
區塊鏈中常用共識演算法總結
本文是對區塊鏈技術中涉及的共識演算法的學習總結整理。 其中PBFT和Raft是聯盟鏈和私有鏈常用的共識演算法,而PoW(比特幣採用)和PoS是公有鏈常用的共識演算法。
建議對區塊鏈的學習,要分成是公有鏈還是聯盟鏈,這兩種鏈中一般採用的共識演算法是有較大不同的,P2P網路等也有較大的不同。傳統的共識演算法一般不適用於公有鏈,而一定程度上適用於聯盟鏈。
實用拜占庭容錯系統PBFT(聯盟鏈中常用)
拜占庭容錯技術(Byzantine Fault Tolerance,BFT)是一類分散式計算領域的容錯技術,是一種解決分散式系統容錯問題的通用方案。實用拜占庭容錯系統(Practical Byzantine Fault Tolerance,PBFT)使拜占庭協議的運行復雜度從指數級別降低到多項式級別,使拜占庭協議在分散式系統中應用成為可能。
拜占庭將軍問題
拜占庭將軍(Byzantine Generals Problem)問題,是 Leslie Lamport 1982 年提出用來解釋一致性問題的一個虛構模型。拜占庭是古代東羅馬帝國的首都,由於地域寬廣,守衛邊境的多個將軍(系統中的多個節點)需要通過信使來傳遞訊息,達成某些一致的決定。但由於將軍中可能存在叛徒(系統中節點出錯),這些叛徒將努力向不同的將軍傳送不同的訊息,試圖會干擾一致性的達成。拜占庭問題即為在此情況下,如何讓忠誠的將軍們能達成行動的一致。
拜占庭容錯系統
拜占庭容錯系統是指:在一個擁有臺節點的系統,整個系統,對每個請求滿足如下條件:
- 所有非拜占庭節點使用相同的輸入資訊,產生同樣的結果;
- 如果輸入的資訊正確,那麼所有非拜占庭節點必須接收這個資訊,並計算相應的結果。
與此同時,在拜占庭系統的實際執行過程中一般假設系統中拜占庭節點不超過臺,並且對每個請求滿足2個指標:
- 安全性——任何已經完成的請求都不會被更改,它可以在以後請求看到;
- 活性——可以接受並且執行非拜占庭客戶端的請求,不會被任何因素影響而導致非拜占庭客戶端的請求不能執行。
拜占庭系統目前普遍採用的假設條件包括:
1) 拜占庭節點的行為可以是任意的,拜占庭節點之間可以共謀;
2) 節點之間的錯誤是不相關的;
3) 節點之間通過非同步網路連線,網路中的訊息可能丟失、亂序、延時到達;
4) 伺服器之間傳遞的資訊,第三方可以知曉 ,但是不能竄改、偽造資訊的內容和驗證資訊的完整性;
(發生故障的節點稱為拜占庭節點;正常的節點為非拜占庭節點。)
狀態機拜占庭系統
狀態機拜占庭系統的特點
狀態機拜占庭系統的特點是整個系統共同維護一個狀態,所有節點採取一致的行動,一般包括 3 種協議:一致性協議、 檢查點協議和檢視更換協議。系統正常執行在一致性協議和檢查點協議下,檢視更換協議則是隻有在主節點出錯或者執行緩慢的情況下才會啟動,負責維繫系統繼續執行客戶端請求的能力。
狀態機拜占庭系統的核心協議
一、一致性協議
一致性協議的目標是使來自客戶端的請求在每個伺服器上都按照一個確定的順序執行。在協議中,一般有一個伺服器被稱作主節點,負責將客戶端的請求排序;其餘的伺服器稱作從節點,按照主節點提供的順序執行請求。所有的伺服器都在相同的配置資訊下工作,這個配置資訊稱作view,每更換一次主節點,view就會隨之變化。
一致性協議至少包含3個階段:傳送請求、序號分配和返回結果。根據協議設計的不同,可能包含相互互動、序號確認等階段。
一致性協議解決一致性的方法主要有:
1)伺服器之間兩兩互動,伺服器通過將自己獲得的資訊傳遞給其他的伺服器;
2)由客戶端收集伺服器的資訊,將收集的資訊製作成證明檔案再發送給伺服器。對於一個包含臺伺服器的拜占庭系統,需要收集到臺伺服器傳送的一致資訊,才能保證達成一致的非拜占庭伺服器數量大於拜占庭伺服器數量。
引申思考:
1. 部署一個採用PBFT共識演算法的區塊鏈,至少需要幾個節點呢?
2. PBFT共識演算法的區塊鏈,最佳節點數量問題,採用PBFT共識演算法的區塊鏈系統節點數量的下限和上限?
二、檢查點協議
拜占庭系統每執行一個請求,伺服器需要記錄日誌。如果日誌得不到及時的清理,就會導致系統資源被大量的日誌所佔用,影響系統性能及可用性。另一方面,由於拜占庭伺服器的存在,一致性協議並不能保證每一臺伺服器都執行了相同的請求,所以,不同伺服器狀態可能不一致。例如,某些伺服器可能由於網路延時導致從某個序號開始,之後的請求都沒有執行。因此,拜占庭系統中設定週期性的檢查點協議,將系統中的伺服器同步到某一個相同的狀態。因此,週期性的檢查點協議可以定期地處理日誌,節約資源,同時及時糾正伺服器狀態。
處理日誌主要解決的問題就是區分那些日誌可以清理,那些日誌仍然需要保留。如果一個請求已經被臺非拜占庭伺服器執行,並且某一伺服器能夠向其他的伺服器證明這一點,那麼就可以將關於這個請求的日誌刪除。目前,協議普遍採用的方式是伺服器每執行一定數量的請求,就將自己的狀態傳送給所有伺服器並且執行一個該協議,如果某臺伺服器接收到臺伺服器的狀態,那麼其中一致的部分就是至少有非拜占庭伺服器經歷過的狀態,因此,這部分的日誌就可以刪除,同時將自己狀態更新只較新狀態。
三、檢視更換
在一致性協議裡,已經知道主節點在整個系統中擁有序號分配,請求轉發等核心能力,支配著這個系統的執行行為。然而一旦主節點自身發生錯誤,就可能導致從節點接收到具有相同序號的不同請求,或者同一個請求被分配多個序號等問題,這將直接導致請求不能被正確執行。檢視更換協議的作用就是在主節點不能繼續履行職責時,將其用一個從節點替換掉,並且保證已經被非拜占庭伺服器執行的請求不會被篡改。
檢視更換協議一般有兩種觸發方式:
1)只由伺服器觸發,這一類觸發方式中,判斷伺服器一致性是否達成的工作是由伺服器自身負責,客戶端不能從請求的整個執行過程中獲得伺服器執行狀況的資訊;
2)客戶端觸發,這一類觸發方式中,客戶端一般負責判斷伺服器是否達成一致,如果不達成一致,那麼就能判斷伺服器執行出現問題,如果是主節點的問題就會要求伺服器更換主節點。
檢視更換協議需要解決的問題是如何保證已經被非拜占庭伺服器執行的請求不被更改。由於系統達成一致性之後至少有臺非拜占庭伺服器執行了請求,所以目前採用的方法是:由新的主節點收集至少臺伺服器的狀態資訊,這些狀態資訊中一定包含所有執行過的請求;然後,新主節點將這些狀態資訊傳送給所有的伺服器,伺服器按照相同的原則將在上一個主節點完成的請求同步一遍.同步之後,所有的節點都處於相同的狀態,這時就可以開始執行新的請求。
實用拜占庭容錯系統PBFT詳解
實用拜占庭容錯系統(Practical Byzantine Fault Tolerance,PBFT),是一類狀態機拜占庭系統。
PBFT的一致性協議如下:PBFT系統通常假設故障節點數為個,而整個服務節點數為個。每一個客戶端的請求需要經過5個階段,通過採用兩次兩兩互動的方式在伺服器達成一致之後再執行客戶端的請求。由於客戶端不能從伺服器端獲取任何伺服器執行的狀態資訊,PBFT中主節點是否發生錯誤只能由伺服器監測。如果伺服器在一段時間內都不能完成客戶端的請求,則會觸發檢視更換協議。
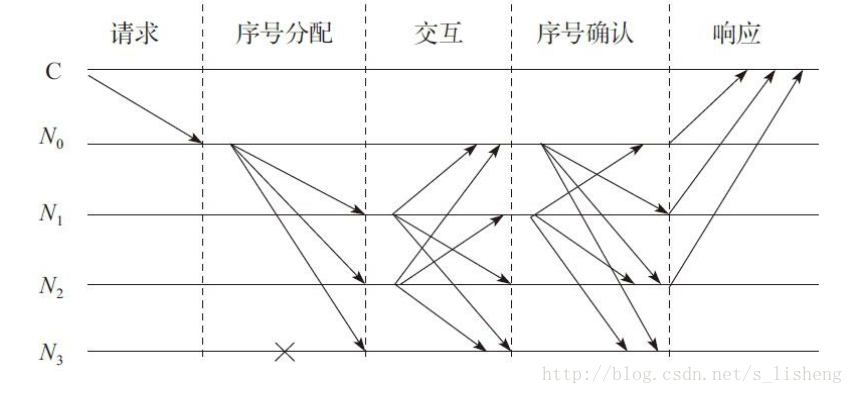
上圖顯示了一個簡化的PBFT的協議通訊模式,其中為客戶端,~表示服務節點,特別的,為主節點,為故障節點。整個協議的基本過程如下:
1)客戶端傳送請求,啟用主節點的服務操作;
2)當主節點接收請求後,啟動三階段的協議以向各從節點廣播請求;
- 序號分配階段,主節點給請求賦值一個序號,廣播序號分配訊息和客戶端的請求訊息,並將構造pre-prepare訊息給各從節點;
- 互動階段,從節點接收pre-prepare訊息,向其他服務節點廣播prepare訊息;
- 序號確認階段,各節點對檢視內的請求和次序進行驗證後,廣播commit訊息,執行收到的客戶端的請求並給客戶端響應。
3)客戶端等待來自不同節點的響應,若有個響應相同,則該響應即為運算的結果;
Raft協議
Raft是在非拜占庭故障下達成共識的強一致協議。在區塊鏈系統中,使用Raft實現記賬共識的過程可以描述如下:首先選舉一個leader,接著賦予leader完全的權利管理記賬。leader從客戶端接收記賬請求,完成記賬操作,生成區塊,並複製到其他記賬節點。有了leader簡化了記賬操作的管理。如果leader失效或與其他節點失去聯絡,這時,系統就會選出新的leader。
Raft基礎
一個Raft叢集通常包含5個伺服器,允許系統有2個故障伺服器。每個伺服器處於3個狀態之一:leader、follower或candidate。正常操作狀態下,僅有一個leader,其他的伺服器均為follower。follower是被動的,不會對自身發出的請求而是對來自leader和candidate的請求做出響應。leader處理所有的客戶端請求(若客戶端聯絡follower,則該follower將轉發給leader)。candidate狀態用來選舉leader。
Raft階段主要分為兩個,首先是leader選舉過程,然後在選舉出來的leader基礎上進行正常操作,比如日誌複製、記賬等。
leader選舉
當follower在選舉超時時間內未收到leader的心跳訊息,則轉換為candidate狀態。為了避免選舉衝突,這個超時時間是一個150~300ms之間的隨機數。
一般而言,在Raft系統中:
1)任何一個伺服器都可以成為一個候選者candidate,它向其他伺服器follower發出要求選舉自己的請求。
2)其他伺服器同意了,發出OK。如果在這個過程中,有一個follower宕機,沒有收到請求選舉的要求,此時候選者可以自己選自己,只要達到的大多數票,候選人還是可以成為leader。
3)這樣這個候選者就成為了leader領導人,它可以向follower發出指令,比如進行記賬。
4)以後可以通過心跳進行記賬的通知。
5)一旦這個leader崩潰了,那麼follower中有一個成為候選者,併發出邀票選舉。
6)follower同意後,其成為leader,繼續承擔記賬等指導工作。
記賬過程
Raft的記賬過程按以下步驟完成:
1)假設leader領導人已經選出,這時客戶端發出增加一個日誌的要求;
2)leader要求follower遵從他的指令,都將這個新的日誌內容追加到他們各自日誌中;
3)大多數follower伺服器將交易記錄寫入賬本後,確認追加成功,發出確認成功訊息;
4)在下一個心跳中,leader會通知所有follower更新確認的專案。
對於每個新的交易記錄,重複上述過程。
如果在這一過程中,發生了網路通訊故障,使得leader不能訪問大多數follower,那麼leader只能正常更新它能訪問的那些follower伺服器。而大多數的伺服器follower因為沒有了leader,它們將重新選舉一個候選者作為leader,然後這個leader作為代表與外界打交道,如果外界要求其新增新的交易記錄,這個新的leader就按上述步驟通知大多數follower,如果這時網路故障修復了,那麼原先的leader就變成follower,在失聯階段,這個老leader的任何更新都不能算確認,都回滾,接收新的leader的新更新。
PoW
PoW的原理可參看這篇博文中雜湊函式難題友好性這一節:http://blog.csdn.net/s_lisheng/article/details/77937202,理解了難題友好性,就基本理解了PoW機制的原理。結合比特幣去理解PoW。比特幣PoW的過程,就是將不同的nonce值作為輸入,嘗試進行SHA256雜湊運算,找出滿足給定數量前導0的雜湊值的過程。要求的前導0的個數越多,代表難度越大。比特幣節點求解工作量證明問題的步驟歸納如下:
1)生成鑄幣交易,並與其他所有準備打包進區塊的交易組成交易列表,通過Merkle樹演算法生成Merkle跟雜湊;
2)把Merkle根雜湊及其他相關欄位組裝成區塊頭,將區塊頭的80位元組資料作為工作量證明的輸入;
3)不停地變更區塊頭中的隨機數nonce,並對每次變更後的區塊頭做雙重SHA256運算,將結果值與當前網路的目標難度做比對,如果滿足難度條件,則解題成功,工作量證明完成。
PoS
PoW存在以下弊端:
- 礦池的出現,一定程度上違背了去中心化的初衷,同時也使得51%攻擊成為可能,影響其安全性。
- PoW存在巨大的算力浪費,看看礦池用掉多少電就知道了。
PoS(權益證明,Proof of Stake)的出現很大程度上是因為PoW的缺陷而提出的。採用PoS的幣中不同幣的PoS不完全相同,權益證明要求使用者證明擁有某些數量的貨幣(即對貨幣的權益),下面以點點幣為例,理解PoS的思想。
點點幣在SHA-256的雜湊運算的難度方便引入了幣齡的概念,使得難度與交易輸入的幣齡成反比。在點點幣中,幣齡被定義為幣的數量與幣所擁有的天數的乘積。點點幣的權益證明機制結合了隨機化與幣齡的概念,未使用至少30天的幣可以參與競爭下一區塊,越久和越大的幣集有更大的可能去簽名下一區塊。而一旦幣的權益被用於簽名一個區塊,則幣齡將清為零,這樣必須等待至少30日才能簽署另一個區塊。同時,為防止非常老或非常大的權益控制區塊鏈,尋找下一區塊的最大概率在90天后達到最大值,這一過程保護了網路,並隨著時間逐漸成為新的幣而無需消耗大量的計算能力。
DPoS
PoS機制雖然考慮了PoW的不足,但也有缺點:依據權益結餘來選擇,會導致首富賬戶的權力更大,有可能支配記賬權。股份授權證明機制(Delegated Proof of Stake,DPoS),是對PoW、PoS不足的提出的。下面以位元股為例,理解DPoS的思想。
位元股引入了見證人這個概念,見證人可以生成區塊,每一個持有位元股的人都可以投票選舉見證人。得到總同意票數中的前個(通常定義為101)候選者可以當選為見證人,當選見證人的個數需滿足:至少一半的參與投票者相信已經充分地去中心化。見證人的候選名單每個維護週期(1天)更新一次。見證人然後隨機排列,每個見證人按序有2秒的許可權時間生成區塊,若見證人在給定的時間片不能生成區塊,區塊生成許可權交給下一時間片對應的見證人。如果見證人提供的算力不穩定或計算機宕機等,持股人可以隨時通過投票更換這些見證人。
可以看到,其核心思想是通過縮小參與核心共識過程的節點數量,以提高共識效率。(這裡可以認為選舉見證人的過程為非核心共識過程,而見證人按序生成區塊可以認為是核心共識過程)