
以太坊之Downloader同步區塊流程
隨著以太坊的資料越來越多,同步也越來越慢,使用full sync mode同步的話恐怕得一兩個禮拜也不見得能同步完。以太坊有fast sync mode,找了些文章還不是很明白具體內容,所以嘗試著看懂寫下來,如有錯誤之處歡迎指正。
關於fast sync mode的演算法,是在這篇文章中講述的,看完了也沒看明白為什麼同步的資料會少,速度會快,所以看看原始碼的實現吧
https://github.com/ethereum/go-ethereum/pull/1889
圖示
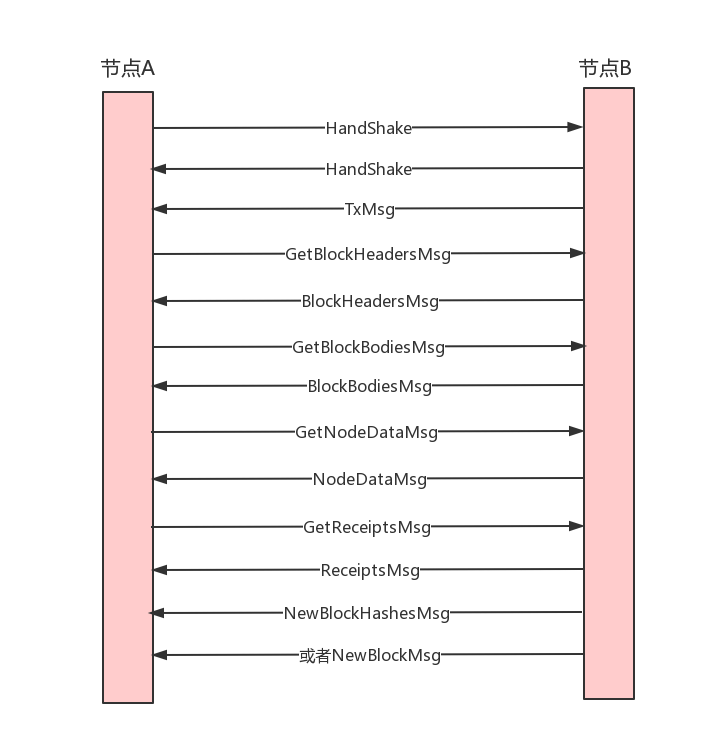
先大致講下同步流程,以新加入網路的節點A和挖礦節點B為例:
1 兩個節點先hadeshake同步下各自的genesis、td、head等資訊
2 連線成功後,節點B傳送TxMsg訊息把自己的txpool中的tx同步給節點A
然後各自迴圈監聽對方的訊息
3 節點A此時使用fast sync同步資料,依次傳送GetBlockHeadersMsg、GetBlockBodiesMsg、GetReceiptsMsg、GetNodeDataMsg獲取block header、block body、receipt和state資料
4 節點B對應的返回BlockHeadersMsg、BlockBodiesMsg、ReceiptsMsg、NodeDataMsg
5 節點A收到資料把header和body組成block存入自己的leveldb資料庫,一併存入receipts和state資料
6 節點B挖出block後會向A同步區塊,傳送NewBlockMsg或者NewBlockHashesMsg(取決於節點A位於節點B的節點列表位置),如果是NewBlockMsg,那麼節點A直接驗證完存入本地;如果是NewBlockHashesMsg節點A會交給fetcher去獲取header和body,然後再組織成block存入本地
基本概念
先簡要介紹一下一些基本概念
header:區塊的頭
body:區塊內的所有交易
block:區塊,僅包含區塊頭和body
receipt:合約執行後的結果,log就放在這裡。這個預設是不廣播的。fast sync的過程中會有節點去獲取。正常執行的節點(sync到最新後)收到block後,會執行block內的所有交易,就可以得到這個receipt了
statedb:世界狀態,儲存所有的賬號狀態,使用了MPT樹儲存。跟receipt一樣,也不屬於block的一部分,廣播的時候也不廣播。只在fast sync下,會從其他節點獲取。正常執行的節點收到block執行所有的交易的時候也可以生成。
這幾個資料都是存在節點的leveldb資料庫中,正常情況下廣播的塊是區塊,包含header和body(所有的交易)
開始
先從同步程式碼看起來吧,前面初始化的地方先不講了,直接切入正題:如果執行geth不設定同步模式,預設是fast mode
func NewProtocolManager(config *params.ChainConfig, mode downloader.SyncMode, networkId uint64, mux *event.TypeMux, txpool txPool, engine consensus.Engine, blockchain *core.BlockChain, chaindb ethdb.Database) (*ProtocolManager, error) {
// Figure out whether to allow fast sync or not
// 如果是fast sync mode,並且當前blocknum大於0,切換為full sync模式
// 那麼如果sync了一段時間斷掉之後再重新sync是fast mode還是full mode呢,答案還是fast mode
// 為什麼呢? 後面看到程式碼的時候再講一下吧
if mode == downloader.FastSync && blockchain.CurrentBlock().NumberU64() > 0 {
log.Warn("Blockchain not empty, fast sync disabled")
mode = downloader.FullSync
}
if mode == downloader.FastSync {
manager.fastSync = uint32(1)
}
// Initiate a sub-protocol for every implemented version we can handle
manager.SubProtocols = make([]p2p.Protocol, 0, len(ProtocolVersions))
for i, version := range ProtocolVersions {
// Skip protocol version if incompatible with the mode of operation
if mode == downloader.FastSync && version < eth63 {
continue
}
// Compatible; initialise the sub-protocol
version := version // Closure for the run
manager.SubProtocols = append(manager.SubProtocols, p2p.Protocol{
Name: ProtocolName,
Version: version,
Length: ProtocolLengths[i],
Run: func(p *p2p.Peer, rw p2p.MsgReadWriter) error {
peer := manager.newPeer(int(version), p, rw)
select {
case manager.newPeerCh <- peer:
manager.wg.Add(1)
defer manager.wg.Done()
return manager.handle(peer)
case <-manager.quitSync:
return p2p.DiscQuitting
}
},
NodeInfo: func() interface{} {
return manager.NodeInfo()
},
PeerInfo: func(id discover.NodeID) interface{} {
if p := manager.peers.Peer(fmt.Sprintf("%x", id[:8])); p != nil {
return p.Info()
}
return nil
},
})
}
// Construct the different synchronisation mechanisms
// 初始化downloader
manager.downloader = downloader.New(mode, chaindb, manager.eventMux, blockchain, nil, manager.removePeer)
// validator: 驗證區塊頭
validator := func(header *types.Header) error {
return engine.VerifyHeader(blockchain, header, true)
}
heighter := func() uint64 {
return blockchain.CurrentBlock().NumberU64()
}
// 將區塊插入blockchain
inserter := func(blocks types.Blocks) (int, error) {
// If fast sync is running, deny importing weird blocks
if atomic.LoadUint32(&manager.fastSync) == 1 {
log.Warn("Discarded bad propagated block", "number", blocks[0].Number(), "hash", blocks[0].Hash())
return 0, nil
}
atomic.StoreUint32(&manager.acceptTxs, 1) // Mark initial sync done on any fetcher import
return manager.blockchain.InsertChain(blocks)
}
// 初始化fetcher,把downloader、validator作為fetcher的引數
manager.fetcher = fetcher.New(blockchain.GetBlockByHash, validator, manager.BroadcastBlock, heighter, inserter, manager.removePeer)
return manager, nil
}這裡有新的節點連線成功後,會回撥這個Run函式,然後把peer寫入到manager.newPeerCh這個channel。
之前初始化的時候有個goroutine一直在監聽這個channel的資料
eth/sync.go:
func (pm *ProtocolManager) syncer() {
...
for {
select {
case <-pm.newPeerCh:
// Make sure we have peers to select from, then sync
if pm.peers.Len() < minDesiredPeerCount {
break
}
go pm.synchronise(pm.peers.BestPeer())
case <-forceSync.C:
// Force a sync even if not enough peers are present
go pm.synchronise(pm.peers.BestPeer())
case <-pm.noMorePeers:
return
}
}
}syncer()是初始化的時候的一個goroutine,一直監聽是否有新節點加入
開始同步
監聽到了有新節點連線,minDesiredPeerCount是5,意思是有5個連線了再開始sync,BestPeer是td最高的peer,就是從最長鏈的節點開始同步。
如果已經開始同步了又有新節點加入還會再同步嗎,答案是no,後面看程式碼的時候講一下
func (pm *ProtocolManager) synchronise(peer *peer) {
// Run the sync cycle, and disable fast sync if we've went past the pivot block
if err := pm.downloader.Synchronise(peer.id, pHead, pTd, mode); err != nil {
return
}
if atomic.LoadUint32(&pm.fastSync) == 1 {
log.Info("Fast sync complete, auto disabling")
atomic.StoreUint32(&pm.fastSync, 0)
}
atomic.StoreUint32(&pm.acceptTxs, 1) // Mark initial sync done
if head := pm.blockchain.CurrentBlock(); head.NumberU64() > 0 {
// We've completed a sync cycle, notify all peers of new state. This path is
// essential in star-topology networks where a gateway node needs to notify
// all its out-of-date peers of the availability of a new block. This failure
// scenario will most often crop up in private and hackathon networks with
// degenerate connectivity, but it should be healthy for the mainnet too to
// more reliably update peers or the local TD state.
go pm.BroadcastBlock(head, false)
}
}再呼叫到eth/downloader/downloader.go
func (d *Downloader) synchronise(id string, hash common.Hash, td *big.Int, mode SyncMode) error {
// 這裡保證每次只有一個sync例項執行,這裡保證了同時只有一個sync在進行
// Make sure only one goroutine is ever allowed past this point at once
if !atomic.CompareAndSwapInt32(&d.synchronising, 0, 1) {
return errBusy
}
defer atomic.StoreInt32(&d.synchronising, 0)
...
// Retrieve the origin peer and initiate the downloading process
p := d.peers.Peer(id)
if p == nil {
return errUnknownPeer
}
return d.syncWithPeer(p, hash, td)
}
func (d *Downloader) syncWithPeer(p *peerConnection, hash common.Hash, td *big.Int) (err error) {
// Look up the sync boundaries: the common ancestor and the target block
latest, err := d.fetchHeight(p)
if err != nil {
return err
}
height := latest.Number.Uint64()
origin, err := d.findAncestor(p, height)
if err != nil {
return err
}
d.syncStatsLock.Lock()
if d.syncStatsChainHeight <= origin || d.syncStatsChainOrigin > origin {
d.syncStatsChainOrigin = origin
}
d.syncStatsChainHeight = height
d.syncStatsLock.Unlock()
// Ensure our origin point is below any fast sync pivot point
pivot := uint64(0)
if d.mode == FastSync {
if height <= uint64(fsMinFullBlocks) {
// 如果對端節點的height小於64,則共同祖先更新為0
origin = 0
} else {
// 否則更新pivot為對端節點height-64
pivot = height - uint64(fsMinFullBlocks)
if pivot <= origin {
// 如果pivot小於共同祖先,則更新共同祖先為pivot的前一個
origin = pivot - 1
}
}
}
d.committed = 1
if d.mode == FastSync && pivot != 0 {
d.committed = 0
}
// Initiate the sync using a concurrent header and content retrieval algorithm
// 更新queue的值從共同祖先+1開始,這個好理解,就是從共同祖先開始sync區塊
d.queue.Prepare(origin+1, d.mode)
if d.syncInitHook != nil {
d.syncInitHook(origin, height)
}
fetchers := []func() error{
func() error { return d.fetchHeaders(p, origin+1, pivot) }, // Headers are always retrieved
func() error { return d.fetchBodies(origin + 1) }, // Bodies are retrieved during normal and fast sync
func() error { return d.fetchReceipts(origin + 1) }, // Receipts are retrieved during fast sync
func() error { return d.processHeaders(origin+1, pivot, td) },
}
if d.mode == FastSync {
fetchers = append(fetchers, func() error { return d.processFastSyncContent(latest) })
} else if d.mode == FullSync {
fetchers = append(fetchers, d.processFullSyncContent)
}
return d.spawnSync(fetchers)
}1 fetchHeight(p):從節點p根據head hash(建立節點handshake的時候節點p傳過來的最新的head hash)獲取header,傳送GetBlockHeadersMsg訊息,節點p收到訊息後從自己本地拿到header然後傳送BlockHeaderMsg訊息,當前節點一直等待知道收到header的訊息。
2 findAncestor(p):從節點p尋找共同的祖先header。也是傳送GetBlockHeadersMsg訊息,帶的引數是算出來的從某個高度拿某些數量的headers。拿到headers後從最新的header往前for迴圈,看本地的lightchain是否有這個header,有的話就找到了共同祖先。如果未找到,再從創世快開始二分法查詢是否能找到共同的祖先,然後返回這個共同的祖先origin(是header)
3 拿到最新origin後,更新queue從共同祖先開始sync,呼叫spawnSync開始同步
func (d *Downloader) spawnSync(fetchers []func() error) error {
errc := make(chan error, len(fetchers))
d.cancelWg.Add(len(fetchers))
for _, fn := range fetchers {
fn := fn
go func() { defer d.cancelWg.Done(); errc <- fn() }()
}
// Wait for the first error, then terminate the others.
var err error
for i := 0; i < len(fetchers); i++ {
if i == len(fetchers)-1 {
// Close the queue when all fetchers have exited.
// This will cause the block processor to end when
// it has processed the queue.
d.queue.Close()
}
if err = <-errc; err != nil {
break
}
}
d.queue.Close()
d.Cancel()
return err
}這個函式的主要功能是:
1 迴圈執行fetchers,fetchers是上面傳過來的一組函式,fetch header、fetch body、 fetch receipt、process header等
2 然後等待讀取errc channel內容,等待sync完成。注意這裡errc是一個緩衝channel,個數為fetchers的長度,就是會等待fetchers中的每個函式執行完成返回。所以這裡實現了pending的效果,就是一直要等到sync完成才會結束sync
3 如果fast sync的話,fetchers的最後一個函式是processFastSyncContent();full sync模式下最後一個函式是processFullSyncContent()
同步State
state是世界狀態,儲存著所有賬戶的餘額等資訊
func (d *Downloader) processFastSyncContent(latest *types.Header) error {
// Start syncing state of the reported head block. This should get us most of
// the state of the pivot block.
stateSync := d.syncState(latest.Root)
defer stateSync.Cancel()
go func() {
if err := stateSync.Wait(); err != nil && err != errCancelStateFetch {
d.queue.Close() // wake up WaitResults
}
}()
// Figure out the ideal pivot block. Note, that this goalpost may move if the
// sync takes long enough for the chain head to move significantly.
pivot := uint64(0)
if height := latest.Number.Uint64(); height > uint64(fsMinFullBlocks) {
pivot = height - uint64(fsMinFullBlocks)
}
// To cater for moving pivot points, track the pivot block and subsequently
// accumulated download results separately.
var (
oldPivot *fetchResult // Locked in pivot block, might change eventually
oldTail []*fetchResult // Downloaded content after the pivot
)
for {
// Wait for the next batch of downloaded data to be available, and if the pivot
// block became stale, move the goalpost
results := d.queue.Results(oldPivot == nil) // Block if we're not monitoring pivot staleness
if len(results) == 0 {
// If pivot sync is done, stop
if oldPivot == nil {
return stateSync.Cancel()
}
// If sync failed, stop
select {
case <-d.cancelCh:
return stateSync.Cancel()
default:
}
}
if d.chainInsertHook != nil {
d.chainInsertHook(results)
}
if oldPivot != nil {
results = append(append([]*fetchResult{oldPivot}, oldTail...), results...)
}
// Split around the pivot block and process the two sides via fast/full sync
if atomic.LoadInt32(&d.committed) == 0 {
latest = results[len(results)-1].Header
if height := latest.Number.Uint64(); height > pivot+2*uint64(fsMinFullBlocks) {
log.Warn("Pivot became stale, moving", "old", pivot, "new", height-uint64(fsMinFullBlocks))
pivot = height - uint64(fsMinFullBlocks)
}
}
P, beforeP, afterP := splitAroundPivot(pivot, results)
if err := d.commitFastSyncData(beforeP, stateSync); err != nil {
return err
}
if P != nil {
// If new pivot block found, cancel old state retrieval and restart
if oldPivot != P {
stateSync.Cancel()
stateSync = d.syncState(P.Header.Root)
defer stateSync.Cancel()
go func() {
if err := stateSync.Wait(); err != nil && err != errCancelStateFetch {
d.queue.Close() // wake up WaitResults
}
}()
oldPivot = P
}
// Wait for completion, occasionally checking for pivot staleness
select {
case <-stateSync.done:
if stateSync.err != nil {
return stateSync.err
}
if err := d.commitPivotBlock(P); err != nil {
return err
}
oldPivot = nil
case <-time.After(time.Second):
oldTail = afterP
continue
}
}
// Fast sync done, pivot commit done, full import
if err := d.importBlockResults(afterP); err != nil {
return err
}
}
}1 引數latest是剛才從對端節點獲取到的最新的header,
2 syncState函式建立了stateSync結構,然後寫到channel stateSyncStart
3 初始化建立downloader的時候建立的goroutine statefetcher()監聽到此channel有資料就開始進行state sync
func (d *Downloader) stateFetcher() {
for {
select {
case s := <-d.stateSyncStart: for next := s; next != nil; {
next = d.runStateSync(next)
}
case <-d.stateCh:
// Ignore state responses while no sync is running.
case <-d.quitCh:
return
}
}
}eth/downloader/statesync.go:
runStateSync()建立了goroutine s.run(),內部呼叫loop函式:
func (s *stateSync) loop() (err error) {
// Listen for new peer events to assign tasks to them
newPeer := make(chan *peerConnection, 1024)
peerSub := s.d.peers.SubscribeNewPeers(newPeer)
defer peerSub.Unsubscribe()
defer func() {
cerr := s.commit(true)
if err == nil {
err = cerr
}
}()
// Keep assigning new tasks until the sync completes or aborts
for s.sched.Pending() > 0 {
if err = s.commit(false); err != nil {
return err
}
s.assignTasks()
// Tasks assigned, wait for something to happen
select {
case <-newPeer:
// New peer arrived, try to assign it download tasks
case <-s.cancel:
return errCancelStateFetch
case <-s.d.cancelCh:
return errCancelStateFetch
case req := <-s.deliver:
// Response, disconnect or timeout triggered, drop the peer if stalling
log.Trace("Received node data response", "peer", req.peer.id, "count", len(req.response), "dropped", req.dropped, "timeout", !req.dropped && req.timedOut())
if len(req.items) <= 2 && !req.dropped && req.timedOut() {
// 2 items are the minimum requested, if even that times out, we've no use of
// this peer at the moment.
log.Warn("Stalling state sync, dropping peer", "peer", req.peer.id)
s.d.dropPeer(req.peer.id)
}
// Process all the received blobs and check for stale delivery
if err = s.process(req); err != nil {
log.Warn("Node data write error", "err", err)
return err
}
req.peer.SetNodeDataIdle(len(req.response))
}
}
return nil
}這段程式碼以及子函式assignTasks的作用:
1 從所有空閒的peer節點開始獲取state狀態,傳送GetNodeDataMsg資料。
2 對端節點收到此訊息後,返回NodeDataMsg包括一定數量的state資料
3 本節點收到NodeDataMsg後,把資料寫到channel stateCh
4 runStateSync()函式監聽此channel的資料,寫入finished結構內(也是stateReq型別),然後再寫入channel s.deliver中
5 剛才傳送GetNodeDataMsg的函式loop()內在監聽channel s.deliver,拿到資料後呼叫process函式
(由於程式碼太多,暫不貼上來,可以自行到程式碼中根據函式名搜尋即可)
6 procress()函式處理收到的state資料,寫入本地(先寫入memory,後續Commit的時候一起寫入leveldb資料庫)
7 然後設定peer為idle後續繼續請求state資料
同步Headers
上面fetchers中呼叫fetchHeaders同步header
func (d *Downloader) fetchHeaders(p *peerConnection, from uint64, pivot uint64) error {
// 預設skeleton為true,表示先獲取骨架(間隔的headers),然後再從其他節點填充骨架間的headers
skeleton := true
getHeaders := func(from uint64) {
request = time.Now()
ttl = d.requestTTL()
timeout.Reset(ttl)
if skeleton {
// 看引數MaxHeaderFetch-1(跳躍的距離),獲取的header是跳躍的
go p.peer.RequestHeadersByNumber(from+uint64(MaxHeaderFetch)-1, MaxSkeletonSize, MaxHeaderFetch-1, false)
} else {
// 獲取骨架完成或者失敗,順序獲取headers
go p.peer.RequestHeadersByNumber(from, MaxHeaderFetch, 0, false)
}
}
// Start pulling the header chain skeleton until all is done
getHeaders(from)
for {
select {
case <-d.cancelCh:
return errCancelHeaderFetch
// 從對端節點獲取header後會寫到channel headerCh
case packet := <-d.headerCh:
// If the skeleton's finished, pull any remaining head headers directly from the origin
// 如果獲取skeleton完成,設定skeleton為false,順序獲取
if packet.Items() == 0 && skeleton {
skeleton = false
getHeaders(from)
continue
}
// If no more headers are inbound, notify the content fetchers and return
...
headers := packet.(*headerPack).headers
// If we received a skeleton batch, resolve internals concurrently
// 如果獲取了一些header的骨架,開始填充
if skeleton {
filled, proced, err := d.fillHeaderSkeleton(from, headers)
if err != nil {
p.log.Debug("Skeleton chain invalid", "err", err)
return errInvalidChain
}
headers = filled[proced:]
from += uint64(proced)
}
// Insert all the new headers and fetch the next batch
if len(headers) > 0 {
p.log.Trace("Scheduling new headers", "count", len(headers), "from", from)
select {
case d.headerProcCh <- headers:
case <-d.cancelCh:
return errCancelHeaderFetch
}
from += uint64(len(headers))
}
getHeaders(from)
}
}
}1 先從當前peer獲取一組有間隔的headers,稱謂骨架
2 然後找其他節點填充headers骨架使連續
3 填充完畢後,headers後寫入channel headerProcCh(下面的處理headers中處理),同時把from賦值為新的from,然後進行下一批headers的獲取
處理Headers
func (d *Downloader) processHeaders(origin uint64, pivot uint64, td *big.Int) error {
for {
select {
case <-d.cancelCh:
return errCancelHeaderProcessing
case headers := <-d.headerProcCh:
// Otherwise split the chunk of headers into batches and process them
gotHeaders = true
for len(headers) > 0 {
// Terminate if something failed in between processing chunks
select {
case <-d.cancelCh:
return errCancelHeaderProcessing
default:
}
// Select the next chunk of headers to import
limit := maxHeadersProcess
if limit > len(headers) {
limit = len(headers)
}
chunk := headers[:limit]
// In case of header only syncing, validate the chunk immediately
if d.mode == FastSync || d.mode == LightSync {
// Collect the yet unknown headers to mark them as uncertain
unknown := make([]*types.Header, 0, len(headers))
for _, header := range chunk {
if !d.lightchain.HasHeader(header.Hash(), header.Number.Uint64()) {
unknown = append(unknown, header)
}
}
// If we're importing pure headers, verify based on their recentness
frequency := fsHeaderCheckFrequency
if chunk[len(chunk)-1].Number.Uint64()+uint64(fsHeaderForceVerify) > pivot {
frequency = 1
}
if n, err := d.lightchain.InsertHeaderChain(chunk, frequency); err != nil {
// If some headers were inserted, add them too to the rollback list
if n > 0 {
rollback = append(rollback, chunk[:n]...)
}
log.Debug("Invalid header encountered", "number", chunk[n].Number, "hash", chunk[n].Hash(), "err", err)
return errInvalidChain
}
// All verifications passed, store newly found uncertain headers
rollback = append(rollback, unknown...)
if len(rollback) > fsHeaderSafetyNet {
rollback = append(rollback[:0], rollback[len(rollback)-fsHeaderSafetyNet:]...)
}
}
// Unless we're doing light chains, schedule the headers for associated content retrieval
if d.mode == FullSync || d.mode == FastSync {
// If we've reached the allowed number of pending headers, stall a bit
for d.queue.PendingBlocks() >= maxQueuedHeaders || d.queue.PendingReceipts() >= maxQueuedHeaders {
select {
case <-d.cancelCh:
return errCancelHeaderProcessing
case <-time.After(time.Second):
}
}
// Otherwise insert the headers for content retrieval
inserts := d.queue.Schedule(chunk, origin)
if len(inserts) != len(chunk) {
log.Debug("Stale headers")
return errBadPeer
}
}
headers = headers[limit:]
origin += uint64(limit)
}
}
}
}1 收到headers後,如果是fast或者light sync,每1K個header處理,呼叫lightchain.InsertHeaderChain()寫入header到leveldb資料庫
2 然後如果當前是fast或者full sync模式後,d.queue.Schedule(chunk, origin)賦值blockTaskPool/blockTaskQueue和receiptTaskPool/receiptTaskQueue(only fast 模式下),供後續同步body和同步receipt使用
同步Body
上面fetchers中呼叫fetchBodies同步body
func (d *Downloader) fetchBodies(from uint64) error {
log.Debug("Downloading block bodies", "origin", from)
var (
deliver = func(packet dataPack) (int, error) {
pack := packet.(*bodyPack)
return d.queue.DeliverBodies(pack.peerId, pack.transactions, pack.uncles)
}
expire = func() map[string]int { return d.queue.ExpireBodies(d.requestTTL()) }
fetch = func(p *peerConnection, req *fetchRequest) error { return p.FetchBodies(req) }
capacity = func(p *peerConnection) int { return p.BlockCapacity(d.requestRTT()) }
setIdle = func(p *peerConnection, accepted int) { p.SetBodiesIdle(accepted) }
)
err := d.fetchParts(errCancelBodyFetch, d.bodyCh, deliver, d.bodyWakeCh, expire,
d.queue.PendingBlocks, d.queue.InFlightBlocks, d.queue.ShouldThrottleBlocks, d.queue.ReserveBodies,
d.bodyFetchHook, fetch, d.queue.CancelBodies, capacity, d.peers.BodyIdlePeers, setIdle, "bodies")
log.Debug("Block body download terminated", "err", err)
return err
}1 從pool中取出要同步的body
2 呼叫fetch,也就是呼叫這裡的FetchBodies從節點獲取body,傳送GetBlockBodiesMsg訊息
3 對端節點處理完成後發回訊息BlockBodiesMsg,寫入channel bodyCh
4 收到channel bodyCh的資料後,呼叫deliver函式
所以接著看下deliver函式中d.queue.DeliverReceipts的程式碼
func (q *queue) DeliverBodies(id string, txLists [][]*types.Transaction, uncleLists [][]*types.Header) (int, error) {
q.lock.Lock()
defer q.lock.Unlock()
reconstruct := func(header *types.Header, index int, result *fetchResult) error {
if types.DeriveSha(types.Transactions(txLists[index])) != header.TxHash || types.CalcUncleHash(uncleLists[index]) != header.UncleHash {
return errInvalidBody
}
result.Transactions = txLists[index]
result.Uncles = uncleLists[index]
return nil
}
return q.deliver(id, q.blockTaskPool, q.blockTaskQueue, q.blockPendPool, q.blockDonePool, bodyReqTimer, len(txLists), reconstruct)
}1 這裡用到了處理header時中賦值的blockTaskPool和blockTaskQueue
2 q.deliver中用到了這裡定義的reconstruct函式,把body存入resultCache中的Transactions和Uncles
3 下面處理Content的時候會用到這個Transactions和Uncles
同步Receipt
上面fetchers中呼叫fetchReceipts同步receipts
func (d *Downloader) fetchReceipts(from uint64) error {
log.Debug("Downloading transaction receipts", "origin", from)
var (
deliver = func(packet dataPack) (int, error) {
pack := packet.(*receiptPack)
return d.queue.DeliverReceipts(pack.peerId, pack.receipts)
}
expire = func() map[string]int { return d.queue.ExpireReceipts(d.requestTTL()) }
fetch = func(p *peerConnection, req *fetchRequest) error { return p.FetchReceipts(req) }
capacity = func(p *peerConnection) int { return p.ReceiptCapacity(d.requestRTT()) }
setIdle = func(p *peerConnection, accepted int) { p.SetReceiptsIdle(accepted) }
)
err := d.fetchParts(errCancelReceiptFetch, d.receiptCh, deliver, d.receiptWakeCh, expire,
d.queue.PendingReceipts, d.queue.InFlightReceipts, d.queue.ShouldThrottleReceipts, d.queue.ReserveReceipts,
d.receiptFetchHook, fetch, d.queue.CancelReceipts, capacity, d.peers.ReceiptIdlePeers, setIdle, "receipts")
log.Debug("Transaction receipt download terminated", "err", err)
return err
}程式碼跟fetchBodies中的類似:
1 從pool中取出要同步的receipts
2 呼叫fetch,也就是呼叫這裡的FetchReceipts從節點獲取receipts,傳送GetReceiptsMsg訊息
3 對端節點處理完成後發回訊息ReceiptsMsg,寫入channel receiptCh
4 收到channel receiptCh的資料後,呼叫deliver函式
看下deliver函式中的d.queue.DeliverReceipts函式func (q *queue) DeliverReceipts(id string, receiptList [][]*types.Receipt) (int, error) {
q.lock.Lock()
defer q.lock.Unlock()
reconstruct := func(header *types.Header, index int, result *fetchResult) error {
if types.DeriveSha(types.Receipts(receiptList[index])) != header.ReceiptHash {
return errInvalidReceipt
}
result.Receipts = receiptList[index]
return nil
}
return q.deliver(id, q.receiptTaskPool, q.receiptTaskQueue, q.receiptPendPool, q.receiptDonePool, receiptReqTimer, len(receiptList), reconstruct)
}1 這裡用到了處理header中的receiptTaskPool和receiptTaskQueue
2 q.deliver中用到了這裡定義的reconstruct函式,把receipts存入resultCache中的Receipts
3 後續處理Content的時候拿到Receipts然後寫入本地leveldb
處理Content
這裡的作用是把block和receipts寫入本地的leveldb
fast sync模式下呼叫的函式是processFastSyncContent
full sync模式下呼叫的函式是processFullSyncContent
先看下full模式下processFullSyncContent的程式碼:
func (d *Downloader) processFullSyncContent() error {
for {
results := d.queue.Results(true)
if len(results) == 0 {
return nil
}
if d.chainInsertHook != nil {
d.chainInsertHook(results)
}
if err := d.importBlockResults(results); err != nil {
return err
}
}
}1 d.queue.Results()函式從上面的resultCache中拿到儲存的內容
2 improtBlockResults()中根據results的header,body組織成block,然後d.blockchain.InsertChain(blocks)寫block到本地的leveldb
再看下fast sync的processFastSyncContent函式:func (d *Downloader) processFastSyncContent(latest *types.Header) error {
// Start syncing state of the reported head block. This should get us most of
// the state of the pivot block.
stateSync := d.syncState(latest.Root)
defer stateSync.Cancel()
go func() {
if err := stateSync.Wait(); err != nil && err != errCancelStateFetch {
d.queue.Close() // wake up WaitResults
}
}()
// Figure out the ideal pivot block. Note, that this goalpost may move if the
// sync takes long enough for the chain head to move significantly.
pivot := uint64(0)
if height := latest.Number.Uint64(); height > uint64(fsMinFullBlocks) {
pivot = height - uint64(fsMinFullBlocks)
}
// To cater for moving pivot points, track the pivot block and subsequently
// accumulated download results separately.
var (
oldPivot *fetchResult // Locked in pivot block, might change eventually
oldTail []*fetchResult // Downloaded content after the pivot
)
for {
// Wait for the next batch of downloaded data to be available, and if the pivot
// block became stale, move the goalpost
results := d.queue.Results(oldPivot == nil) // Block if we're not monitoring pivot staleness
if len(results) == 0 {
// If pivot sync is done, stop
if oldPivot == nil {
return stateSync.Cancel()
}
// If sync failed, stop
select {
case <-d.cancelCh:
return stateSync.Cancel()
default:
}
}
if d.chainInsertHook != nil {
d.chainInsertHook(results)
}
if oldPivot != nil {
results = append(append([]*fetchResult{oldPivot}, oldTail...), results...)
}
// Split around the pivot block and process the two sides via fast/full sync
if atomic.LoadInt32(&d.committed) == 0 {
latest = results[len(results)-1].Header
if height := latest.Number.Uint64(); height > pivot+2*uint64(fsMinFullBlocks) {
log.Warn("Pivot became stale, moving", "old", pivot, "new", height-uint64(fsMinFullBlocks))
pivot = height - uint64(fsMinFullBlocks)
}
}
P, beforeP, afterP := splitAroundPivot(pivot, results)
if err := d.commitFastSyncData(beforeP, stateSync); err != nil {
return err
}
if P != nil {
// If new pivot block found, cancel old state retrieval and restart
if oldPivot != P {
stateSync.Cancel()
stateSync = d.syncState(P.Header.Root)
defer stateSync.Cancel()
go func() {
if err := stateSync.Wait(); err != nil && err != errCancelStateFetch {
d.queue.Close() // wake up WaitResults
}
}()
oldPivot = P
}
// Wait for completion, occasionally checking for pivot staleness
select {
case <-stateSync.done:
if stateSync.err != nil {
return stateSync.err
}
if err := d.commitPivotBlock(P); err != nil {
return err
}
oldPivot = nil
case <-time.After(time.Second):
oldTail = afterP
continue
}
}
// Fast sync done, pivot commit done, full import
if err := d.importBlockResults(afterP); err != nil {
return err
}
}
}其中commitFastSyncData就是組織headers、receipts和body到block然後寫入本地leveldb中,呼叫函式:
d.blockchain.InsertReceiptChain(blocks, receipts),連同receipt一起寫入本地
同步結束
再看下上面講的開始sync的地方:
func (pm *ProtocolManager) synchronise(peer *peer) {
// Run the sync cycle, and disable fast sync if we've went past the pivot block
if err := pm.downloader.Synchronise(peer.id, pHead, pTd, mode); err != nil {
return
}
if atomic.LoadUint32(&pm.fastSync) == 1 {
log.Info("Fast sync complete, auto disabling")
atomic.StoreUint32(&pm.fastSync, 0)
}
atomic.StoreUint32(&pm.acceptTxs, 1) // Mark initial sync done
if head := pm.blockchain.CurrentBlock(); head.NumberU64() > 0 {
// We've completed a sync cycle, notify all peers of new state. This path is
// essential in star-topology networks where a gateway node needs to notify
// all its out-of-date peers of the availability of a new block. This failure
// scenario will most often crop up in private and hackathon networks with
// degenerate connectivity, but it should be healthy for the mainnet too to
// more reliably update peers or the local TD state.
go pm.BroadcastBlock(head, false)
}
}1 pm.downloader.Synchronise()結束的時候也就sync完成了
2 pm.fastSync置為0,退出fast sync模式了
3 拿出最新的head,廣播自己的最新block,開始到正常工作模式。下面再寫一篇文章講解下同步完成之後的工作
總結
1 節點同步的時候預設是fast同步模式
2 程式碼中用到了大量的go和channel的讀寫,實現非同步通訊,這也是go語言的優勢所在,很方便
3 fast 同步過程中從td最高的節點獲取header、body、receipt和state然後寫入本地的leveldb資料庫中
4 同步到最新之後退出fast sync模式
Fast模式快的原因是,直接同步了state資料和receipt資料,取代比較耗時的執行交易的過程,所以同步要比full mode要快。原則上fast sync同步的資料要比full sync同步的資料要多,這篇文章(https://github.com/ethereum/go-ethereum/pull/1889)寫到的最終fast sync資料比full sync的資料少,應該是執行交易的過程中生成的資料要比最終使用的多一點