
Kafka 2.0 升級,看看攜程怎麼操作!
早在 2014 年,攜程的一些業務部門開始引入 Kafka 作為業務日誌的收集處理系統。2015 年,基於 Kafka 的高併發、大資料的特點,攜程框架研發部在 Kafka 之上設計了 Hermes Kafka 訊息系統,作為大規模的訊息場景的統一的中介軟體。隨著業務量的迅速增加,以及具體業務、系統運維上的一些誤用,Kafka 現有系統變得不穩定,經歷了多次 down 機,故障期間完全不可用,持續時間長達 5 小時以上,恢復緩慢。Kafka 還能用多久?成為一個迫切棘手的問題。問題嚴重又難以解決,必須做出改變。
筆者在攜程框架研發部任職,2018 年 5 月起負責 Kafka 訊息系統。重點解決 Kafka 運維使用中的關鍵問題,建設 Kafka 訊息系統應用架構體系。本文分享攜程的 Kafka 應用實踐。
Kafka 0.9.0 => 2.0 升級之旅
升級的緊迫性
2016 年初,攜程 Kafka 升級到了 0.9.0 這一里程碑式的版本。在這個版本里,客戶端去除了 zookeeper 依賴,大大提升了系統穩定性。自此以後,到 2018 年 5 月,Kafka 經歷了 0.10.x,0.11.x,1.x,1.1 4 個大版本。0.9.0 之上的運維工具,如 Kafka Manager、Kafka Offset Monitor、exhibitor 等,要麼停止維護,要麼不再有新的功能更新。對於運維中暴露出來的問題,缺少解決方案。
-
訊息傳送非同步變同步: producer 內部使用了一個記憶體池,訊息進來從池上分配 1 塊記憶體,訊息傳送後回收。一旦 broker 負載過重,寫磁碟慢,producer 的記憶體池消耗快,回收慢,就會使客戶端的非同步的訊息傳送變成同步堵塞,嚴重影響使用者的業務。
-
broker 程序 crash 後無法啟動: 程序有時會 crash。由於沒有優雅關閉,一些磁碟資料會毀壞,導致無法再次啟動。必須手工刪除毀壞的資料才能啟動。
-
broker under replicated:發現 broker 處於 under replicated 狀態,但不確定問題的產生原因,難以解決。(其實是 broker 過載,但難以排查是哪些 topic 導致,應遷移哪些 topic 的資料)
-
單副本:為緩解 under replicated 問題,採用了一個犧牲可靠性的辦法,topic 從多副本變為單副本。但又引發了新的問題,broker 重啟、crash,都會導致訊息丟失,broker 硬體故障,更會導致 broker 相關的 topic 長期無法使用。
-
缺少歷史監控:Kafka Manager 只提供執行時的指標,無歷史指標,出問題後,難以分析事故原因。
-
監控指標不完善:如 topic、partition、broker 的資料 size 指標。
-
資料遷移困難:topic 一般在多個 broker 上,當某個 broker 負載重時,需要把這個 broker 上的某個(某幾個)topic 的分割槽遷移到其它 broker。無 UI 工具可用,需要到 broker 機器上執行指令碼。費力度高,低效。也缺少把 1 個 broker 上的資料整體遷移到新的 broker 上的能力。
-
broker 負載不均衡:有的 broker 負載重,有的負載輕。無法自動調配。有新的工具(如 cruise-control),但由於 Kafka 版本低,無法使用。
-
新的 feature 無法使用:如事務訊息、冪等訊息、訊息時間戳、訊息查詢等。
升級方案
Kafka 官網上明確說明高版本相容低版本,可以從低版本透明升級。鑑於 Kafka 叢集資料量大,broker 數目多,升級失敗後的影響大,決定從小到大,分批次灰度升級。
-
測試環境升級:2 個 3 節點小叢集,分 2 批次進行,持續 1 周,執行正常。
-
生產小叢集升級:13 臺機器,分 2 批次(5 臺,8 臺)進行,持續 1 周,執行正常。
-
生產大叢集升級:63 臺機器,分 5 批次進行(5 臺,8 臺,10 臺,13 臺,27 臺),持續 3 周,執行正常。
從調研、測試到實施完成,8 月下旬到九月底,共 6 周時間,從 0.9.0 直升 2.0。升級步驟完全按照官方規範進行,感謝 Kafka 產品的優秀的相容性。
踩到的坑
共踩到 2 個坑,都在測試環境發現。
-
kafka-server-stop.sh 指令碼失效問題:2.0 改變了 -cp 的格式,從 lib/* 變成了 /lib/xx.jar:…,由於依賴項很多,導致命令列非常長。在 centos 7.3 上,ps 命令可以正常顯示,但在 centos 6.4 和 7.1 上,會被截斷,導致 grep 無法抓取到末尾的 kafka.Kafka 特徵,無法定位程序。通過修改指令碼解決問題。
-
單副本 partition 全部 offline(leader 為 -1)):2.0 改變了配置 unclean.leader.election.enable 的預設值(從 true 變為 false),多副本時,無影響。由於 2.0 與 0.9.0 的 leader 選舉的處理機制不同,升級過程中,同時存在 2.0 與 0.9.0 的 broker,對於單副本的 partition,isr 會被清空(leader 為 -1)且無法恢復。通過在 server.properties 里加入配置 unclean.leader.election.enable=true 解決。全部 broker 升級完成後,此項配置可以去除。這是一個嚴重的不相容變更,如果在生產環境發現,會導致嚴重事故。
另外,官方文件裡特別說明了應保持資料格式為 0.9.0,不要使用 2.0 格式,以免資料格式轉換導致 broker cpu 利用率過高。需在 server.perperties 里加入配置:log.message.format.version=0.9.0。
常見問題的解決
-
broker 程序 crash 後無法啟動: 升級後未再遇到此問題。並且重啟(stop/start)速度更快,部分負載重的機器,升級前重啟一次要花 10 分鐘左右,升級後重啟一般在 3 分鐘以內完成。
-
broker under replicated:升級後可通過後文中的監控方案快速定位到流量大的 topic,遷移流量大的 topic 資料到空閒 broker,可快速降低負載。
-
單副本:由於升級後容易定位和解決 under replicated 問題,單副本再無必要,可恢復為正常的多副本。
-
缺少歷史監控:升級後通過後文中的監控方案解決。
-
監控指標不完善:2.0 有豐富的監控指標。如關鍵的 Size 指標。
-
資料遷移困難:2.0 提供了 Admin Client。基於 Admin Client 和 Kafka Core,自研了 ops service,能方便地進行日常的 topic/partition/broker 資料遷移運維。如降低機器負載(把 1 個 broker 上部分 topic 資料遷移到其它 broker)、下線舊機器(把 1 個 broker 上的全部資料遷移到其它 broker)等。
-
broker 負載不均衡:新的自動 rebalance 開源工具 cruise-control(https://github.com/linkedin/cruise-control)。
-
新的 feature:事務訊息、冪等訊息、訊息時間戳、訊息查詢(KSQL)等。
-
訊息傳送非同步變同步:客戶端比較分散,短期難以統一升級。但可通過後文中的服務端多叢集架構改善 broker 負載,避免此問題。
基於 Prometheus 和 Grafana 的 Kafka 叢集監控方案
Kafka 監控現狀
0.9.0 時,broker 端主要使用 kafka-manager 作為監控工具,能看到實時的 metrics,並做了一些聚合。但資料不落地,無法進行歷史資料回放。同時缺少 size 指標,無法檢視 topic、partition、broker 的資料量情況。其它的工具如 Kafka Offset Monitor 和 trifecta,在資料量大時查詢緩慢,基本不可用。
新的運維工具(如 cruise-control、KSQL 等),無法在 0.9.0 上使用。
Kafka JMX Metrics
Kafka broker 的內部指標都以 JMX Metrics 的形式暴露給外部。2.0 提供了豐富的監控指標,完全滿足監控需要。後文中的監控截圖裡有常見的監控指標,完全的指標列表可通過 JConsole 檢視 Kafka 的 MBeans。
可用的開源元件
-
Prometheus:Prometheus 是一個雲原生的 metrics 時間序列資料庫,具備 metrics 採集、查詢、告警能力。筆者今年 3 月接觸到,非常喜愛。
-
Grafana: metrics 視覺化系統。可對接多種 metrics 資料來源。
-
JMX Exporter:把 JMX metrics 匯出為 Promethues 格式。https://github.com/prometheus/jmx_exporter
-
Kafka Exporter:匯聚常見的 Kafka metrics,匯出為 Prometheus 格式。https://github.com/danielqsj/kafka_exporter
監控方案
-
JMX Exporter:部署到每臺 broker 上。
-
Kafka Exporter:部署到任意 1 臺 broker 上。
-
Prometheus:部署到 1 臺獨立機器上,採集 JMX Exporter 和 Kafka Exporter 上的資料。
-
Grafana:部署到 1 臺獨立機器上,視覺化 Prometheus Kafka metrics 資料。對於 cluster、broker、topic、consumer 4 個角色,分別製作了 dashboard。
監控截圖示例
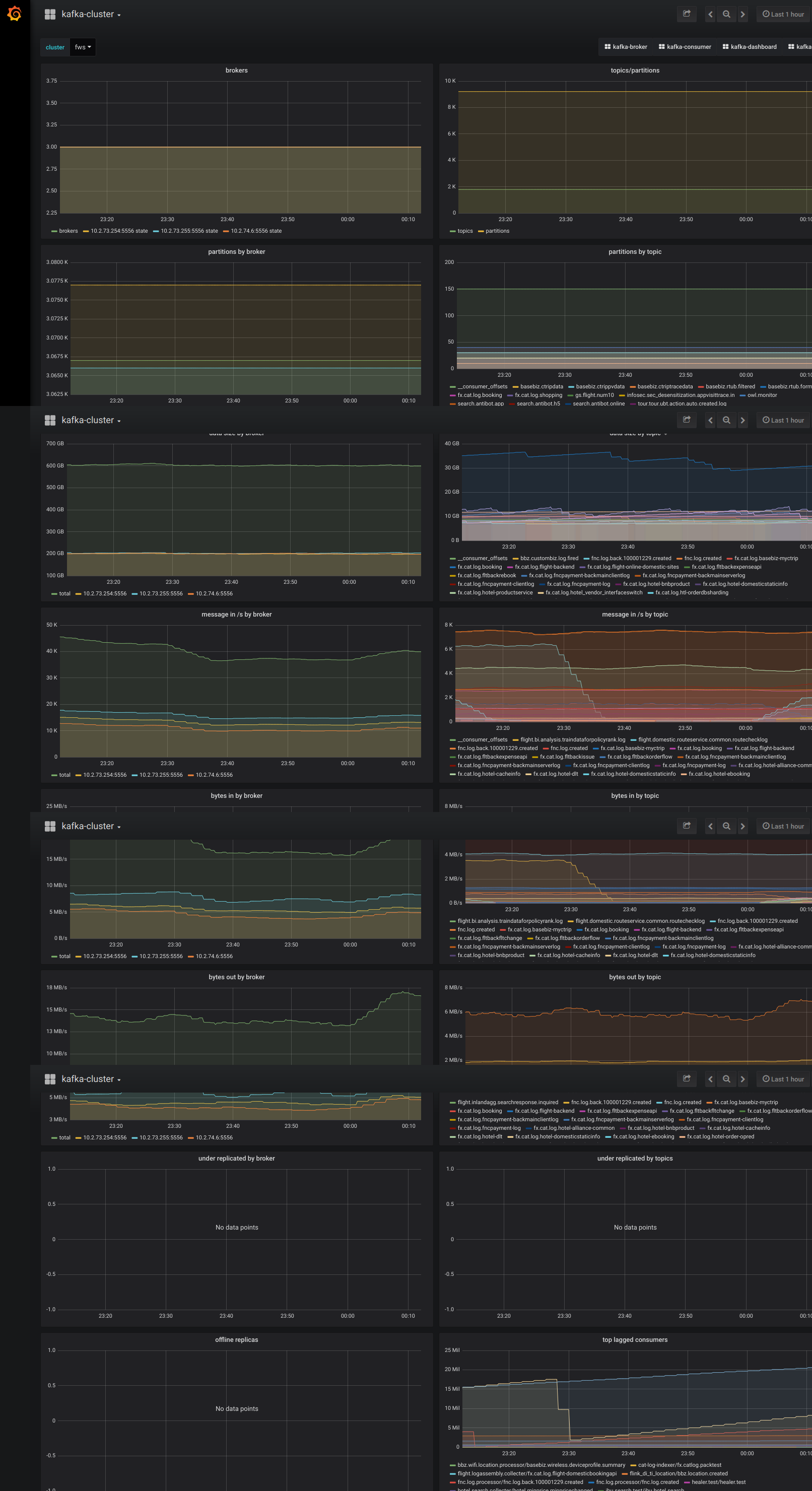
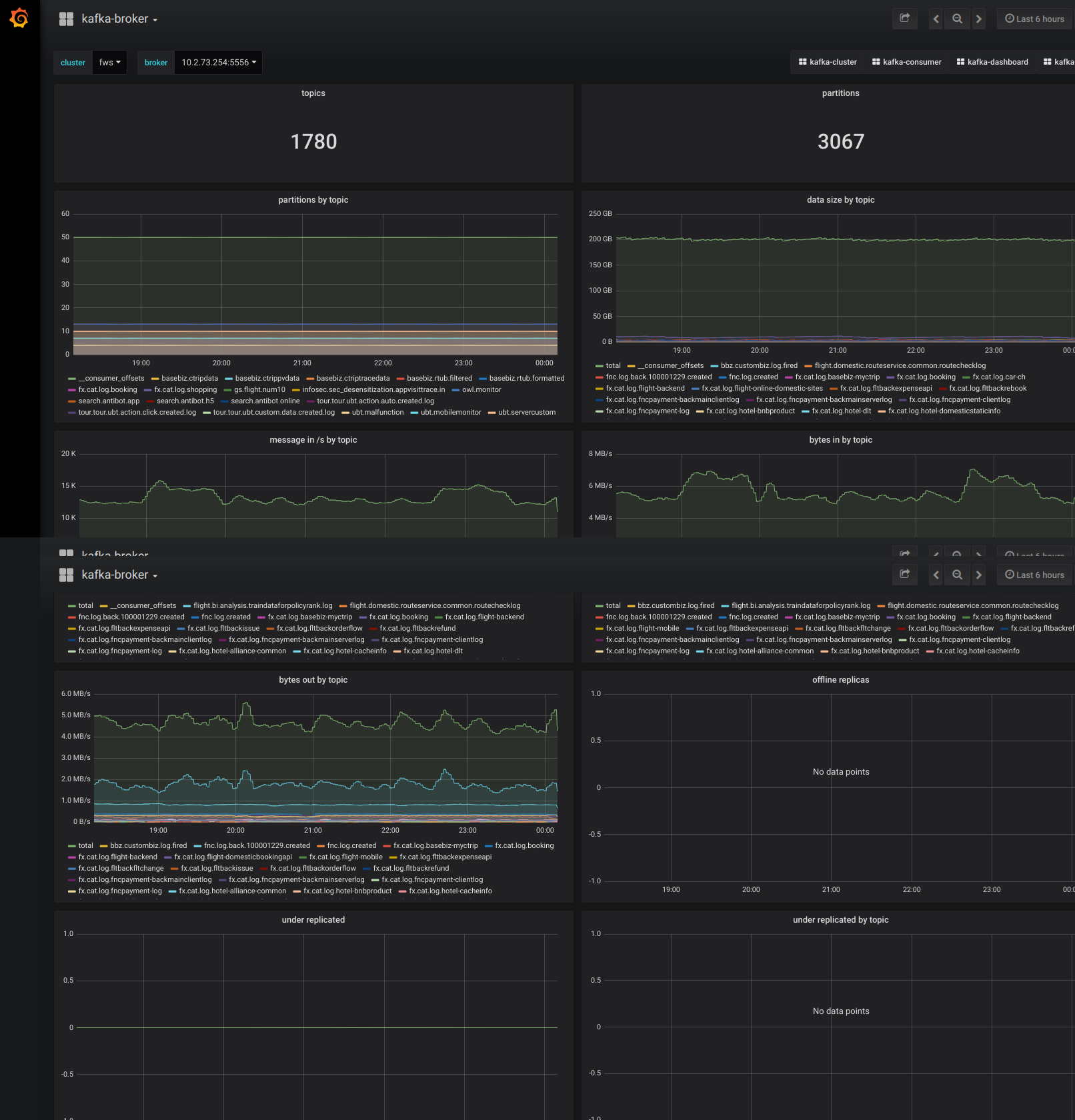
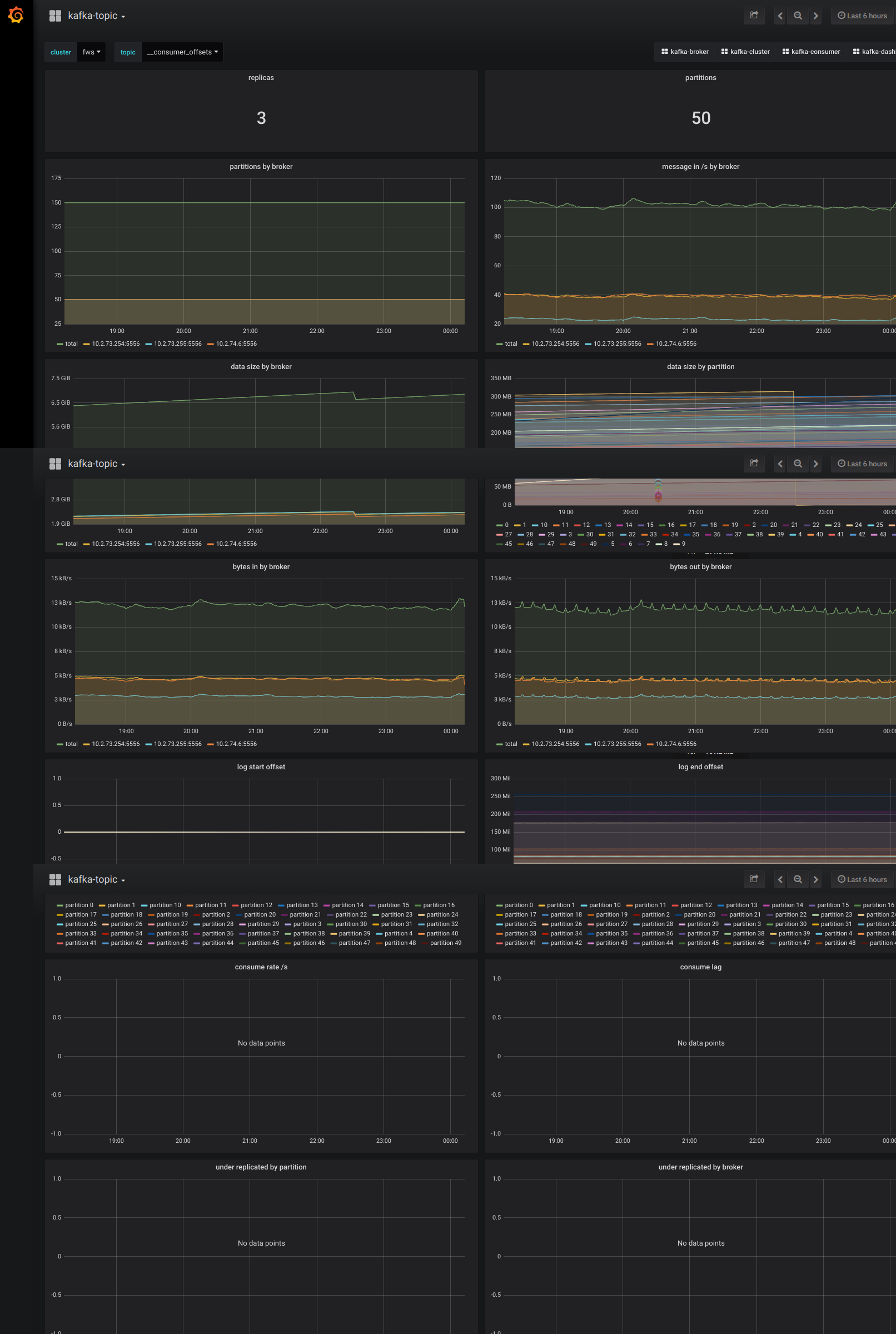
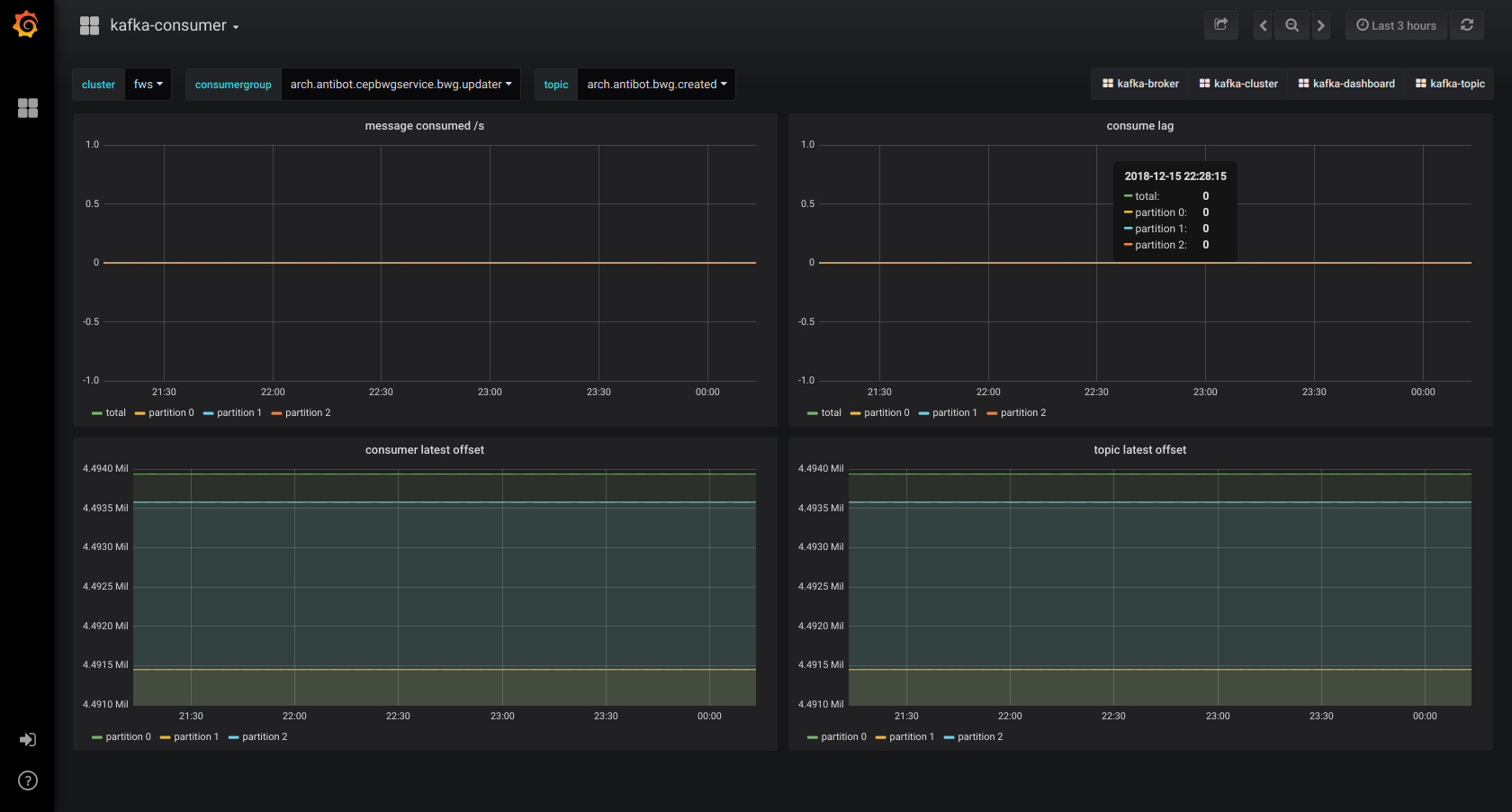
Kafka 多叢集解決方案
為什麼要多叢集
15 年,生產只搭建了 1 個叢集,不到 10 個節點,但隨著業務的大量接入和某些業務的不合理使用,以及駕馭能力不足(有問題加機器),生產叢集擴大到 63 個節點。全公司業務混雜在一起,部分業務資料量極大。1 個 topic 資料量激增,或某個 broker 負載過重,都會影響到多個不相干業務。甚至某些 broker 的故障導致整個叢集,全公司業務不可用。叢集節點數目過大,也導致運維、升級過程漫長,風險極大。
迫切需要從多個不同維度把大叢集分拆為小叢集,進行業務隔離和降低運維複雜度。
多叢集架構
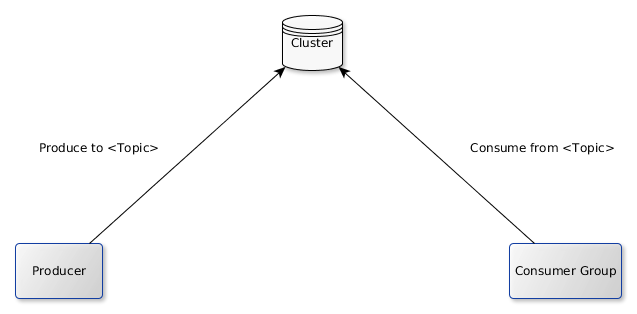
原生的單叢集架構
引入 1 個 meta service,改造為多叢集架構
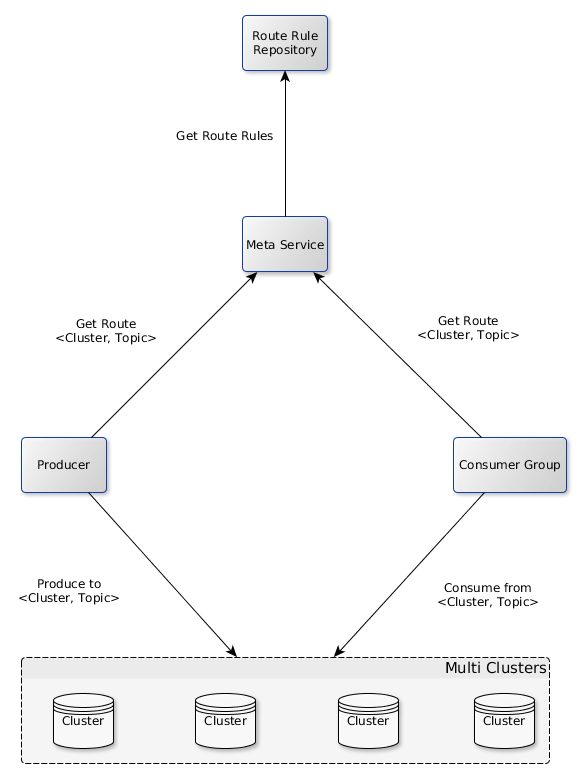
同時仍然提供統一的 client 給使用者,封裝多叢集相關的配置(如哪個 topic 在哪個叢集上),使用者仍然以原生的單叢集的方式使用。可以通過調整路由規則,動態地把 topic 從 1 個叢集遷移到另一個叢集,對使用者透明。
多叢集路由
單機群模式下,只需要 topic 便可進行訊息的生產、消費。多叢集模式下,需要知道 1 個 <cluster, topic> 二元組。客戶端、topic、consuemer 的元資料,構成了影響路由的因子。根據這些路由因子,可靈活制定路由規則。
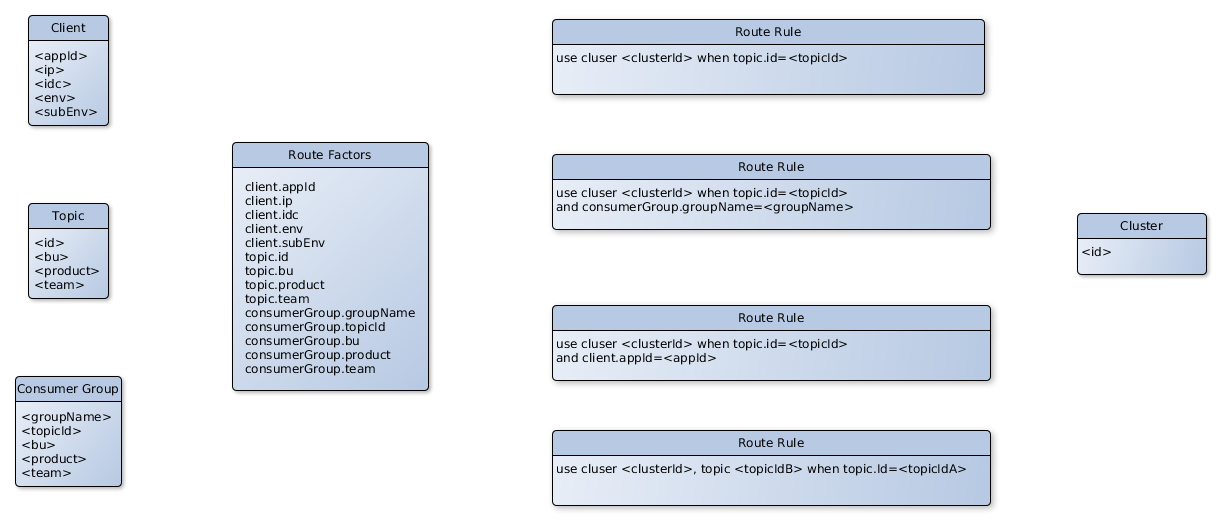
定址過程
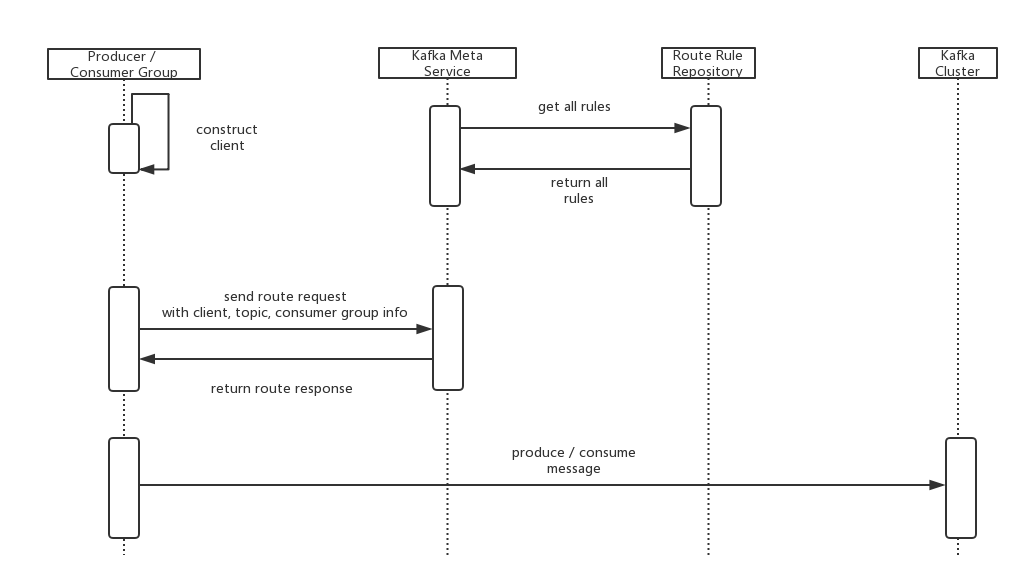
當路由規則變化時,client 可以近實時地感知到 (2 分鐘左右),自動重啟使路由規則生效。
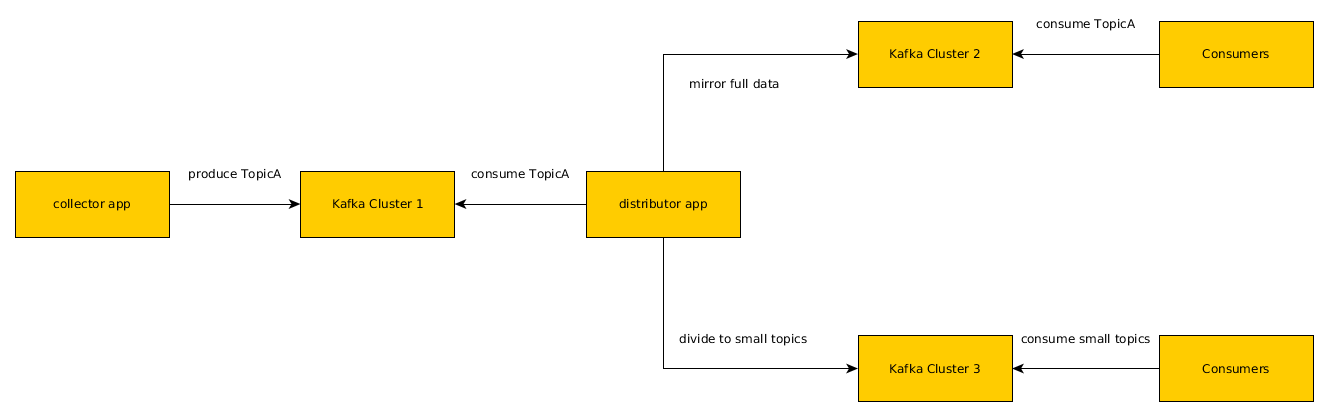
實際案例
攜程量最大的 topic,流量峰值入口 250m/s,出口 8g/s。出口流量遠大於入口流量,寫少讀多。入口流量穩定,但出口流量經常飆升(消費者增加)。出口流量飆升,導致磁碟利用率升高,反過來大幅降低寫入速度,使訊息生產非同步變同步,嚴重影響業務。由於業務設計不合理,只消費部分資料的使用者,必須消費全量資料,需要把原始的 topic 資料進行處理,分拆為專用的 topic 以減少無效消費。
基於多叢集架構,從 1 個叢集變為讀寫分離的 3 個叢集,降低資料寫入的風險,減少無效消費。2 周左右實施完成。對消費者透明。
企業級 Kafka 應用架構
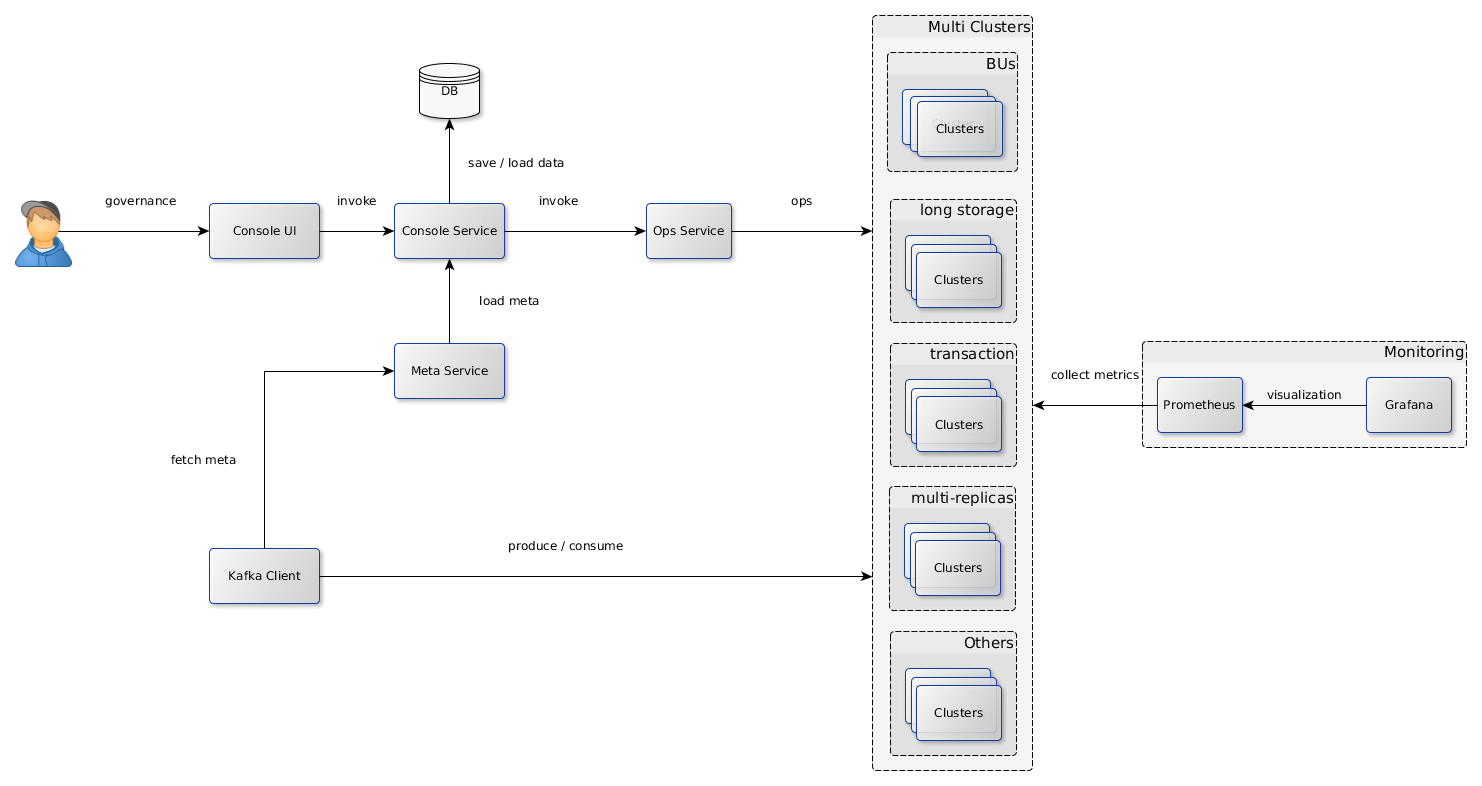
Kafka 原生的叢集模式使用簡單,能滿足少量業務的需要。但對於大型企業(網站),大量的業務使用 Kafka,資料量、流量極大,必然同時存在多個叢集,需要對使用者的接入、執行時監控、叢集運維提供統一的解決方案。下圖是攜程正在研發的解決方案,部分架構元素已開發完成並投產。將來會開源出來,回饋社群。
說明
-
Console UI/Service:面向使用者。用於 topic/consumer/cluster 註冊、配置管理、叢集運維的統一的治理系統。資料落地到 DB 持久儲存。待開發。
-
Meta Service:面向 client(producer/consumer)。從 console service 載入元資料資訊(路由規則等),供 client 定址用。已投產。
-
Ops Service:基於 Kafka admin client 和 Kafka core,把運維服務化,降低運維複雜度。已開發基本功能,待投產。
-
Kafka Clusters:按多個維度搭建的多個叢集。可靈活搭建和運維變更。
-
Monitoring (Prometheus + Grafana):叢集監控解決方案。已投產。