
大資料之nginx的安裝和使用
一:下載相關的軟體
二 :安裝:也是先解壓到指定的資料夾
三:檢查安裝環境,並指定將來要安裝的路徑
命令語句:./configure --prefix=/usr/local/nginx
四:執行上面的命令語句之後會報錯:這是對於安裝的是迷你版的xshell來說,如果是完整版的請略過
#缺包報錯 ./configure: error: C compiler cc is not found
五:裝外掛
yum -y install gcc pcre-devel openssl openssl-devel
六:
#編譯安裝
make && make install
七:編譯安裝之後也會出現一個問題

這個時候只要重新執行一下:./configure --prefix=/usr/local/nginx
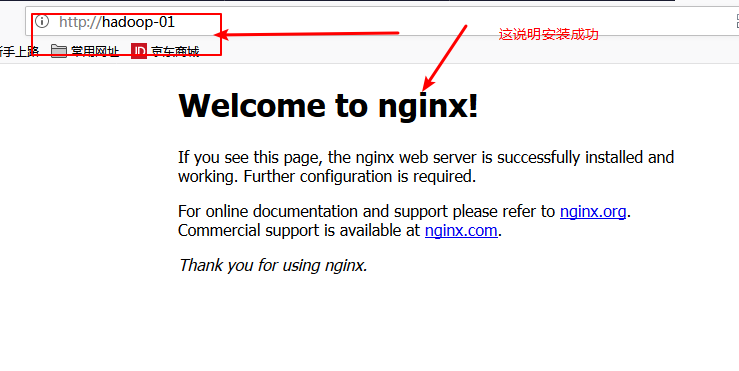
八:在瀏覽器中訪問nginx的頁面:
相關推薦
大資料之nginx的安裝和使用
一:下載相關的軟體 二 :安裝:也是先解壓到指定的資料夾 三:檢查安裝環境,並指定將來要安裝的路徑 命令語句:./configure --prefix=/usr/local/nginx 四:執行上面的命令語句之後會報錯:這是對於安裝的是迷你版的xshell來說,如果是完整版的請略過 #缺包報錯 ./
Nginx 之 Nginx安裝和配置文件簡要介紹
安裝 配置文件 1 概述本文主要介紹了nginx的兩種安裝方法,通過yum和編譯安裝,同時對安裝後的配置文件的語法和格式進行了簡要的介紹2 nginx的安裝2.1 yum安裝nginx在光盤自帶的base源裏沒有,需要通過官方路徑或者是epel源中安裝.官方:http://nginx.org/pack
大資料之nginx+js點選流日誌採集服務部署詳解
點選流日誌採集服務部署 1、伺服器中安裝依賴 yum -y install gcc perl pcre-devel openssl openssl-devel 2、上傳LuaJIT-2.0.4.tar.gz並安裝LuaJIT tar -zxvf LuaJIT-2.0.4.
大資料之scala(二) --- 對映,元組,簡單類,內部類,物件Object,Idea中安裝scala外掛,trait特質[介面],包和包的匯入
一、對映<Map> ----------------------------------------------------- 1.建立一個不可變的對映Map<k,v> ==> Map(k -> v) scala> val map
大資料之scala(一) --- 安裝scala,簡單語法介紹,條件表示式,輸入和輸出,迴圈,函式,過程,lazy ,異常,陣列
一、安裝和執行Scala解釋程式 --------------------------------------------- 1.下載scala-2.11.7.msi 2.管理員執行--安裝 3.進入scala/bin,找到scala.bat,管理員執行,進入scala命
大資料之storm(一) --- storm簡介,核心元件,工作流程,安裝和部署,電話通訊案例分析,叢集執行,單詞統計案例分析,調整併發度
一、storm簡介 --------------------------------------------------------- 1.開源,分散式,實時計算 2.實時可靠的處理無限資料流,可以使用任何語言開發 3.適用於實時分析,線上機器學習
19、大資料之Flume和Flume的安裝部署
可以實現實時傳輸,但在flume不執行和指令碼錯誤時,會丟資料,也不支援斷點續傳功能。因為沒有記錄上次檔案讀到的位置,從而沒辦法知道,下次再讀時,從什麼地方開始讀。特別是在日誌檔案一直在增加的時候。flume的source掛了。等flume的source再次開啟的這段時間內,增加的日誌內容,就沒辦法被sour
大資料之Spark(五)--- Spark的SQL模組,Spark的JDBC實現,SparkSQL整合MySQL,SparkSQL整合Hive和Beeline
一、Spqrk的SQL模組 ---------------------------------------------------------- 1.該模組能在Spack上執行Sql語句 2.可以處理廣泛的資料來源 3.DataFrame --- RDD --- tabl
大資料之Spark(一)--- Spark簡介,模組,安裝,使用,一句話實現WorldCount,API,scala程式設計,提交作業到spark叢集,指令碼分析
一、Spark簡介 ---------------------------------------------------------- 1.快如閃電的叢集計算 2.大規模快速通用的計算引擎 3.速度: 比hadoop 100x,磁碟計算快10x 4.使用: java
大資料之(6)hbase2.1.1版本全分散式安裝及使用
一、Hadoop安裝 具體請參見 https://blog.csdn.net/u011095110/article/details/83791734 二、Zookeeper分散式叢集安裝 1.Zookeeper下載 #進入hadoop主目錄 cd /hadoop #下載z
大資料之Spark(七)--- Spark機器學習,樸素貝葉斯,酒水評估和分類案例學習,垃圾郵件過濾學習案例,電商商品推薦,電影推薦學習案例
一、Saprk機器學習介紹 ------------------------------------------------------------------ 1.監督學習 a.有訓練資料集,符合規範的資料 b.根據資料集,產生一個推斷函式
大資料之Spark(八)--- Spark閉包處理,部署模式和叢集模式,SparkOnYarn模式,高可用,Spark整合Hive訪問hbase類載入等異常解決,使用spark下的thriftserv
一、Spark閉包處理 ------------------------------------------------------------ RDD,resilient distributed dataset,彈性(容錯)分散式資料集。 分割槽列表,function,dep Op
大資料之hbase(一) --- HBase介紹,特性,安裝部署,shell命令,client端與hbase的互動過程,程式設計API訪問hbase實現百萬寫入
一、HBase介紹 ---------------------------------------------- 1.基於hadoop的資料庫,具有分散式,可伸縮的大型資料儲存 2.用於對資料的隨機訪問,實時讀寫 3.巨大的表,十億行*百萬列
D001.1複製貼上玩大資料之虛擬機器的安裝
0x00 教程內容 安裝虛擬機器 NAT網路配置 0x01 安裝虛擬機器 1.獲取虛擬機器(Centos7) 官網下載() 關注公眾號:邵奈一(待補充連結),回覆:Centos7。自動獲取百度雲
我要學大資料之Linux——01 安裝系統
1、安裝VMware 收費軟體 破解版:連結:https://pan.baidu.com/s/1eF0bAuOWYU4vfeS5ttY8cg 提取碼:b6yv 比Oracle VM VirtualBox好用。 2、安裝虛擬機器 映象檔案下載地址: >
大資料之mongodb --> (1)在ubuntu上安裝mongodb
1.安裝 MongoDB。 1.為軟體包管理系統匯入公鑰。 Ubuntu 軟體包管理工具為了保證軟體包的一致性和可靠性需要用 GPG 金鑰檢驗軟體包。使用下列命令匯入 MongoDB 的 GPG 金鑰 ( MongoDB public GPG Key h
Adapter之大資料滑動效率優化和分頁載入資料
在Android中如果要做到大資料分頁載入則需要我們的Activity實現OnScrollListener滾動條監聽介面。當如果要做的更加高大上。比如需要在使用者滑動至列表的底部,觸碰摸個區域,則需要實現OnTouchListener介面,等等。
【專治不明覺厲】之“大資料” Hadoop,Spark和Storm
虎嗅注:上一篇“專治不明覺厲”文章,虎嗅君為大家介紹了“雲端計算”領域中的那些“不明覺厲”的名詞。作為雲端計算最重要的應用,大資料領域也有很多看上去“不明覺厲”的詞彙。本篇文章,虎嗅君就為各位介紹“大資料”領域裡的“不明覺厲”。 大資料(Big Data) 大資料,官
大資料之 ZooKeeper原理及其在Hadoop和HBase中的應用
ZooKeeper是一個開源的分散式協調服務,由雅虎建立,是Google Chubby的開源實現。分散式應用程式可以基於ZooKeeper實現諸如資料釋出/訂閱、負載均衡、命名服務、分散式協調/通知、叢集管理、Master選舉、分散式鎖和分散式佇列等功能。 簡介 Zo
初學大資料之模組整合:Pycharm安裝numpy,scipy,sklearn等包時遇到的各種問題的一鍵解決方法
最近在學習機器學習,要用Python寫程式,習慣了用IDE軟體,所以就使用Pycharm軟體。但是在匯入類似numpy,sklearn等模組的時候,發現了各種問題(如Python版本與模組之間的相容等各類問題),上網找了許多方法,最後總算總結出了這條最快捷的方法