Python利用SVM進行例項建模
阿新 • • 發佈:2019-01-08
一、建立時間預測器
1.準備工作
我們所獲得的資料集主要來源於課本配套網站,我們首先看building_event_binary.txt檔案中6個字串資料的排序:
星期、日期、時間、離開大樓的人數、進入大樓的人數、是否有活動
前5個欄位組成輸入資料,我們的任務是預測大樓是否舉行活動。
building_event_multiclass.txt檔案星期、日期、時間、離開大樓的人數、進入大樓的人數、活動型別
2.詳細步驟
首先將資料全部加在X中:
import numpy as np from sklearn import preprocessing from sklearn.svm import SVC input_file = 'building_event_binary.txt' #讀取資料 X = [] count = 0 with open(input_file,'r') as f: for line in f.readlines(): data = line[:-1].split(',') X.append([data[0]] + data[2:]) X = np.array(X)
下面將字串格式轉換成數值格式
label_encoder = [] X_encoder = np.empty(X.shape) for i,item in enumerate(X[0]): if item.isdigit(): X_encoder[:,i] = X[:,i] else: label_encoder.append(preprocessing.LabelEncoder()) X_encoder[:,i] = label_encoder[-1].fit_transform(X[:,i]) X = X_encoder[:,:-1].astype(int) y = X_encoder[:,-1].astype(int)
用徑向基函式、概率輸出和型別平衡方法訓練SVM分類器並進行交叉驗證
params = {'kernel':'rbf','probability':True} classifier = SVC(**params) classifier.fit(X,y) #交叉驗證 from sklearn import cross_validation accuracy = cross_validation.cross_val_score(classifier, X,y,scoring = 'accuracy',cv = 3) print("Accuracy of the classifier:" + str(round(100*accuracy.mean(),2))+"%")
用一個新的資料點測試SVM
input_data = ['Tuesday', '12:30:00','21','23']
input_data_encoded = [-1] * len(input_data)
count = 0
for i,item in enumerate(input_data):
if item.isdigit():
input_data_encoded[i] = int(input_data[i])
else:
input_data_encoded[i] = int(label_encoder[count].transform(input_data[i]))
count = count + 1
input_data_encoded = np.array(input_data_encoded)為特定資料點預測並列印輸出結果
output_class = classifier.predict(input_data_encoded)
print("Output class:", label_encoder[-1].inverse_transform(output_class)[0])結果如下:

準確率達到93%
二、估算交通流量
1.traffuc_data.txt檔案包含以下欄位:
星期、時間、對手球隊、棒球比賽是否繼續、通行汽車數量
2.程式碼步驟
資料載入
import numpy as np
from sklearn import preprocessing
from sklearn.svm import SVR
input_file = 'traffic_data.txt'
# Reading the data
X = []
count = 0
with open(input_file, 'r') as f:
for line in f.readlines():
data = line[:-1].split(',')
X.append(data)
X = np.array(X)把資料進行編碼
label_encoder = []
X_encoded = np.empty(X.shape)
for i,item in enumerate(X[0]):
if item.isdigit():
X_encoded[:, i] = X[:, i]
else:
label_encoder.append(preprocessing.LabelEncoder())
X_encoded[:, i] = label_encoder[-1].fit_transform(X[:, i])
X = X_encoded[:, :-1].astype(int)
y = X_encoded[:, -1].astype(int)用徑向基函式建立並訓練SVM迴歸器,引數C指定了對錯誤分類的懲罰,引數epsilon指定了不使用懲罰的限制
params = {'kernel': 'rbf', 'C': 10.0, 'epsilon': 0.2}
regressor = SVR(**params)
regressor.fit(X, y)用交叉驗證來檢查迴歸器的效能
import sklearn.metrics as sm
y_pred = regressor.predict(X)
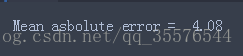
print("Mean asbolute error = ",round(sm.mean_absolute_error(y,y_pred),2)在一個數據點上進行測試
input_data = ['Tuesday', '13:35', 'San Francisco', 'yes']
input_data_encoded = [-1] * len(input_data)
count = 0
for i,item in enumerate(input_data):
if item.isdigit():
input_data_encoded[i] = int(input_data[i])
else:
input_data_encoded[i] = int(label_encoder[count].transform(input_data[i]))
count = count + 1
input_data_encoded = np.array(input_data_encoded)
# Predict and print output for a particular datapoint
print("Predicted traffic:", int(regressor.predict(input_data_encoded)[0]))結果如下: