
針對移動端TBDR架構GPU特性的渲染優化
TBDR(Tile-Base-Deffered-Rendering)是現代移動端gpu的設計架構,它同傳統pc上IR(Immediate-Rendering)架構的gpu在硬體設計上是差別很大的。手遊正是執行在這些移動端的TBDR架構上,所以手遊的渲染優化在硬體的角度上講有其獨特之處,甚至一些特點和優化點與PC是大相徑庭的,基於硬體的優化是應用程式優化很重要的一部分,最近閱讀了一些tbdr的硬體設計的文件,本文試圖對TBDR的特點做些介紹並基於這些特點的優化做個簡單的總結。
1.為什麼移動端選擇了tbdr
提到tbdr,很多人第一反應是這是一個DefferedRendering技術,它應該是為了優化渲染的,但是它同我們軟體層面的延遲渲染不同,它是在硬體中實現的一種延遲渲染。那麼又有很多人又會想到那既然DR這麼好的技術,為什麼在pc的顯示卡中不去這麼設計,而反而在更加廉價的手機顯示卡中設計。這要從移動端gpu的一大瓶頸來說起。
移動端的硬體在設計最開始想到的最重要的問題就是功耗,功耗意味著發熱量,意味著耗電量,意味著晶片大小…所以gpu也是把功耗擺在第一位,然而在gpu的渲染過程中,對功耗影響最大的是頻寬,對,bandwith,這是功耗的第一大殺手。可以算一下,在移動端,一個1920*1080的螢幕上,每渲染一幀影象,對FrameBuffer的訪問量是驚人的(各種test,blend,再算上MSAA, overdraw等等),通常gpu的onchip memory(也就是SRAM,或者L1 L2 cache)很小,這麼大的FrameBuffer要儲存在離gpu相對較遠的DRAM(視訊記憶體)上,可以把gpu想象成你家,SRAM想象成小區便利店,DRAM想象成市中心超市,從gpu對framebuffer的訪問就相當於一輛貨車大量的在你家和市中心之間往返運輸,頻寬和發熱量之巨大是手機上無法接受的。
於是移動端的gpu想到了一種化整為零的方法,把巨大的FrameBuffer分解成很多小塊,使得每個小塊可以被離gpu更近的那個SRAM可以容納,塊的多少取決於你的硬體的SRAM的大小。這樣gpu可以分批的一塊塊的在SRAM上訪問framebuffer,一整塊都訪問好了後整體轉移回DRAM上,這樣問題就解決了。為什麼這樣可以減少頻寬?想想,對FrameBuffer現在幾乎全部的訪問在渲染這一塊的時候(test,read,write,blend…)都完全在SRAM上解決,只在最後把這一塊整體渲染完了才整體搬回DRAM。這種模式就叫做TBR(tile-based-rendering),他和pc上從傳統的IR(immediate-rendering)的對比如下圖。
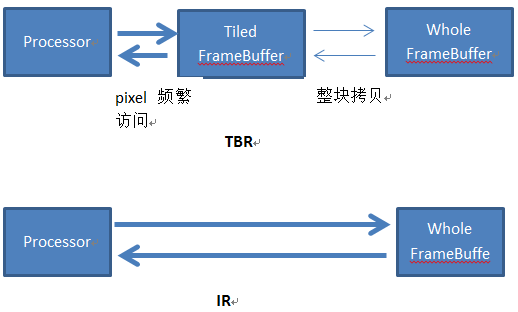
那麼為什麼pc不使用tbr,這是因為實際上直接對DRAM上進行讀寫的速度是最快的,tbdr需要一塊塊的繪製然後回拷,可以說如果哪一天手機上可以解決頻寬產生的功耗問題,或者說sram可以做的足夠大了,那麼就沒有TBDR什麼事了。可以簡單的認為TBR犧牲了執行效率,但是換來了相對更難解決的頻寬功耗。
2 FrameData
Ok,tbr的前世今生搞清楚了。然後說說這個TBR種加入的D。在設計了TBR後,移動端gpu接受cpu的繪製指令後的繪製行為其實完全改變掉了。大家可以看到,在tbr的架構上,是不能夠來一個commandbuffer就執行一個的,那是噩夢,因為任何一個commandbuffer都可能影響到到整個FrameBuffer,如果來一個畫一個,那麼gpu可能會在每一個drawcall上都來回搬遷所有的Tile。這太慢了!所以TBR一般的實現策略是對於cpu過來的commandbuffer,只對他們做vetex process,然後對vs產生的結果暫時儲存,等待非得重新整理整個FrameBuffer的時候,才真正的隨這批繪製做光柵化,做tile-based-rendering。什麼是非得重新整理整個FrameBuffer的時候?比如Swap Back and Front Buffer,glflush,glfinish,glreadpixels,glcopytexiamge,glbitframebuffer,queryingocclusion,unbind the framebuffer..總之是所有gpu覺得不得不把這塊fb繪製好的時候。所以tbr的真正的繪製管線是這樣的。
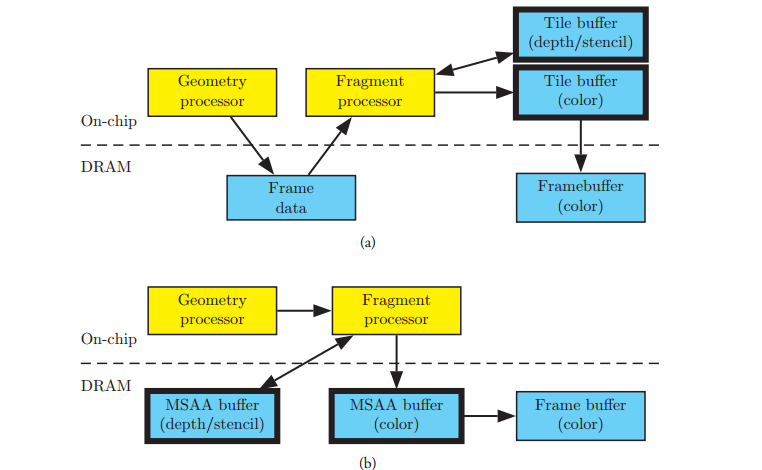
上面是tbr,下面是ir,這裡可以看到TBR的管線上在PixelShader之前增多了一個步驟,即vs和gs處理後的資料(這裡叫做FrameData)被暫時儲存下來排好隊,然後後面再對framebuffer分塊,然後對每一塊,繪製所有影響這個塊的pixel。
FrameData這個是tbr特有的在gpu繪製時所需的儲存資料,在powervr上叫做arguments buffer,在arm上叫做plolygon lists。既然tbr上是等待所有的framedata資料一起繪製pixel的,那麼gpu就又多了一個優化的可能,deffered rendering,現有的大部分tbr的顯示卡都或多或少做了這個優化,例如ios的powervr,它多了一個叫做ISR的硬體,專門對這些framedata做處理,找到這次渲染真正有可能會被寫入到Framebuffer上的那些drawcall,而過濾掉大部分的drawcall。例如對於不透明物體,一些可能不通過ztest的,一些會被stencil reject的,他們在ISR處理framedata後根本都不會進入pixel shader。(所以其實在power vr上對不透明物體的排序是沒有太大意義的,而early-z這種策略也是不存在ios上的。)看,硬體巧妙的利用tbr的framedata佇列實現了一種延遲渲染,即儘可能只渲染那些最終影響fb的物體,和軟體層面的延遲渲染不同的是,軟體層面的延遲渲染是針對一個drawcall的,對於從後到前的不透明物體繪製是每次都會繪製的,而硬體層面的延遲渲染時對一批drawcall的,它會從這批繪製裡面找到最終要繪製的物體。所以現在大部分的移動端的gpu可以被稱為TBDR架構。
3.基於TBDR的渲染優化
Tbdr和pc的gpu 模式有如此之大的不同,那麼針對tbdr的特點,我們可以總結一些重要的優化特性,有些甚至和pc是南轅北轍的。
3.1記得不使用Framebuffer的時候clear或者discard
前面說到framedata會一直積攢下來直到等到一些必須要繪製到framebuffer上的時候,這意味著tbdr的架構下commandbuffer不會被立即執行,只是積攢到一定的時間點。而glclear這種操作是可以把當前的framedata清空的,這樣就會節省很多不必要的繪製。
設想一種情況,你一直往一個Rendertexture上繪製,過了一會當你不再使用這張rendertexture的時候(即unbind)也會觸發這些framedata的繪製,如果在你不再使用這張圖之前能夠呼叫一次clear,那麼unbind的時候framedata就是清空的,可以減少很多不必要的繪製。在gl上還有這樣一個擴充套件EXT_discard_framebuffer可以更加明顯的暗示當前的這個framebuffer不需要使用了,framedata將被清空。
所以在unity裡面對rendertexture的使用也特別說明了一下,當不再使用這個rt之前,呼叫一次Discard()可以在某些移動裝置上提高效能,即是這個原理,如果不discard,那麼在unbind那一刻會觸發此刻還存在的那個FrameData的處理。
PC顯示卡不需要這樣做,因為pc上每次commandbuffer都是來了立即繪製,不存在framedata排隊直說,所以在移動平臺上一定牢記繪製不是立即的,是在特定時間觸發對整個framedata的延遲渲染。
3.2在每幀渲染之前儘量clear
在一些渲染技巧裡面可能每幀渲染前不clear當前的buffer,例如認為下一幀一定會把整個fb都寫掉,就沒必要先clear了。這是對於pc顯示卡來說的,對於tbr架構這就是個噩夢了。因為如果不clear,那麼每個tile在初始化的時候都要從dram上的framebuffer把那一塊的內容完整拷貝過來,而clear這個初始化就變得非常簡單了。
3.3不要在一幀裡面頻繁的切換framebuffer
前面說到,tbdr的架構,gpu會盡可能的只在不得不繪製的時候才渲染framebuffer。假設這樣一種情況,你先在fb上繪製a,然後使用fb,然後繪製b,再使用fb,再繪製c,再使用fb,這對於pc顯示卡問題不大,但是移動裝置上每次使用fb都會觸發一個所有tile的繪製,如果我們能儘量做到繪製a,b,c後再一起使用fb就好了。
同樣的我們看到遊戲中的全屏後處理被大量的使用,這在手機上效能不高,主要就是這些後處理可能在1幀內觸發很多次不同的framebuffer之間的bind unbind,每一次bindunbind都需要對整個framebuffer的一次立即繪製。而tbr的繪製速度是不能和ir相比的,畢竟tile是要一塊塊從dram拷貝到sram進行渲染的。切換framebuffer在tbdr的架構是效能瓶頸。
3.4 關於early-z
因為tbdr有framedata佇列,很多gpu會很聰明的儘量篩去不需要繪製的framedata。所以在tbdr上earlyz,或者stencil test這些是非常有益處的。例如你定義了一個stencil,gpu有可能在對framedata處理的過程中就篩掉了那些不能通過stencil的drawcall了。或者通過scissor test可能一整塊tile都不需要繪製。
關於Early-z也一樣,很多程式會通過預先渲染一遍簡單的zpass來佔住z,這樣就可以在對framedata處理階段就reject掉那些不能通過z的drawcall了。但是要注意的是powervr的gpu不需要eralyz,因為它內部的isr硬體會自動處理這批framedata最終繪製到螢幕的drawcall,甚至也不需要對不透明的物體做從前到後的繪製排序。至於大部分android裝置,預先的一遍early-z pass可能就可以大大減少你的overdraw了,不過還是需要慎重,因為預先的一遍early-z pass又會增加cpu的提交負擔,儘管很多android顯示卡對於zpass有特殊的優化。總之如果頻寬瓶頸嚴重,那麼early-z是有必要開的。但這裡要明確的概念是,移動端的early-z發生在哪個階段,不是在光柵化和ps之間,而是更早的對framedata的處理過程中。
3.5 blending和MSAA的效率其實很高,alpha-test效率很低
回頭看下tbdr的渲染管線,對於一個tile上所有pixel的繪製都是在on-chip的mem上的,只在最後繪製好了才整體回拷給dram。所以我們通常認為會造成大量頻寬的操作,例如blending(對framebuffer的讀和寫),msaa(增加對framebuffer讀取的次數)其實在tbdr上反而是非常快速的。(當然msaa除了會造成framebuffer訪問增多,還會帶來渲染畫素的數量增多,這個是tbr沒什麼優化的)
這時我們來細說一下另一種透明技術alpha-test這個東西,很多文獻說到alpha-test這種技術在ios的顯示卡上效率較差,不如alpha-blending。道理是什麼?從這個聰明的基於tbdr的gpu來看,如果他看到連續的不透明物體的繪製,因為寫入的depth其實不用經過pixel shader已經是固定了,所以很多depth靠後的的在tile上有可能被去掉,但是alpha-test這個東西,他對depth的寫入是不能預先確定的,它必須等到pixel shader執行,這導致了alpha-test之後的那些framedata失去了early –z的機會,也就增加了渲染量。而用alpha-blending則不會寫入depth,所以對於這個聰明的gpu提前剔除z是不影響的,再加上blending的頻寬消耗在tbr上又微乎其微。
blending更高效,alpha-test是效能瓶頸這些都是因為tbdr的gpu會對framedata做預先的優化處理帶來的,這點是要牢記的。事實上powervr的gpu推薦的一個渲染順序是opaque,再alpha-test,最後blending。這樣alpha-test不會阻擋到更多的不透明物體的z預剔除。
3.6 延遲
很明顯tbr的模式比ir存在延遲,例如想得到framebuffer上的一些結果,理論上是要存在一定的時間的,畢竟gpu會在最後一刻逼不得已的時候做渲染,這種延遲在一些使用的場景要記住。
3.7避免大量的drawcall和頂點量
傳統的pc上看,drawcall以及頂點數量對gpu是沒有太多嚴重的影響,但是放到tbr的移動裝置上,結論就不是這樣的,顯然我們看到tbr渲染的時候再gs後會儲存framedata佇列,這個framedata資料會隨著你的drawcall,你的頂點量而增大,頂點量佔大頭,甚至在一些情況增大到記憶體放不下的情況,而需要暫時移動到別處,這種情況對framedata的訪問速度就奇慢無比了。
Tbr比ir多需要一份framedata的儲存,這是比較重要的一個特性,因此手游上的drawcall和頂點量是要有限度的,因為它們不只是像pc那樣影響cpu,還會嚴重影響到你的gpu。雖然沒有找到這個framedata究竟在不同的裝置上可以存放多大,但是測試來看百萬的頂點量不管你的drawcall多少,shader多簡單,在大部分機器都肯定會觸發這個瓶頸了。
3.8避免gpu上的copy-on-write
因為tbdr的渲染是延遲的,想象這樣一種情況,你當前幀內對一個mesh做個頂點動畫,傳遞給gpu繪製,然後後面又改變了它的頂點動畫,又提交給gpu,這樣前面一個的vb還繫結在gpu上沒有被處理,處於framedata佇列狀態,這一份同樣的vb(改變過的)又要過來了,這時gpu會對這個vb做一個新的拷貝,以儲存vb的多份不同的資料。顯然這又增加了framedata的儲存,會觸發上面3.7的瓶頸。所以千萬不要在同一幀內多次改變提交給gpu的資源,這會迅速把framedata撐大到裝不下的狀態。
其實總結了這些,我們發現tbdr完全是為了降低手機的頻寬功耗而採取的一種分批次分割槽塊繪製的折衷,並且在這個過程中利用framedata的list儘可能的挖掘延遲渲染的潛力,當然這一切都是硬體做的,硬體的優化水平有高有低,powervr就優化到了一種極致,arm的則相對弱一些,但是不管怎樣,作為程式開發層的我們如果能夠理解這個硬體上的變化,就可能更加順應硬體的設計初衷,做出更高效的程式。同時tbdr的誕生就是為了對抗功耗,也在警醒我們在平時開發過程中,也應該把功耗視為手機上最大的效能陷阱,在功耗和表現之間做平衡。
參考資料:
1. Opengl Insights:performance Tuning for Tile-based_architectures
2. ARM. Mali GPUApplication Optimization Guide, 2011. Version 1.0.
3. Imagination Technologies Ltd. POWERVRSeries5 Graphics SGX Architecture Guide
for Developers, 2011. Version 1.0.8.
4. Qualcomm Incorporated. Adreno™200 Performance Optimization: OpenGL ES
Tips and Tricks, 2010
5. PowerVR PerformanceRecommendations The Golden Rules