
R︱高效資料操作——data.table包(實戰心得、dplyr對比、key靈活用法、資料合併)
每每以為攀得眾山小,可、每每又切實來到起點,大牛們,緩緩腳步來俺筆記葩分享一下吧,please~

———————————————————————————
由於業務中接觸的資料量很大,於是不得不轉戰開始尋求資料操作的效率。於是,data.table這個包就可以很好的滿足對大資料量的資料操作的需求。
data.table可是比dplyr以及Python中的pandas還好用的資料處理方式。
網路上充斥的是data.table很好,很棒,效能棒之類的,但是從我實際使用來看,就得潑個水,網上部落格都是拿一些簡單的案例資料,但是實際資料結構很複雜的情況下,批量操作對於data.table編碼來說,會顯得很繁瑣,相比來說,讓我多等1分鐘的data.frame結構,我還是願意等的。
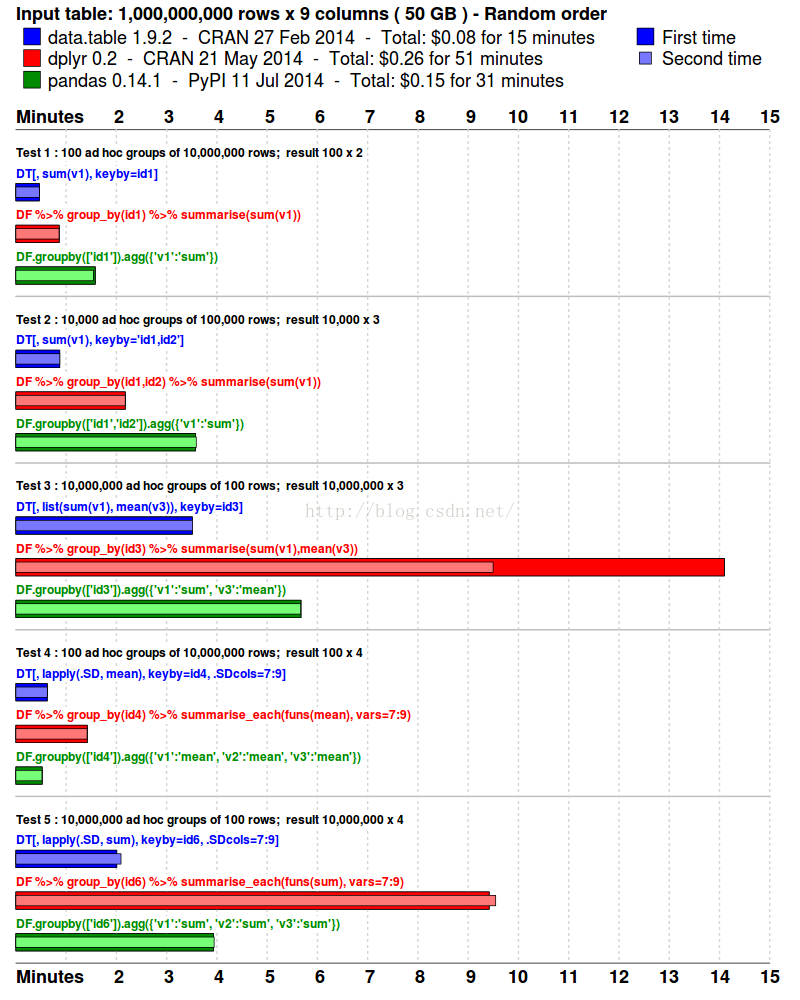
data.table包的語法簡潔,並且只需一行程式碼就可以完成很多事情。進一步地,data.table在某些情況下執行效率更高。(參考來源:)
在使用data.table時候,需要預先佈置一下環境:
[html] view plain copy print?- data<-data.table(data)
如果不佈置環境,很多內容用不了。或者通過as.data.table的操作來構建資料集。
一些老式的資料操作方法可以見我的其他部落格:
同時,data.table與data.frame資料呈現方面,還有有所不同的。
data.table包提供了一個非常簡潔的通用格式:DT[i,j,by]
注意:
data.table之後,一些常規的data.frame的操作就失效了,譬如:
data[,-1]、data[,1]這樣的操作就不是這麼用的了。
——————————————————————————————————————————————
一、重要的key()
data.table中的key是整個框架裡面的靈魂,通過設定,data.table整個資料就會按照key變數重新排序。這意味著,輸出的資料也是按照某種規律的,而且通過設定了Key,配套的程式碼編譯也受到了簡化。
設定key的方式有很多種:
1、建立資料時直接設定key
dt <- data.table(a=c('A','B','C','A','A','B'),b=rnorm(6),key="a")
2、setkey()函式設定
setkey(dt,a)setkey(DT, colA, colB),可以使得檢索和分組更加快速。同時設定兩個key變數的方式,也是可以的。
檢視資料集是否有key的方式:
key(data) #檢查該資料集key是什麼?
haskey(data) #檢查是否有Key
attributes(data)
key()可以告訴你,資料集中的Key是哪幾個變數?
haskey()輸出結果為:true/false
——————————————————————————————————————————————
二、資料篩選
1、列篩選 .()
from_dplyr = select(tb, ID)
from_data_table = tb[,"ID"]
from_data_table = tb[,.(ID)] 三種資料篩選的方式,dplyr包、base基礎包、data.table包。其中,dplyr是select語句,data.table中要注意.()的表達方式。
而且,.()格式只在data.table格式下有效,不然會報錯。data.table中,還有一個比較特立獨行的函式:
DT[, c("V1","V2") := list(round(exp(V1),2), LETTERS[4:6])]
DT[, c("V1","V2") := NULL]通過list的方式來更新了資料,以及使用null的方式來刪除列。
2、按條件行篩選
從前用subset的方式進行篩選比較多,
new<-subset(x,a>=14,select=a:f)(1)單變數
現在data.table與dplyr
from_dplyr = filter(hospital_spending,State %in% c('CA','MA',"TX"))
from_data_table = hospital_spending_DT[State %in% c('CA','MA',"TX")]dplyr用filter,content滿足某種條件的進行篩選,而data.table的篩選方式很傳統,比較簡單。篩選hospital_spending_DT資料集中,State變數,滿足"CA"、“MA”、"TX"內容的行。
在篩選列變數的資料,也可以與%in%集合運算聯用(集合運算見部落格:R語言︱集合運算)。
(2)多變數篩選,用&|等
from_dplyr = filter(tb,State=='CA' & Claim.Type!="Hospice")
from_data_table = hospital_spending_DT[State=='CA' & Claim.Type!="Hospice"](3)還有一些複雜結構:
dt[a=='B' & c2>3, b:=100] #其他結構在dt資料集中,篩選a變數等於"B",c2變數大於3,同時將新增b變數,數值等於100.
(4)★key的改造
通過預先設定key,然後再來進行篩選的方法,更加高效,而且節省時間。來看看例子:
ans1 <- try[try$gender=="M" & try$buy_online=="Y",]
#使用”==”操作符,那麼它會掃描整個陣列,雖然data.table用這種方法也可以提取,但很慢,要儘量避免。
setkey(try,gender,buy_online) #設定key為兩個變數,資料已經按照x值進行了重新排序
ans2 <- DT[list("M","Y")] #更為簡潔,並且迅速這裡先設定key,然後直接通過list(M,Y)就可以達到第一條程式碼的效能,而且時間更短。
——————————————————————————————————————————————
三、資料排序
有了key,其實有了一定排序功能在裡面。
from_dplyr = arrange(hospital_spending, State)
from_data_table = setorder(hospital_spending_DT, State)
from_dplyr = arrange(hospital_spending, desc(State))
from_data_table = setorder(hospital_spending_DT, -State)dplyr的降序是,arrange(data,desc(x)),而data.table的降序是setorder(data,-x)
——————————————————————————————————————————————
四、分組求和、求平均
mygroup= group_by(try,gender,buy_online)
from_dplyr<-summarize(mygroup,mean=mean(new_car)) #dplyr用兩步
from_data_table<-try[,.(mean=mean(new_car)),by=.(gender,buy_online)] #data.table用一步data.table,在try資料集中,通過by=.(x,y)來分組,而且可以設定x/y兩種分組,來求new_car的平均值。
(1)data.table多種方式混合輸出:
mydata[,.(sum(Ozone,na.rm=T),sd(Ozone,na.rm=T))] #求和、求標準差操作
DT[,list(MySum=sum(v),
MyMin=min(v),
MyMax=max(v)),
by=.(x)] #多種方式聯合
(2)dplyr函式利用%>%(鏈式操作)來改進:
鏈式操作是啥意思呢?
%>%的功能是用於實現將一個函式的輸出傳遞給下一個函式的第一個引數。注意這裡的,傳遞給下一個函式的第一個引數,然後就不用寫第一個引數了。在dplyr分組求和的過程中,還是挺有用的。
from_dplyr=try %>% group_by(gender,buy_online) %>% summarize(mean=mean(new_car))——————————————————————————————————————————————
五、資料合併
最常見的合併函式就是merge,還有sql的方式(常見的合併方式可見:
)。在data.table中有三類資料合併的方式:
1、直接用[]
data_one[data_two,nomatch=NA,mult="all"]以第一個資料為基準,依據key進行合併,只出現重複部分(data_one資料必須設定key,data_two預設第一行為Key)。很簡潔的方式,舉例:
DT = data.table(x=rep(c("a","b","c"),each=3), y=c(1,3,6), v=1:9)
X = data.table(c("b","c"),foo=c(4,2))
#以DT為基準
setkey(DT,x)
DT[X]
#以X資料集為基準
setkey(X,V1)
X[DT]現在有DT、X兩個資料集,先設定DT資料集的key,然後DT[X]來合併,後者相同。還有nomatch的設定可以見第六小節。
nomatch用來設定未匹配到的資料如何處理,nomatch=0則認為未匹配到的刪除。
melt用來設定是否都顯示匹配內容。
2、on=""方式
DT[X, on="x"]這裡的on指的是DT變數中的變數名稱,X還是按照key,如果沒設定就會預設第一行為key。
3、第三種方式:key-merge
setkey(DT,x)
setkey(X,V1)
merge(DT, X)預先設定兩個資料集的key後,也可以用比較常見的merge函式來進行資料合併。
——————————————————————————————————————————————
1、mult引數
mult引數是用來控制i匹配到的哪一行的返回結果預設情況下會返回該分組的所有元素
返回匹配到鍵值所在列(V2列)所有行中的第一行
> DT["A", mult ="first"]
V1 V2 V3 V4
1: 1 A -1.1727 12、nomatch引數——未匹配樣本處理
nomatch引數用於控制,當在i中沒有到匹配資料的返回結果,預設為NA,也能設定為0。0意味著對於沒有匹配到的行將不會返回。
返回匹配到鍵值所在列(V2列)所有包含變數值A或D的所有行:
DT[c("A","D"), nomatch = 0]
V1 V2 V3 V4
1: 1 A -1.1727 1
2: 2 A 0.6651 4
3: 1 A -1.0604 7
4: 2 A -0.3825 10nomatch=0對於沒有匹配到的將不顯示。跟merge中的all差不多。
3、.SD和.SDcols
> DT[, lapply(.SD,sum), by=V2,
+ .SDcols = c("V3","V4")]
V2 V3 V4
1: A -1.2727 22
2: B -1.2727 26
3: C -1.2727 30.SDcols常於.SD用在一起,他可以指定.SD中所包含的列,也就是對.SD取子集。
4、修改列名、行名
#把名字為"old"的列,設定為"new"
> setnames(DT,"old","new")
#把"V2","V3"列,設定為"V2.rating","V3.DataCamp"
> setnames(DT,c("V2","V3"),c("V2.rating","V3.DataCamp")) 5、setcolorder()
#setcolorder()可以用來修改列的順序。
setcolorder(DT,c("V2","V1","V4","V3"))
#這段程式碼會使得列的順序變成:
"V2" "V1" "V4" "V3"
——————————————————————————————————————————————
實戰一:在data.table如何選中列,如何迴圈提取、操作data.table中的列?
在data.table行操作跟data.frame很像,可以data[1,]就可以獲得第一行的資料,同時也可以用,data[1]來獲得行資訊,這個是data.table特有的。
除了行,就是列的問題了。在data.table操作列,真的是費勁。。。
常規來看,
data[,.(x)] 還有 data$x
如果有很多名字很長的指標,data.table中如果按列進行遍歷呢?
data[,1]是不行的,選中列的方式是用列名。於是只能藉助get+names的組合。
for (i in 1:5){
data[,.(get(names(data)[i]))]
}2016-11-28補充:
留言區大神給了一個比較好的選中列的方式,其中主要就是對with的使用:
data.table取列時,可以用data[,1,with=FALSE]取data的第一列,相對於對資料框的操作這樣就可以像普通的資料框一樣使用,謝謝留言區大神!!!!
參考文獻:
些許案例,程式碼參考自以下部落格,感謝你們的辛勤:
4、R高效資料處理包dplyr和data.table,你選哪個?