
windows下安裝hadoop2.9.1並在Hadoop上執行myeclipse專案
首先首先要安裝Java
首先,到官網下載Hadoop安裝包:
http://hadoop.apache.org/->左邊點Releases->點mirror site->點http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common->下載hadoop-2.9.1.tar.gz
然後,解壓到自己喜歡的資料夾即可,我的是路徑是E:\hadoop-2.9.1,到http://download.csdn.net/detail/wuxun1997/9841472下載相關工具類(別人的,很好用),直接解壓後把檔案丟到E:\hadoop-2.9.1\bin,將其中的hadoop.dll在c:\windows/System32下也丟一份;接著設定環境Hadoop的環境變數
接下來做配置(最簡單配置)
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop/data/dfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop/data/dfs/datanode</value> </property> </configuration>
mapred-site.xml(複製mapred-site-template檔案修改檔名即可)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
接下來,進入到etc\hadoop中,修改hadoop-env.cmd中的java路徑為你安裝Java的路徑
配置完成
準備啟動Hadoop
進入bin,執行hdfs namenode -format(以後再啟動Hadoop就不要執行這個命令,否則可能報錯)。進入sbin目錄,執行start-all.cmd,出現四個介面,最後輸入jps可以看到啟動的節點:
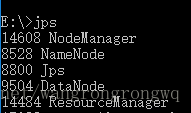
至此,Hadoop就啟動完成了,這個時候Hadoop裡面什麼檔案都沒有,自己可以通過hadoop fs -ls .來檢視
接下來在myeclipse中編寫mapreduce程式
新建maven專案
在WordCount.java中放入下面程式碼:
package hadoop;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount {
public static class Map extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
在pom.xml中放入下面程式碼段:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>HadoopJar</groupId>
<artifactId>Hadoop</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>Hadoop</name>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>net.minidev</groupId>
<artifactId>json-smart</artifactId>
<version>2.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.9.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.9.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.9.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-jobclient -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
<build>
<finalName>Hadoop</finalName>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<configuration>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>將專案打包成jar,打包maven專案成Jar有兩種方式,第一種右擊專案->export->jar file後面設定jar名和儲存路徑即可,第二種右擊專案->run as ->maven install後面東西自己設定即可。
接下來在本地建立目錄input在該目錄下建立兩個文字檔案,在hadoop上建立目錄input,在input中上傳本地的兩個文字檔案如下:
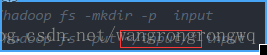
紅框處根據自己的本地input目錄所在路徑而定
兩個文字檔案的內容分別為hello world和hello hadoop
上傳jar包到Hadoop上,與上傳文字檔案相同,在Hadoop上執行jar包
紅框處 是主函式所在的類,執行完畢看結果(ouput資料夾之前不存在,執行之後才生成)

統計出了單詞的數量,至於命令列的編寫還是很不懂
還有一種執行mapreduce專案的方法,是在eclipse中裝Hadoop外掛,待續