
05.偽分散式、克隆、完全分散式搭建
阿新 • • 發佈:2019-01-08
Hadoop:
資料儲存模組
資料計算模組
doug cutting //hadoop之父
//分散式檔案系統GFS,可用於處理海量網頁的儲存
//分散式計算框架MAP REDUCE,可用於處理海量網頁的索引計算問題
hadoop:
GFS ====> NDFS(Nutch distributed filesystem)===> HDFS
Mapreduce ====> Mapreduce
hadoop安裝:
=========================================
本地模式:使用的儲存系統,是Linux系統
1、將安裝包通過winscp傳送到centos家目錄
2、解壓安裝包到/soft下
tar -xzvf hadoop-2.7.3.tar.gz -C /soft
3、進入到/soft下,建立符號連結
cd /soft
ln -s hadoop-2.7.3/ hadoop
4、配置環境變數 //sudo nano /etc/profile
# hadoop環境變數
export HADOOP_HOME=/soft/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5、使環境變數生效
source /etc/profile
6、驗證hadoop
hadoop version
7、測試hadoop
hdfs dfs -ls //列出
hdfs dfs -mkdir //建立資料夾
hdfs dfs -cat //檢視檔案內容
hdfs dfs -touchz //建立檔案
hdfs dfs -rm //刪除檔案
偽分散式:使用Hadoop檔案系統,只用一個主機
1、配置檔案,使hadoop三種模式共存
1)進入hadoop配置資料夾
cd /soft/hadoop/etc/
2)重新命名hadoop資料夾為local(本地模式)
mv hadoop local
3)拷貝local資料夾為pseudo和full
cp -r local pseudo
cp -r local full
4)建立hadoop符號連結指向pseudo
ln -s pseudo hadoop
2、修改配置檔案
1)進入hadoop配置資料夾
cd /soft/hadoop/etc/hadoop
2)配置檔案core-site.xml
---------------------------------------------
<?xml version="1.0"?>
<!-- value標籤需要寫本機ip -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.17.100/</value>
</property>
</configuration>
3)配置檔案hdfs-site.xml
---------------------------------------------
<?xml version="1.0"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4)配置檔案mapred-site.xml
---------------------------------------------
<?xml version="1.0"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5)配置檔案yarn-site.xml
---------------------------------------------
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.17.100</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6)修改hadoop-env.sh,修改第25行
---------------------------------------------
export JAVA_HOME=/soft/jdk
7)格式化檔案系統
---------------------------------------------
hdfs namenode -format
8)啟動hadoop
-----------------------------------------------
start-all.sh //其中要輸入多次密碼
9)通過jps檢視程序 //java process
-------------------------------------------------
4018 DataNode
4195 SecondaryNameNode
4659 NodeManager
4376 ResourceManager
3885 NameNode
4815 Jps
體驗hadoop:
====================================================
進入hadoop的web介面:
192.168.23.100:50070
列出hdfs的檔案系統
hdfs dfs -ls /
在hdfs中建立檔案
hdfs dfs -touchz /1.txt
上傳檔案到hdfs
hdfs dfs -put jdk.tar.gz /
從hdfs下載檔案
hdfs dfs -get /1.txt
體驗Mapreduce
1)建立檔案hadoop.txt並新增資料
2)將hadoop.txt上傳到hdfs
hdfs dfs -put hadoop.txt /
3)使用hadoop自帶的demo進行單詞統計
hadoop jar /soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /1.txt /out
4)通過web介面檢視hadoop執行狀態
http://192.168.23.100:8088
ssh: secure shell
===========================================
1、遠端登入
2、在遠端主機上執行命令
配置ssh免密登入
1、生成公私金鑰對
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
-t //指定演算法rsa
-P //指定一個字串進行加密
-f //指定生成檔案的位置
2、將公鑰拷貝到其他節點
ssh-copy-id [email protected]
3、測試ssh
ssh 192.168.17.100
4、停止hadoop
stop-all.sh
完全分散式:
=============================================
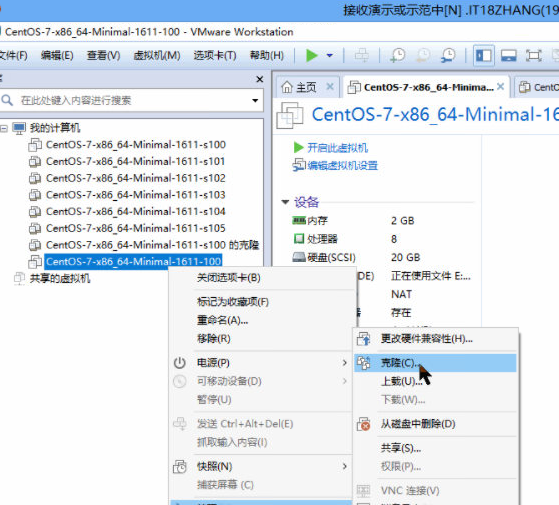
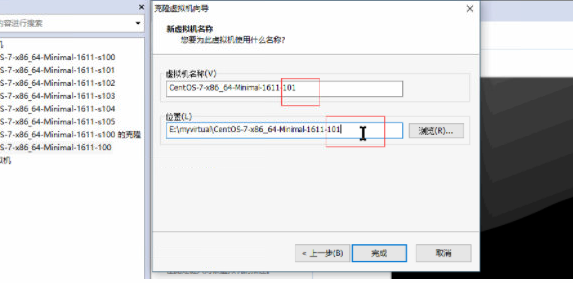
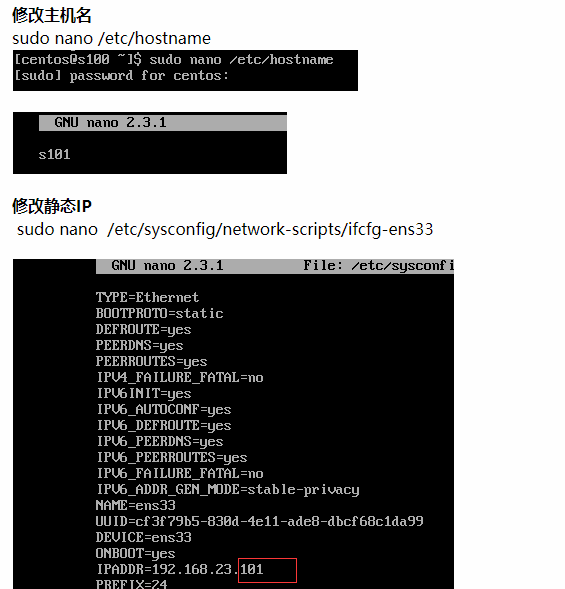
1、克隆主機 //連結克隆
2、開啟s101-s104 3、修改主機名 //sudo nano /etc/hostname 101 => s101 102 => s102 103 => s103 104 => s104 4、修改靜態ip //sudo nano /etc/sysconfig/network-scripts/ifcfg-ens33 100 => 101 100 => 102 100 => 103 100 => 104 5、重啟客戶機 reboot 6、修改hosts檔案,修改主機名和ip的對映 // sudo nano /etc/hosts 192.168.17.101 s101 192.168.17.102 s102 192.168.17.103 s103 192.168.17.104 s104 192.168.17.105 s105 7、配置s101到其他主機的免密登陸 s101 => s101 => s102 => s103 => s104 1)在s101生成公私金鑰對 ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa 2)分別將公鑰拷貝到其他節點 ssh-copy-id