():
def __init__(self, max_size = 1000):
self.buffer = deque(maxlen=max_size)
def add(self, experience):
self.buffer.append(experience)
def sample(self, batch_size):
idx = np.random.choice(np.arange(len(self.buffer)),
size=batch_size,
replace=False)
return [self.buffer[ii] for ii in idx]
# hyperparameters
train_episodes = 1000 # max number of episodes to learn from
max_steps = 200 # max steps in an episode
gamma = 0.99 # future reward discount
# Exploration parameters
explore_start = 1.0 # exploration probability at start
explore_stop = 0.01 # minimum exploration probability
decay_rate = 0.0001 # exponential decay rate for exploration prob
# Network parameters
hidden_size = 64 # number of units in each Q-network hidden layer
learning_rate = 0.0001 # Q-network learning rate
# Memory parameters
memory_size = 10000 # memory capacity
batch_size = 20 # experience mini-batch size
pretrain_length = batch_size # number experiences to pretrain the memory
tf.reset_default_graph()
mainQN = QNetwork(name='main', hidden_size=hidden_size, learning_rate=learning_rate)
# Populate the experience memory
# Initialize the simulation
env.reset()
# Take one random step to get the pole and cart moving
state, reward, done, _ = env.step(env.action_space.sample())
memory = Memory(max_size=memory_size)
# Make a bunch of random actions and store the experiences
for ii in range(pretrain_length):
# Uncomment the line below to watch the simulation
# env.render()
# Make a random action
action = env.action_space.sample()
next_state, reward, done, _ = env.step(action)
if done:
# The simulation fails so no next state
next_state = np.zeros(state.shape)
# Add experience to memory
memory.add((state, action, reward, next_state))
# Start new episode
env.reset()
# Take one random step to get the pole and cart moving
state, reward, done, _ = env.step(env.action_space.sample())
else:
# Add experience to memory
memory.add((state, action, reward, next_state))
state = next_state
# Training
# Now train with experiences
saver = tf.train.Saver()
rewards_list = []
with tf.Session() as sess:
# Initialize variables
sess.run(tf.global_variables_initializer())
step = 0
for ep in range(1, train_episodes):
total_reward = 0
t = 0
while t < max_steps:
step += 1
# Uncomment this next line to watch the training
env.render()
# Explore or Exploit
explore_p = explore_stop + (explore_start - explore_stop)*np.exp(-decay_rate*step)
if explore_p > np.random.rand():
# Make a random action
action = env.action_space.sample()
else:
# Get action from Q-network
feed = {mainQN.inputs_: state.reshape((1, *state.shape))}
Qs = sess.run(mainQN.output, feed_dict=feed)
action = np.argmax(Qs)
# Take action, get new state and reward
next_state, reward, done, _ = env.step(action)
total_reward += reward
if done:
# the episode ends so no next state
next_state = np.zeros(state.shape)
t = max_steps
print('Episode: {}'.format(ep),
'Total reward: {}'.format(total_reward),
'Training loss: {:.4f}'.format(loss),
'Explore P: {:.4f}'.format(explore_p))
rewards_list.append((ep, total_reward))
# Add experience to memory
memory.add((state, action, reward, next_state))
# Start new episode
env.reset()
# Take one random step to get the pole and cart moving
state, reward, done, _ = env.step(env.action_space.sample())
else:
# Add experience to memory
memory.add((state, action, reward, next_state))
state = next_state
t += 1
# Sample mini-batch from memory
batch = memory.sample(batch_size)
states = np.array([each[0] for each in batch])
actions = np.array([each[1] for each in batch])
rewards = np.array([each[2] for each in batch])
next_states = np.array([each[3] for each in batch])
# Train network
target_Qs = sess.run(mainQN.output, feed_dict={mainQN.inputs_: next_states})
# Set target_Qs to 0 for states where episode ends
episode_ends = (next_states == np.zeros(states[0].shape)).all(axis=1)
target_Qs[episode_ends] = (0, 0)
targets = rewards + gamma * np.max(target_Qs, axis=1)
loss, _ = sess.run([mainQN.loss, mainQN.opt],
feed_dict={mainQN.inputs_: states,
mainQN.targetQs_: targets,
mainQN.actions_: actions})
saver.save(sess, "checkpoints/cartpole.ckpt")
# Testing
test_episodes = 10
test_max_steps = 400
env.reset()
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('checkpoints'))
for ep in range(1, test_episodes):
t = 0
while t < test_max_steps:
env.render()
# Get action from Q-network
feed = {mainQN.inputs_: state.reshape((1, *state.shape))}
Qs = sess.run(mainQN.output, feed_dict=feed)
action = np.argmax(Qs)
# Take action, get new state and reward
next_state, reward, done, _ = env.step(action)
if done:
t = test_max_steps
env.reset()
# Take one random step to get the pole and cart moving
state, reward, done, _ = env.step(env.action_space.sample())
else:
state = next_state
t += 1
env.close()FrozenLake
# import lib
import gym
import numpy as np
import random
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
# laod env
env = gym.make('FrozenLake-v0')
# The Q-Network Approach
tf.reset_default_graph()
#These lines establish the feed-forward part of the network used to choose actions
inputs1 = tf.placeholder(shape=[1,16],dtype=tf.float32)
W = tf.Variable(tf.random_uniform([16,4],0,0.01))
Qout = tf.matmul(inputs1,W)
predict = tf.argmax(Qout,1)
#Below we obtain the loss by taking the sum of squares difference between the target and prediction Q values.
nextQ = tf.placeholder(shape=[1,4],dtype=tf.float32)
loss = tf.reduce_sum(tf.square(nextQ - Qout))
trainer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
updateModel = trainer.minimize(loss)
# Training
init = tf.initialize_all_variables()
# Set learning parameters
y = .99
e = 0.1
num_episodes = 2000
#create lists to contain total rewards and steps per episode
jList = []
rList = []
with tf.Session() as sess:
sess.run(init)
for i in range(num_episodes):
#Reset environment and get first new observation
s = env.reset()
rAll = 0
d = False
j = 0
#The Q-Network
while j < 99:
j+=1
#Choose an action by greedily (with e chance of random action) from the Q-network
a,allQ = sess.run([predict,Qout],feed_dict={inputs1:np.identity(16)[s:s+1]})
if np.random.rand(1) < e:
a[0] = env.action_space.sample()
#Get new state and reward from environment
s1,r,d,_ = env.step(a[0])
#Obtain the Q' values by feeding the new state through our network
Q1 = sess.run(Qout,feed_dict={inputs1:np.identity(16)[s1:s1+1]})
#Obtain maxQ' and set our target value for chosen action.
maxQ1 = np.max(Q1)
targetQ = allQ
targetQ[0,a[0]] = r + y*maxQ1
#Train our network using target and predicted Q values
_,W1 = sess.run([updateModel,W],feed_dict={inputs1:np.identity(16)[s:s+1],nextQ:targetQ})
rAll += r
s = s1
if d == True:
#Reduce chance of random action as we train the model.
e = 1./((i/50) + 10)
break
jList.append(j)
rList.append(rAll)
print "Percent of succesful episodes: " + str(sum(rList)/num_episodes) + "%"