
簡單比較 BeautifulSoup 和 Xpath 的效能
阿新 • • 發佈:2019-01-08
一些說明
我為什麼要寫這篇文章?
其實這篇文章並不是為了比較出結論,因為結論是顯而易見的,Xpath 必然 是要比 BeautifulSoup 在時間和空間上都要效能更好一些。其中理由有很多,其中一個很明顯的是 BeautifulSoup 在構建一個物件的時候需要傳入一個引數以指定解析器,而在它支援的眾多的解析器中,lxml 是效能最佳的,那麼 BeautifulSoup 物件的各種方法可以理解為是對 lxml 的封裝,換句話說,BeautifulSoup 本質上並沒有創造出自己的解析方式,而是建立在各種解析器的基礎上。考慮到其他一些內部耗時因素,BeautifulSoup 註定會比 lxml 甚至是任何一個構建物件時使用的解析器要慢,要更耗費空間。只有付出這樣子的代價才能夠換來它的簡潔、優美與使用者友好性。
那麼,本文其實是通過一個爬蟲例子來簡單的驗證一下這個結論,以及對它們之間的差距有一個數量上的認識。
測試例子
# test.py
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup, SoupStrainer
import traceback
import json
from lxml import etree
import re
import time
def getHtmlText(url):
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
if r.encoding == 'ISO-8859-1' - 執行截圖
html.parser

lxml
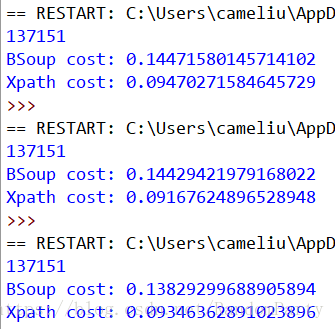
結果分析
可以看到,當我們使用 html.parser 作為解析器時,BeautifulSoup 解析的耗時平均是 Xpath 的 1.8 倍+;當我們使用 lxml 作為解析器時,BeautifulSoup 解析的耗時雖有減少,但平均仍是 Xpath 的 1.5 倍+。
最後
BeautifulSoup 這碗美味湯確實是美味可口,但是一碗好湯煲制時間和用料上面都更加花費,這無可厚非。Xpath 相對來說可能語義性沒有前者強,但總體也是 user-friendly,也很好用,功能十分強大,最重要的是它的爸爸 lxml 使用 C 編寫的,速度自然就不必說了,如果在很追求效率和資源節約的情況下,熟練運用 Xpath 會使你感到無盡的愉悅。