C/C++的八種排序演算法及實現
最近看排序演算法的書籍,記錄下自己的心得和總結。關於幾種常見排序的原理和實現。(快速排序借了別人的步驟描述,可以很清晰的理解每一趟怎麼跑的)
首先說下穩定排序和非穩定排序,簡單地說就是所有相等的數經過某種排序方法後,
仍能保持它們在排序之前的相對次序,我們就說這種排序方法是穩定的。反之,就是非穩定的。
幾個基本常見的排序,插入排序(包括直接插入,希爾插入,折半插入等),交換排序(包括氣泡排序,快速排序),選擇排序(簡單選擇,堆排序,樹形排序等),歸併排序,基數排序(多關鍵字,鏈式基數)。
1. 直接插入排序(穩定排序)
簡單的說就是將序列分為有序序列和無序序列。每一趟排序都是將無序序列的第一個元素插入有序序列中。R[1… i-1] <- R[i…n] , 每次取R[i]插入到R[1… i-1]中。
步驟如下:
1> 在R[1 … i-1]中找到R[i]的插入位置k (0<k<i)
2> 將R[k … i-1]均後移一位,K位置上插入R[i]
改進版:
1> 在R[1 … i-1]中將R[i]從右向左一一比較,R[j] >R[i],則R[j]後移一位(j = i-1開始)
2> 如果R[j] <=R[i],則j+1 為R[i]的插入位置
實現如下(包括測試):
<span style="font-size:14px;"> #include<iostream> using namespace std; void insert_sort(int a[],int len) { int i=0,j=0,temp=0; for(i=1;i<len;i++) { temp =a[i]; for(j=i-1;j>=0&&temp<a[j];j--) { a[j+1]=a[j]; } a[j+1]=temp; } } void print_array(int a[].int len) { for(int i=0;i<len;i++) { cout<<a[i]<<””; } cout<<endl; } int main() { inta[]={1,3,5,9,8,6,4,2,7} ; cout<<”before sort:”; print_array(a,9); insert_sort(a,9); cout<<”after sort:”; print_array(a,9); return 0; } </span>
2. 希爾排序(不穩定排序)
希爾排序演算法是先將要排序的一組數按照某個增量d分成若干組,對每組中的元素進行排序,然後在用更小的增量來進行再次分組,並給每個分組重新排序,直到增量為1時,整個要排序的數被分成一組,排序結束。
形象點說,例如[R1 ,R2 , R3, R4,R5,R6,R7,R8],先增量d =len/2 =4 ,則先分成[R1 R5] ,[R2 R6] ,[R3 R7] ,[R4 R8]四組,進行組內排序;再d=d/2 =2,分成[R1 R3 R5R7] 和 [R2 R4 R6 R8]兩組,組內排序;再d=d/2=1,整個陣列只剩一個大的分組[R1 , R2 , R3, R4,R5,R6,R7,R8],組內排序。全部結束。
實現如下(包括測試):
<span style="font-size:14px;">
#include<iostream>
using namespace std;
void shell_sort(int a[],int len)
{
int d,i,j,temp;
for(d=len/2;d>0;d=d/2)
{
for(i=d;i<len;i++)
{
temp= a[i];
for(j=i-d;j>=0&&temp<a[j];j-=d)
{
a[j+d]=a[j];
}
a[j+d]=temp;
}
}
}
void print_array(int a[],int len)
{
for(int i=0;i<len;i++)
{
cout<<a[i]<<" ";
}
cout<<endl;
}
int main()
{
inta[]={2,3,5,9,8,6,4,1,7} ;
cout<<"before sort:";
print_array(a,9);
shell_sort(a,9);
cout<<"after sort:";
print_array(a,9);
return 0;
}
</span>3. 氣泡排序(穩定排序)
氣泡排序也叫起泡排序,顧名思義,就是每一趟,從左到右,兩兩比較,大的(小的)後移,最後最輕的氣泡到最後的位置R[i],為最大或最小值,然後下一趟,選出次大的到R[i-1],以此,到最後R[1],至此全部有序。(按照遞增遞減都可以)
實現如下:
/*a[0]..從a[0]最小開始 */
<span style="font-size:14px;">
void bubble_sort(int a[],int len)
{
int i,j,temp;
for(i=0;i<len-1;i++)
{
for(j=len-2;j>=i;j--)
{
if(a[j+1]<a[j])
{
temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
}
}
}
}
/* ...a[n] ,從a[n]最大開始,*/
void bubble_sort1(int a[],int len)
{
inti,j,temp;
for(i=0;i<len-1;i++)
{
for(j=0;j<len-i-1;j++)
{
if(a[j+1]<a[j])
{
temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
}
}
}
}
//考慮如果中間的某一趟掃描之前,陣列已經全部有序,後面的掃描則沒有必要。此時可以加一個標記,來判斷是否提前結束迴圈。
改進:
void bubble_sort(int a[],int len)
{
int i,j,temp;
int exchange=0;
for(i=0;i<len-1;i++)
{
exchange = 0;
for(j=len-2;j>=i;j--)
{
if(a[j+1]<a[j])
{
temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
exchange=1; //如果發生過交換,exchange置為1
}
}
if(exchange!=1) //如果exchange為0,說明已經有序,這一趟沒發生交換,直接結束迴圈
return;
}
}
</span>4. 快速排序(不穩定排序)
快速排序是一種劃分交換排序,採用的是分治法的策略。該方法的基本思想是:
1.先從數列中取出一個數作為基準數。
2.分割槽過程,將比這個數大的數全放到它的右邊,小於或等於它的數全放到它的左邊。
3.再對左右區間重複第二步,直到各區間只有一個數。
下面藉助這篇文章的步驟描述,就會很好理解快速排序每一趟到底怎麼走的:
以一個數組作為示例,取區間第一個數為基準數(pivot)。
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
72 |
6 |
57 |
88 |
60 |
42 |
83 |
73 |
48 |
85 |
初始時,i = 0; j =9; X = a[i] = 72
由於已經將a[0]中的數儲存到X中,可以理解成在陣列a[0]上挖了個坑,可以將其它資料填充到這來。
從j開始向前找一個比X小或等於X的數。當j=8,符合條件,將a[8]挖出再填到上一個坑a[0]中。a[0]=a[8];i++; 這樣一個坑a[0]就被搞定了,但又形成了一個新坑a[8],這怎麼辦了?簡單,再找數字來填a[8]這個坑。這次從i開始向後找一個大於X的數,當i=3,符合條件,將a[3]挖出再填到上一個坑中a[8]=a[3];j--;
陣列變為:
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
48 |
6 |
57 |
88 |
60 |
42 |
83 |
73 |
88 |
85 |
i = 3; j =7; X=72
再重複上面的步驟,先從後向前找,再從前向後找。
從j開始向前找,當j=5,符合條件,將a[5]挖出填到上一個坑中,a[3] = a[5]; i++;
從i開始向後找,當i=5時,由於i==j退出。
此時,i = j = 5,而a[5]剛好又是上次挖的坑,因此將X填入a[5]。
陣列變為:
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
48 |
6 |
57 |
42 |
60 |
72 |
83 |
73 |
88 |
85 |
可以看出a[5]前面的數字都小於它,a[5]後面的數字都大於它。因此再對a[0…4]和a[6…9]這二個子區間重複上述步驟就可以了。a[5]已經確定好位置。後面每一趟也是。
對挖坑填數進行總結
1.i =L; j = R; 將基準數挖出形成第一個坑a[i]。
2.j--由後向前找比它小的數,找到後挖出此數填前一個坑a[i]中。
3.i++由前向後找比它大的數,找到後也挖出此數填到前一個坑a[j]中。
4.再重複執行2,3二步,直到i==j,將基準數填入a[i]中。
具體實現如下(測試不重複,在前面的程式碼上加個函式,都測試過):
<span style="font-size:14px;">
/*這裡的low和high是陣列的頭和尾的下標*/
void quick_sort(int a[],int low,int high)
{
int i,j,pivot;
if(low<high)
{
pivot =a[low]; //pivot的初始值為a[low]
i=low;
j=high;
while(i<j)
{
while(i<j&&a[j]>=pivot)
j--;
if(i<j)
a[i++]=a[j]; //比pivot小的元素移動到低端
while(i<j&&a[i]<=pivot)
i++;
if(i<j)
a[j--]=a[i]; //比pivot大的元素移動到高階
}
a[i]=pivot;
quick_sort(a,low,i-1); //對左右兩個子區間進行遞迴
quick_sort(a,i+1,high);
}
}
</span>erlang的快排:
myqsort([]) -> [];
myqsort([T|L]) -> myqsort([X || X <- L,X < T])
++ [T] ++
myqsort([X || X <- L,X >= T]).5. 直接選擇排序(不穩定排序)
選擇排序的基本思想:每一次從待排序的記錄中選出關鍵字最小的記錄,順序的放在有序的序列的最後,直至全部記錄排序完畢。
而直接選擇排序就是n條記錄經過n-1次後,直接得到有序記錄。
實現如下:
void select_sort(int a[],int len)
{
int i,j,min,k; //min儲存最小數,k記錄最小數的位置
for(i=0;i<len;i++)
{
min= a[i];
k =i;
for(j=i+1;j<len;j++)
{
if(a[j]<min)
{
min = a[j];
k = j;
}
}
a[k]=a[i]; //a[k]為最小值,已由min儲存
a[i]=min;
}
}
或者簡化:
void select_sort(int a[],int len)
{
int i,j,temp;
for(i=0;i<len;i++)
{
for(j=i+1;j<len;j++)
{
if(a[i]>a[j])
{
temp=a[i];
a[i]=a[j];
a[j]=temp;
}
}
}
} 6. 堆排序(不穩定排序)
堆排序是一種樹形選擇排序方法,它的特點是:在排序過程中,將A[n]看成是一棵完全二叉樹的順序儲存結構,利用完全二叉樹中雙親節點和孩子節點之間的內在關係,在當前無序區中選擇關鍵字最大(或最小)的元素。
堆的定義如下:n個關鍵字序列A[n]成為堆,當且僅當該序列滿足:
①L(i) <= L(2i)且L(i) <= L(2i+1) 或者 ②L(i) >=L(2i)且L(i) >= L(2i+1) 其中i屬於[1, n/2]。
滿足第①種情況的堆稱為小根堆(小頂堆),滿足第②種情況的堆稱為大根堆(大頂堆)。
如上的小根堆或大根堆,輸出堆頂的最小(大)值之後,使得剩下的n-1個元素的序列重新建成一個新的堆,則又得到n個數中的次小(大)值,如此反覆,最後得到的有序序列,這個過程就是堆排序。
程式碼實現:
<span style="font-size:14px;">
void swap(int *a ,int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
void HeapAdjust(int a[],int i)
{
int left = 2*i+1;//左孩子節點
int right = 2*i + 2;//右孩子節點
int max = 0;//暫存最大元素下標
if(left <=heapsize && a[left] >a[i])
max = left;
else
max = i;
if(right <= heapsize&& a[right] > a[max])
max = right;
if(max != i)//表明當前的父節點並不是最大的
{
swap(&a[i],&a[max]);
HeapAdjust(a,max);//有交換就要遞迴把子樹也整成最大堆
}
}
void BuildHeap(int a[],int len)
{
int i = 0;
heapsize = len;
for( i = len/ 2;i >=0;i--)//非葉節點最大下標為/2
{
HeapAdjust(a,i);
}
}
//堆排序對要排序的序列有個要求就是下標是從1開始到size的,而並非常用的0~size-1
void heap_sort(int a[],int len)
{
int i;
BuildHeap(a,len-1);//先建立初始的最大堆
for( i = len-1;i >=1;i--)
{
swap(&a[0],&a[i]);//把最大的元素放到最後面
heapsize--;//不再包括最大的元素
HeapAdjust(a,0);
}
//至此陣列就已經從小到大排好序了,
//如果要從大到小輸出,則倒著輸出就行了;
//而如果要將序列從大到小排序,則應建立最小堆。
}
</span>7. 歸併排序(穩定排序)
歸併是指將若干個已排序的子檔案合併成一個有序的檔案。常見的歸併排序有兩路歸併排序。它是採用分治法的。
歸併操作的基本步驟如下:
1.申請兩個與已經排序序列相同大小的空間,並將兩個序列拷貝其中;
2.設定最初位置分別為兩個已經拷貝排序序列的起始位置,比較兩個序列元素的大小,依次選擇相對小的元素放到原始序列;
3.重複2直到某一拷貝序列全部放入原始序列,將另一個序列剩下的所有元素直接複製到原始序列尾。
設歸併排序的當前區間是R[low..high],三個步驟分別是:
1.分解:將當前區間一分為二,即求分裂點
2.求解:遞迴地對兩個子區間R[low..mid]和R[mid+1..high]進行歸併排序;
3.組合:將已排序的兩個子區間R[low..mid]和R[mid+1..high]歸併為一個有序的區間R[low..high]。
遞迴的終結條件:子區間長度為1(一個記錄自然有序)。
程式碼實現:
<span style="font-size:14px;">
void Merge(int *a, int p, int q, int r)
{
int n1 = q-p+1;
int n2 = r-q;
int *L = new int[n1+1];
int *R = new int[n2+1];
int i, j, k;
for (i=0; i<n1; i++)
{
L[i] = a[p+i];
}
for (j=0; j<n2; j++)
{
R[j] = a[q+j+1];
}
L[n1] = 10000000;
R[n2] = 10000000;
for (i=0, j=0, k=p; k<=r; k++)
{
if (L[i]<=R[j])
{
a[k] = L[i];
i++;
}
else
{
a[k] = R[j];
j++;
}
}
delete []L;
delete []R;
}
void merge_sort(int *a, int p, int r) //測試時候,參為a,0,len-1
{
if (p<r)
{
int q = (p+r)/2;
merge_sort(a, p, q);
merge_sort(a, q+1, r);
merge_sort(a, p, q, r);
}
}
</span>8.基數排序(穩定排序)
實現如下:
<span style="font-size:14px;">
int maxbit(int data[], int n)
{
int d = 1; //儲存最大的位數
int p = 10;
for(int i = 0; i < n; ++i)
{
while(data[i] >= p)
{
p *= 10;
++d;
}
}
return d;
}
void radixsort(int data[], int n) //基數排序
{
int d = maxbit(data, n);
int tmp[n];
int count[10]; //計數器
int i, j, k;
int radix = 1;
for(i = 1; i <= d; i++) //進行d次排序
{
for(j = 0; j < 10; j++)
count[j] = 0; //每次分配前清空計數器
for(j = 0; j < n; j++)
{
k = (data[j] / radix) % 10; //統計每個桶中的記錄數
count[k]++;
}
for(j = 1; j < 10; j++)
count[j] = count[j - 1] + count[j]; //將tmp中的位置依次分配給每個桶
for(j = n - 1; j >= 0; j--) //將所有桶中記錄依次收集到tmp中
{
k = (data[j] / radix) % 10;
tmp[count[k] - 1] = data[j];
count[k]--;
}
for(j = 0; j < n; j++) //將臨時陣列的內容複製到data中
data[j] = tmp[j];
radix = radix * 10;
}
}
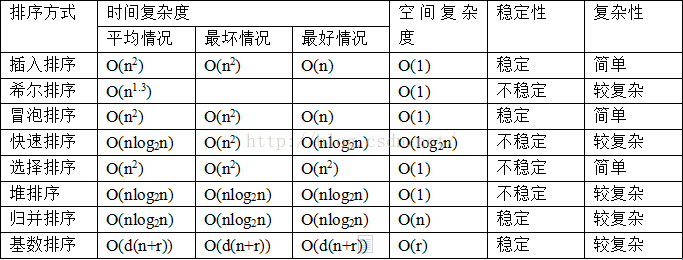
</span>總結:選擇排序、快速排序、希爾排序、堆排序不是穩定的排序演算法,
氣泡排序、插入排序、歸併排序和基數排序是穩定的排序演算法。