
Java併發程式設計札記-(五)JUC容器-03ConcurrentHashMap
今天來學習ConcurrentHashMap在JDK1.8中的實現。相比JDK1.7,JDK1.8中ConcurrentHashMap的實現有很大的不同。
結構
先來看下JDK1.7與JDK1.8中ConcurrentHashMap結構的不同。
JDK1.7結構
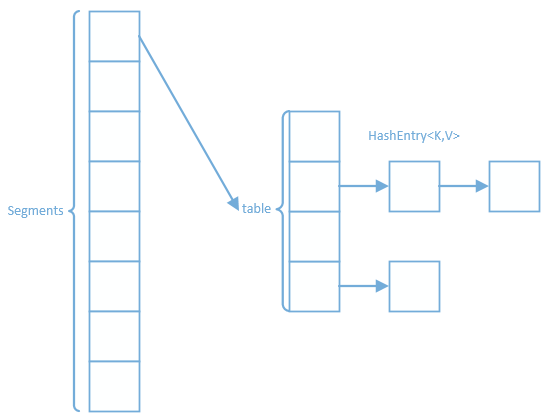
在JDK1.7中,ConcurrentHashMap通過“鎖分段”來實現執行緒安全。ConcurrentHashMap將雜湊表分成許多片段(segments),每一個片段(table)都類似於HashMap,它有一個HashEntry陣列,陣列的每項又是HashEntry組成的連結串列。每個片段都是Segment型別的,Segment繼承了ReentrantLock,所以Segment本質上是一個可重入的互斥鎖。這樣每個片段都有了一個鎖,這就是“鎖分段”。執行緒如想訪問某一key-value鍵值對,需要先獲取鍵值對所在的segment的鎖,獲取鎖後,其他執行緒就不能訪問此segment了,但可以訪問其他的segment。
JDK1.8結構
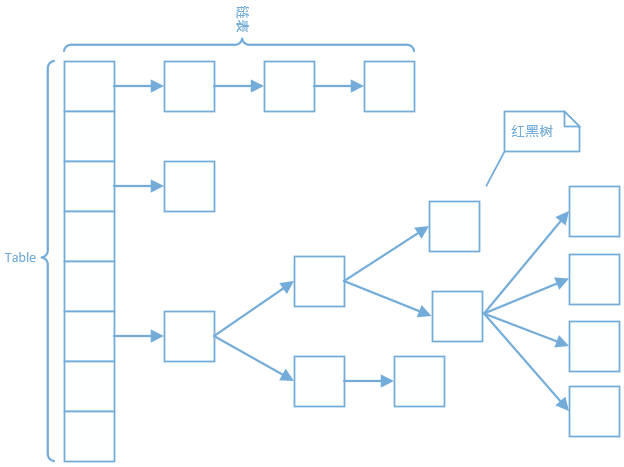
在JDK1.8中,ConcurrentHashMap放棄了“鎖分段”,取而代之的是類似於HashMap的陣列+連結串列+紅黑樹結構,使用CAS演算法和synchronized實現執行緒安全。
相關內部類
- Node。最基本的內部類,key-value鍵值對,不支援setValue方法。
- TreeNode。紅黑樹節點,供TreeBins使用。
- TreeBin。紅黑樹結構。該類並不包裝key-value鍵值對,而是TreeNode的列表和它們的根節點。這個類含有讀寫鎖。
- ForwardingNode。不是傳統的節點,不包含key-value鍵值對,包含一個nextTable指標,和find方法 。
核心方法
下面學習ConcurrentHashMap的核心方法,如get(Object)、put(K key, V value)。先來看個最簡單的get(Object)方法熱熱身。
get
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
//計算key的雜湊值
int h = spread(key.hashCode());
//如果表不為空,表長度大於0,key所在的桶的頭結點不為null
if ((tab = table) != null 可以將步驟總結如下:
- 通過key計算雜湊值
- 通過雜湊值找到桶
- 通過雜湊值和桶來查詢節點
3.1. 以此判斷桶的頭結點是不是要找的節點
3.2. 如果不是,判斷桶的頭節點的雜湊值是否小於0,如果是則說明要找的節點在樹上
3.3. 如果以上兩個條件都不滿足,則說明要找的節點在連結串列上,遍歷連結串列,查詢節點 - 如果通過以上步驟找到了節點,返回節點的value。沒找到,就返回null。
從原始碼中可以看出,上面的步驟並沒有加鎖。
put
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//計算雜湊值
int hash = spread(key.hashCode());
int binCount = 0;
//死迴圈,只有插入成功才能跳出迴圈
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果table沒有初始化,初始化table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//根據雜湊值計算在table中的位置
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//如果這個位置沒有值,直接將鍵值對放進去,不需要加鎖
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//如果要插入的位置是一個forwordingNode節點,表示正在擴容,那麼當前執行緒幫助擴容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//進行到這一步,說明要插入的位置有值,需要加鎖
synchronized (f) {
//確定f是tab中的頭節點
if (tabAt(tab, i) == f) {
//如果頭結點的雜湊值大於等於0,說明要插入的節點在連結串列中
if (fh >= 0) {
binCount = 1;
//遍歷連結串列中的所有節點
for (Node<K,V> e = f;; ++binCount) {
K ek;
//如果某一節點的key雜湊值和key與引數相等,替換節點的value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//遍歷到了最後一個節點,還沒找到key對應的節點,根據引數新建節點,插入連結串列尾部
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//如果要插入的節點在樹中,則按照樹的方式插入或替換節點
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//如果binCount不為0,說明插入或者替換操作完成了
if (binCount != 0) {
//判斷節點數量是否大於8,如果大於就需要把連結串列轉化成紅黑樹
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;//如果在連結串列中找到了指定key的節點,返回被替換的value
break;
}
}
}
//能執行到這一步,說明節點不是被替換的,是被插入的,所以要將map的元素數量加1
addCount(1L, binCount);
return null;
}可以將步驟總結如下:
- 計算key雜湊值
- 根據雜湊值計算在table中的位置
- 根據雜湊值執行插入或替換操作
3.1 如果這個位置沒有值,直接將鍵值對放進去,不需要加鎖。
3.2 如果要插入的位置是一個forwordingNode節點,表示正在擴容,那麼當前執行緒幫助擴容
3.3 加鎖。以下操作都需要加鎖。
3.4 如果要插入的節點在連結串列中,遍歷連結串列中的所有節點,如果某一節點的key雜湊值和key與引數相等,替換節點的value,記錄被替換的值;如果遍歷到了最後一個節點,還沒找到key對應的節點,根據引數新建節點,插入連結串列尾部。
3.5 如果要插入的節點在樹中,則按照樹的方式插入或替換節點。如果是替換操作,記錄被替換的值 - 判斷節點數量是否大於8,如果大於就需要把連結串列轉化成紅黑樹
- 如果操作3中執行的是替換操作,返回被替換的value。程式結束。
- 能執行到這一步,說明節點不是被替換的,是被插入的,所以要將map的元素數量加1。
可以看出,修改table結構使用了synchronized。進入addCount方法看看,
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}可以看出,修改table大小時使用了CAS演算法。
JDK1.8與JDK1.7中的ConcurrentHashMap對比
待補充
ConcurrentHashMap與HashTable的對比
HashTable通過在每個方法上加Synchronized完成同步,效率低下。ConcurrentHashMap通過在連結串列上加鎖來實現同步。相比之下ConcurrentHashMap增加了鎖的個數,從而提高了效率。
未完待續。。